

Vibe coding 很爽,直到项目变成屎山代码。
用 AI 写代码就像开了挂一个 prompt 就能生成几百行,功能跑得通,成就感拉满。但当项目从 demo 演到几万行、十几个模块时,问题开始暴露:改了一处,牵出三处 bug ;加了一个功能,不知道会影响哪里; AI 每次进项目都要从头读一堆文件,上下文越堆越乱。
这背后其实是一个老问题:没有文档。
程序员自古自嘲「屎山代码」,本质上就是前人没留文档,后人只能在垃圾山里考古。讽刺的是,每个人写代码时都不爱写文档,接手别人项目时又疯狂骂娘。文档一直是件费时费力的苦差事人写,人忘,人懒。
但现在,写文档这件事可以交给 AI 。
不是让人写好了给 AI 看,而是让 AI 自己维护文档:代码怎么变,文档就怎么更新。你的 Agent 每次进入项目,3 步就能摸清全局;每次提交代码,系统自动检查文档是否同步更新。文档不再是拖后腿的负担,而是 AI 协作的基础设施。
这套机制的核心就两点:
- 分形文档 + Prompt 约束 L1/L2/L3 分形结构让 Agent 快速建立上下文,规则写进根文档形成自我约束
- Git Hook 强制校验 提交时自动检查,代码和文档不同步就直接阻断,逼着 Agent 更新完再提交
一、分形文档系统
核心思路
文档按层级组织,像分形一样:每一层只描述自己直接管辖的内容,不过度展开。
L1: 根目录 CLAUDE.md ← 全局架构、规则、目录地图 L2: 子目录 CLAUDE.md ← 该模块的职责、文件清单、导出、依赖 L3: 文件头注释(可选) ← 仅用于逻辑复杂、不直观的文件 AI 从任意文件出发,最多 3 次 Read 即可到达完整上下文:
文件对不变式( File Pair Invariant )
每个有文档的目录,必须同时存在两个文件:
CLAUDE.md ← 唯一的编辑源,内容在这里 AGENTS.md ← CLAUDE.md 的符号链接( symlink ),内容完全一致 什么是 symlink (符号链接)?
Symlink 是操作系统提供的一种特殊文件,它本身不包含实际内容,而是指向另一个文件的路径。可以理解为快捷方式打开 symlink ,实际访问的是它指向的那个文件。编辑源文件,symlink 的内容也会同步变化。
为什么要用 symlink ? 不同 AI 工具读取的入口文件名不同:
用 symlink 而不是两个独立文件,确保永远不会出现内容不一致的情况。
创建 symlink 命令
# 在目录内执行(相对路径) ln -s "CLAUDE.md" "AGENTS.md" # 验证 ls -la AGENTS.md # 应显示 AGENTS.md -> CLAUDE.md L1 文档(根目录 CLAUDE.md )
放在项目根目录,内容包括:
- 项目简介 + 技术栈
- 开发命令( dev/build/test/db migration 等)
- 整体目录结构图(深度 2 层即可)
- 关键架构模式(数据库连接方式、认证流程、权限系统等)
- 文档系统本身的规则(何时创建 L2 、Loop-back Check )
模板
# [项目名] ## 技术栈 Next.js 15 React 19 TypeScript Drizzle ORM ... ## 开发命令 pnpm dev / pnpm build / pnpm db:generate ... ## 目录结构 src/ ├── app/ # Next.js App Router ├── config/ # 配置、数据库 schema 、i18n ├── core/ # 框架核心模块 ├── extensions/ # 可插拔扩展( AI/支付/存储) ├── shared/ # 共享组件、hooks 、工具函数 └── themes/ # 主题实现 ## 架构模式 [关键模式说明...] ## 分形文档系统规则 [见下文] L2 文档(子目录 CLAUDE.md )
每个 L2 文档控制在 ≤ 80 行,固定四节:
