

这是一个创建于 69 天前的主题,其中的信息可能已经有所发展或是发生改变。
https://www.swebench.com/index.html
Claude 4.5 Opus medium (20251101) 测试项目全是 python 项目 解决 500 个 issues
Django 项目
作用: Django 是一个高级的 Python Web 框架,旨在帮助开发者快速构建和部署数据库驱动的 web 应用程序。它遵循 "不要重复自己" (DRY) 原则,并提供了一整套完整的开发工具,包括用户认证、数据库管理、URL 路由等功能。
Astropy 项目
作用: Astropy 是一个用于天文学的 Python 库,它提供了处理天文数据的工具,例如坐标转换、时间计算、天体物理常数、单位转换等,广泛应用于天文学领域的数据分析和建模。
Matplotlib 项目
作用: Matplotlib 是一个 Python 2D 绘图库,用于生成静态、动态和交互式图表。它支持多种图表类型,如线图、散点图、直方图等,广泛应用于数据分析、科学研究和数据可视化。
SymPy 项目
作用: SymPy 是一个 Python 库,用于符号数学计算。它支持代数运算、微积分、方程求解、矩阵运算等。SymPy 提供了符号计算功能,是数学、工程、科学等领域计算的利器。
Flask 项目
作用: Flask 是一个轻量级的 Python Web 框架,非常适合开发简单且灵活的 Web 应用程序。与 Django 相比,Flask 更加简洁并且易于扩展,它允许开发者以自己的方式配置应用,通常用于小型应用或微服务。
Sphinx 项目
作用: Sphinx 是一个用于生成文档的工具,主要用于 Python 项目的文档生成。它支持从源代码中提取注释、自动生成 API 文档,并将其输出为 HTML 、PDF 等格式。Sphinx 广泛用于开源项目的文档管理。
Requests 项目
作用: Requests 是一个非常流行的 Python 库,简化了 HTTP 请求的处理。它提供了简单易用的接口来发送 HTTP 请求(如 GET 、POST 、PUT 、DELETE ),并处理响应。广泛用于 web 爬虫、API 集成等场景。
Xarray 项目
作用: Xarray 是一个 Python 库,用于处理多维数组数据。它在 Pandas 的基础上扩展了支持多维数据的功能,主要应用于气候、遥感和其他需要处理多维数据的科学计算领域。
Pylint 项目
作用: Pylint 是一个 Python 代码静态分析工具,用于检查代码质量和风格。它能够发现潜在的代码错误、编程规范问题、重复代码等,并给出改进建议,帮助提高代码的可读性和可维护性。
Pytest 项目
作用: Pytest 是一个用于 Python 的单元测试框架。它提供了一个简单易用的接口,支持自动化测试、并发测试、断言等功能。Pytest 具有丰富的插件支持和扩展性,是 Python 开发者进行测试的常用工具。
Scikit-learn 项目
作用: Scikit-learn 是一个广泛使用的机器学习库,提供了一整套常见的机器学习算法(如回归、分类、聚类、降维等)以及相关工具(如模型选择、评估指标、数据预处理等)。它广泛应用于数据科学、机器学习项目中。