# [模块名] > 本目录文件有变动时,请同步更新此文档。 ## Purpose 这个目录的职责是什么 ## File Inventory | 文件/目录 | 用途 | | ------------ | --------------------------- | | `foo.ts` | 做什么 | | `bar/` | 子模块,做什么 | ## Key Exports - `SomeClass` 描述 - `someFunction(arg)` 描述 ## Dependencies - Depends on: `src/core/db`, `src/config` - Depended on by: `src/app/api/*` 何时创建 L2 文档
满足以下任意一条,就应该创建:
- 是顶层或核心模块目录( src/app 、src/core 、src/config 等)
- 直接子项有 4 个以上
- 是清晰的模块边界或高频维护入口
- 父文档无法在 3 次 Read 内解释清楚
以下条件全部满足时,不需要创建:
- 只有 1-3 个文件
- 是叶子级实现细节
- 父文档已能充分描述
L3 文档(文件头注释)
只在逻辑复杂、非直观的文件顶部加注释。普通文件不需要,不要滥用。
必须写的情况:
- 有非直观约束(如"不能并发调用"、"依赖全局状态")
- 有隐晦副作用
- 是跨模块枢纽,需要说明上下游关系
- 算法复杂、实现不直观
不需要写的情况:
- 纯工具函数( input/output 可从签名推断)
- 文件名已自解释的 CRUD
注释格式(三段式 + 约束):
// input: 依赖外部的什么(模块、表、环境变量等) // output: 对外提供什么(函数、类、接口) // pos: 在系统局部的地位(被谁调用、枢纽作用) // 约束:关键陷阱、非直观行为、竞态条件等 三段式让 AI 秒懂文件坐标,约束行标注需要特别注意的坑。L3 注释本身就是优先级信号有注释 = AI 需提升注意力。
二、文档维护规则:Loop-back Check
每次完成任务后(不管是修改代码还是加功能),强制执行以下检查:
| 步骤 | 触发条件 | 操作 |
|---|---|---|
| L2 sync | 增删改了任何文件 | 更新该目录的 CLAUDE.md 文件清单 |
| 新目录 | 创建了新目录 | 同时创建 CLAUDE.md + AGENTS.md symlink |
| 目录删除/重命名 | 删除/重命名了目录 | 修复或删除对应 symlink |
| L3 consideration | 大幅修改了复杂文件 | 更新/添加文件头注释 |
| L1 flag | 新增顶级目录或扩展类别 | 更新根 CLAUDE.md 目录地图 |
这个规则写在根 CLAUDE.md 里,让 AI 每次都能看到,形成自我强化的闭环。
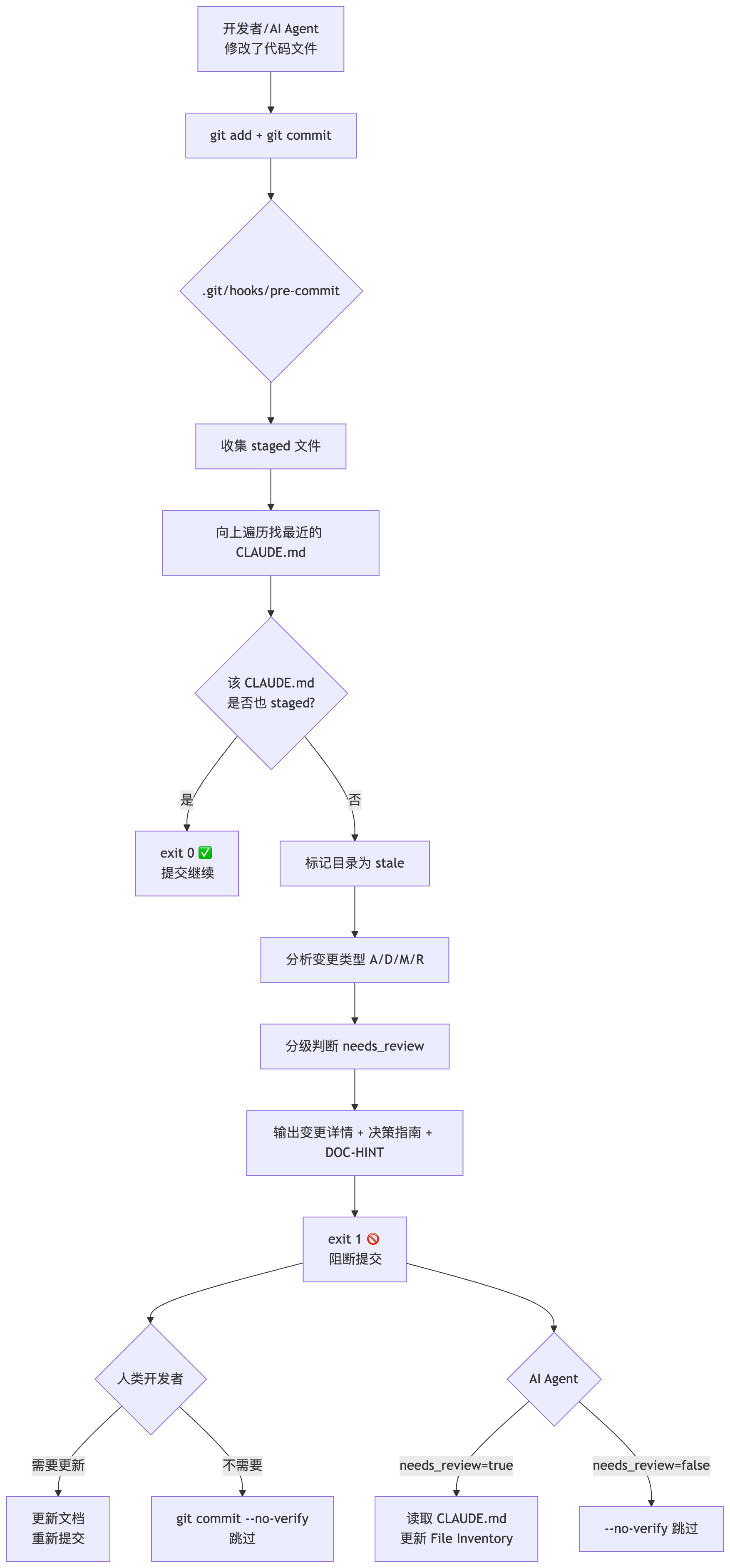
三、Pre-commit Hook 防护机制
什么是 pre-commit hook ?
它是 Git 提供的一个钩子脚本,在你执行 git commit 时自动触发。如果脚本返回非 0 (失败),提交就会被阻断。常见用途包括:自动格式化代码、跑单元测试、检查代码规范以及我们这里做的,检查文档是否同步更新。
文档规则写得再清楚,AI 也可能在某次任务中漏掉。
Pre-commit Hook 提供 提交时的最后防线。
Hook 文件位置
.git/hooks/ └── pre-commit 核心逻辑
1. 收集所有 staged 文件( git diff --cached --name-only --diff-filter=ACMRD ) 2. 过滤出其中已 staged 的 CLAUDE.md (说明开发者已经在更新文档) 3. 对每个非文档的 staged 文件: └─ 向上遍历目录树,找到最近的 CLAUDE.md └─ 如果该 CLAUDE.md 未被同时 staged → 标记目录为 "stale" 4. 对每个 stale 目录: ├─ 分析受影响文件的变更类型( A/D/M/R ) └─ 分级判断 needs_review ( A/D/R → true, M → false ) 5. 输出变更详情 + 决策指南 + 机器可读的 [DOC-HINT] 块 6. exit 1 → 阻断提交,等待用户/Agent 做出选择 关键决策:阻断而非警告。
这个设计不是一开始就确定的,而是经历了两轮迭代:
| 版本 | 策略 | 问题 |
|---|---|---|
| v1 | 警告(exit 2) | 开发者和 AI 都倾向于无脑确认,防线形同虚设 |
| v2 | 强制更新 | 过于粗暴修复一个 typo 或改个变量名也要更新文档,反而增加噪音 |
| v3 | 阻断 + 分级判断 | 卡住提交,但根据变更类型给出明确的「更新 / 跳过」建议 |
当前采用两阶段处理:
- 阻断阶段:提交时检测到 stale 文档,直接
exit 1卡住。不给"警告后自动放行"的漏洞,也不一刀切强制更新。 - 判断阶段:根据 A/D/M/R 变更类型自主决策存在 A/D/R (增删重命名)→
needs_review=true,建议更新;只有 M (修改内容)→ 若确认不影响接口/导出,可用--no-verify跳过。
--no-verify 始终可用,不会卡住任何工作流。这种设计把选择权还给人和 AI ,同时用阻断确保选择是被有意识做出的。
变更类型分级
Hook 输出每个受影响文件的变更类型,帮助快速判断是否真的需要更新文档:
| 类型 | 含义 | 建议 |
|---|---|---|
| A (Added) | 新增文件 | 更新 File Inventory 需要加入新条目 |
| D (Deleted) | 删除文件 | 更新 移除已不存在的条目 |
| R (Renamed) | 重命名 | 更新 文件路径变了 |
| M (Modified) | 修改内容 | 仅当接口/导出变化时需要更新 |
这个分级引出一个自动化判断规则:**存在 A/D/R 变更 → needs_review=true**。
但 A/D/M/R 只是变更类型,不是更新决策。人在面对 hook 阻断时,还需要知道「什么情况下必须更新、什么情况下可以跳过」。完整的决策规则如下:
| 必须更新 | 可以跳过 |
|---|---|
| 新增/删除/重命名文件或目录 | Debug 代码、console.log 、临时日志 |
| 修改接口、类型、导出的函数 | 注释或代码格式化( prettier / eslint ) |
| 调整架构或数据流 | 不改动接口的小 bug 修复 |
| 修改配置文件( manifest 、vite 、tsconfig ) | 仅测试文件变更 | 依赖关系发生变化 | 无语义变化的变量重命名 |
[DOC-HINT]:给 AI Agent 的机器可读块
这是整套机制中最有价值的设计演进。
人类看到黄色警告可以凭直觉判断"这次改动要不要更新文档",但 AI Agent 不行它需要结构化信号。Hook 输出末尾附带的 [DOC-HINT] 块解决了这个问题:
[DOC-HINT] stale: src/auth/CLAUDE.md | A=1 D=1 M=1 R=0 | needs_review=true src/utils/CLAUDE.md | A=0 D=0 M=1 R=1 | needs_review=true rules: A=Added → doc update recommended D=Deleted → doc update recommended R=Renamed → doc update recommended M=Modified → usually not needed unless interface/export changed AI Agent 可以解析这个块来自动决策:
needs_review=true→ 读取对应 CLAUDE.md ,根据 A/D/R 变更更新 File Inventoryneeds_review=false(只有 M 变更)→ 可以安全使用--no-verify跳过
[DOC-HINT] 让 hook 不仅是给人看的提醒,更是 AI 工作流中的一个决策节点。 这才是"AI 友好"的真正含义不只是文档结构对 AI 友好,连守护机制的输出也要对 AI 友好。
实际效果示例
$ git add src/auth/oauth.ts src/auth/login.ts src/utils/format.ts $ git commit -m "feat: add OAuth support" These directories have staged changes but their CLAUDE.md is not updated: → src/auth/CLAUDE.md A src/auth/oauth.ts M src/auth/login.ts → src/utils/CLAUDE.md R src/utils/format.ts M src/utils/date.ts Update docs, or skip with: git commit --no-verify -m "message" When to update: A/D/R, interface, architecture, config change When to skip: debug code, formatting, minor fixes, tests, rename [DOC-HINT] stale: src/auth/CLAUDE.md | A=1 D=0 M=1 R=0 | needs_review=true src/utils/CLAUDE.md | A=0 D=0 M=1 R=1 | needs_review=true rules: A=Added → doc update recommended D=Deleted → doc update recommended R=Renamed → doc update recommended M=Modified → usually not needed unless interface/export changed 四、整体架构图
参考与致谢
本文的分形文档思路源自 赵纯想 的实践分享。他在使用 Claude Code 开发 laper 时,总结了一套以「分形」为核心的文档组织方法每个目录自带极简说明,每个文件头声明 input/output/pos ,让 AI 在自相似的结构中快速建立上下文。
我在此基础上做了拓展和工程化:
- 文件对不变式( CLAUDE.md + AGENTS.md symlink )解决多工具兼容
- L3 注释从全量改为可选,配合明确的「必须写/不需要写」判断标准,降低噪音
- Pre-commit Hook 硬阻断 + [DOC-HINT] 把规则从「 AI 自觉」升级为「系统强制」
如果你对原始方案感兴趣,推荐关注赵纯想的分享。
本文的实践和工具链已开源为 Skill ,欢迎试用和反馈:
# 一键安装 npx skills add longranger2/project-doc-bootstrap GitHub: https://github.com/longranger2/project-doc-bootstrap
 | 1 wutong0369 4 天前 先 mark 收藏一下,感谢分享 |