其他语言
为了确定基准性能,使用多语言数据集评估了 SWE-agent + Claude 3.7 Sonnet 。在成本限制为 2.50 美元的情况下,该配置能够正确解决 43% 的任务。
解决率因语言而异(图 2 ),其中 Rust 的解决率最高,C/C++ 的解决率最低。
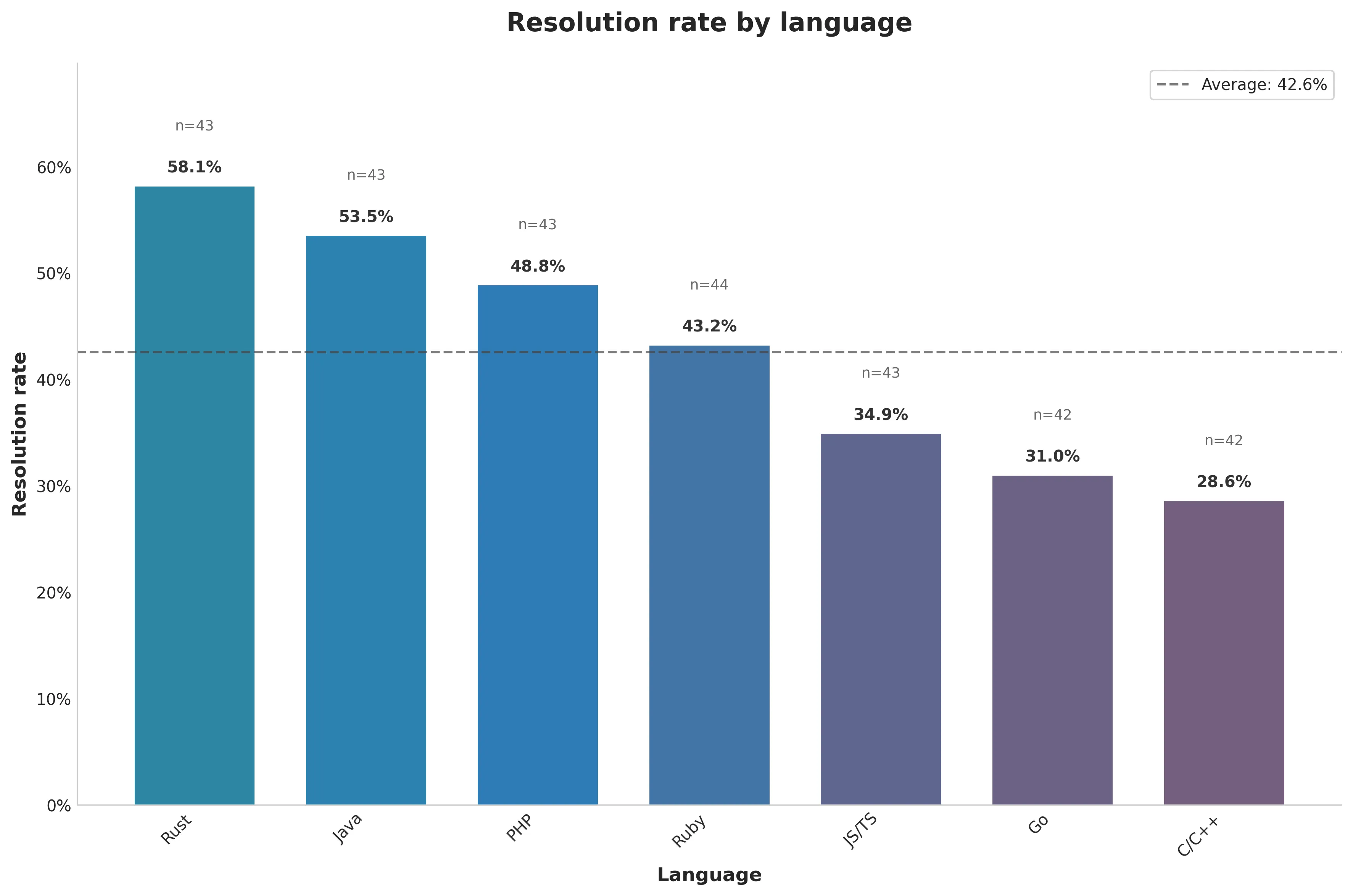
也解释为什么 ai 编程公司用 Rust 实现 浏览器~ c 语言编译器
| Model | % Resolved | Avg. $ | TrajsNew! | Org | Date | Release |
|---|---|---|---|---|---|---|
| Claude 4.5 Opus medium (20251101) | $0.72 | 2025-11-24 | 1.16.0 | |||
| Gemini 3 Pro Preview (2025-11-18) | 74.20 | $0.46 | 2025-11-18 | 1.15.0 | ||
| GPT-5.2 (2025-12-11) (high reasoning) | 71.80 | $0.52 | 2025-12-11 | 1.17.2 | ||
| Claude 4.5 Sonnet (20250929) | 70.60 | $0.56 | 2025-09-29 | 1.13.3 | ||
| GPT-5.2 (2025-12-11) | 69.00 | $0.27 | 2025-12-11 | 1.17.2 | ||
| Claude 4 Opus (20250514) | 67.60 | $1.13 | 2025-08-02 | 1.0.0 | ||
| GPT-5.1-codex (medium reasoning) | 66.00 | $0.59 | 2025-11-24 | 1.16.0 | ||
| GPT-5.1 (2025-11-13) (medium reasoning) | 66.00 | $0.31 | 2025-11-20 | 1.15.0 | ||
| GPT-5 (2025-08-07) (medium reasoning) | 65.00 | $0.28 | 2025-08-07 | 1.7.0 | ||
| Claude 4 Sonnet (20250514) | 64.93 | $0.37 | 2025-07-26 | 1.0.0 | ||
| Kimi K2 Thinking | 63.40 | $0.44 | 2025-12-10 | 1.17.2 | ||
| Minimax M2 | 61.00 | $0.43 | - | 2025-11-24 | 1.17.0 | |
| DeepSeek V3.2 Reasoner | 60.00 | $0.03 | 2025-12-01 | 1.17.1 | ||
| GPT-5 mini (2025-08-07) (medium reasoning) | 59.80 | $0.04 | 2025-08-07 | 1.7.0 | ||
| o3 (2025-04-16) | 58.40 | $0.33 | 2025-07-26 | 1.0.0 | ||
| Devstral small (2512) | 56.40 | - | - | 2025-12-09 | 1.17.2 | |
| Qwen3-Coder 480B/A35B Instruct | 55.40 | $0.25 | 2025-08-02 | 1.0.0 | ||
| GLM-4.6 (T=1) | 55.40 | $0.10 | 2025-12-01 | 1.17.1 | ||
| GLM-4.5 (2025-08-22) | 54.20 | $0.30 | 2025-08-22 | 1.9.1 | ||
| Devstral (2512) | 53.80 | - | - | 2025-12-09 | 1.17.2 | |
| Gemini 2.5 Pro (2025-05-06) | 53.60 | $0.29 | 2025-07-26 | 1.0.0 | ||
| Claude 3.7 Sonnet (20250219) | 52.80 | $0.35 | - | 2025-07-20 | 0.0.0 |
 | 1 cellsyx 2 月 10 日 SWE 的评分差距不太容易直观量化到使用体验上, 但体感大差不差. 我用下来最能看出模型输出质量的场景有三点: 1. 是否能用尽可能少的对话轮次生成符合需求的无 bug 代码 2. debug 过程需要的用户提示是否尽可能少, 修复方案是否合理. 差一档的模型, 要求用户输入和修复尝试次数会明显增加 3. 对于稍大项目(>1 万行有效代码)能否尽量保持处理小项目时的工作效率和生成代码的质量 从这两个角度评价的话 Opus 4.5 肯定是比 Gemini 3 Pro 强. 我最近刚开始用 GPT-5.2-codex Extra High, 感觉也很厉害. 编程语言的话肯定是约束条件越严格越好, 完成需求的可选方案越少, 出错概率越低, 所以这方面 C/C++ 肯定吃亏. 对于动态语言, 目前 AI 生成的 Python 代码里 Type Hint 几乎已经是事实标准了. 即使是约束最严格的 Rust, anthropic 那篇用 Opus 4.6 生成 C 编译器的文章里也提到在项目执行后期, Opus 4.6 也经常在修改的时候把之前已经实现的功能改坏. 目前模型的上下文还是没法完全满足编译器这种项目的需求, 编程语言或者类型提示的约束其实是在给上下文长度不足这个无法绕过的限制兜底. |
 | 2 rb6221 2 月 10 日 个人感觉不同模型是有自己的不同风格的,比如我体感上 claude sonnet 系列对比 gemini 系列,完成一个单体需求: 前者倾向于先扫描项目代码和文档,构建整体思路,然后一气呵成的完成,最后还会自己主动加上测试代码;而后者倾向于边写边解决问题,写一点代码然后一看,有报错,然后现场分析现场修复。 最终从整体上来看,就是 claude sonnet 给人的感觉对话轮次更少,更稳健完整。但是他又更贵。 |