

VictoriaMetrics 开发者笔记:团队内关于 Distributed Tracing 的调研,对比 Tempo 和 ClickHouse
RedisMasterNode 2025 年 5 月 19 日 2183 次点击这是一个创建于 341 天前的主题,其中的信息可能已经有所发展或是发生改变。
谈到可观测性,人们总是会提起它的三大支柱:Metrics, Tracing, 和 Logging 。在 VictoriaMetrics,我们已经有了 Metrics 和 Logging 的解决方案 VictoriaMetrics 和 VictoriaLogs 。同时我们也一直听到很多声音,其中之一就是:VictoriaTraces 什么时候发布。
如果你也关心这个问题,那么相信这篇博客可以让你了解我们内部对 Distributed Tracing 解决方案的调研情况:会不会有 VictoriaTraces?它和竞品比起来怎么样?
1. 什么数据库适合 Trace Span
一个 Trace 是由许多 Span 组成的,所以要打造一个 VictoriaTraces ,我们首先思考的是,Span 长什么样子,什么数据库适合存储这种数据。
以下是一个 Span 的例子:
{ "name": "/v1/sys/health", "context": { "trace_id": "7bba9f33312b3dbb8b2c2c62bb7abe2d", "span_id": "086e83747d0e381e" }, "parent_id": "", "start_time": "2021-10-22 16:04:01.209458162 +0000 UTC", "end_time": "2021-10-22 16:04:01.209514132 +0000 UTC", "status_code": "STATUS_CODE_OK", "status_message": "", "attributes": { "http.method": "GET", "http.target": "/v1/sys/health", "http.server_name": "mortar-gateway", }, "events": [ { "name": "", "message": "OK", "timestamp": "2021-10-22 16:04:01.209512872 +0000 UTC" } ] } 很容易留意到,它就是一系列 Key-Value 的组合,大部分 Key-Value 仅作展示,小部分(如 trace_id、attributes)可以被用作查询条件。
如果你恰好也有了解过 Logging 的一些解决方案,你会发现 Trace Span 和 Structured Log 很像:
- Structured Log 和 Trace Span 都是由一系列的 Key-Values (或者 Fields ,Attributes ,Tags ,不管怎么称呼它们都行)组成,而这些 Key-Values 中有很多重复的内容。
- 它们对写入量需求很大,一个企业每天可以轻松采集数 TB 甚至 PB 的 Logs ,Traces 也是一样。
- 这些被保存下来的数据只有很少一部分会被查阅,所以围绕这个特点产生了很多采样方案。
当前,几乎没有数据结构能同时针对读性能、写性能、磁盘空间进行优化,在这个三个考察标准中通常只能满足其中一或两项。对于 Structured Logs 和 Trace Spans ,它们很显然更强调写入吞吐量以及磁盘空间。所以:
- 基于 LSM-Tree 的数据结构比基于 B+Tree 的数据结构更合适。前者通常能提供更好的写入性能,而后者更强调查询性能。
- Column-oriented 数据库比 Row-oriented 数据库提供更好的空间利用率,因为 Column (或 Field )中数据的相似性更高,更易于压缩。反之,数据按 Row 存储时更容易获取一行内的数据,这对高性能的查询有帮助。
那么到这里,我们的目标稍微明确了一些:VictoriaTraces 可能是一个基于 LSM-Tree 的列式存储数据库。
2. 造新轮子?
在造轮子之前,我们需要先了解满足这些要求的数据库都有哪些。如果你是 Jaeger 的用户,你一定熟悉它的其中一种存储方案:ClickHouse。ClickHouse 在 Jaeger v1 中以 plugin 形式存在。到了 Jaeger v2 ,社区希望对其提供原生支持,这再一次说明基于 LSM-Tree 的列式存储非常契合 Trace Span 数据。
题外话:谁在用 ClickHouse 作为 Traces 存储?
- 当我还在 Shopee 工作的时候,内部 Tracing 平台是基于 Jaeger 改造的,它的存储最初是 Elasticsearch ,当规模逐步扩大后,被替换为 ClickHouse 。
- 后来,我入职了富途牛牛,尽管时间很短只有 3 个月,我与可观测团队还是有过一些简单的交流。它们的 Tracing 平台使用的是 Zipkin ,并且刚从 Cassandra 迁移到 ClickHouse 。
- 在加入 VictoriaMetrics 前,我在 TT 语音工作,当时使用的是腾讯云的 Tracing 平台。从一次数据导出中,我观察到很多地方有 ClickHouse 的身影,例如表名、数据结构等,所以腾讯云应该也是 ClickHouse 用户之一。
在 VictoriaLogs v1.0.0 版本发布后不久,我们发现它似乎也满足存储 Trace Span 的要求。它是为 Structured Logs 设计的,而我们前面说过,Structured Logs 和 Trace Spans 在方方面面都很相似。
所以,我们打算在从 0 开始构建 VictoriaTraces 之前,用 VictoriaLogs 先做一次 PoC ( Proof Of Concept ,概念验证),万一它能用,万一它很好用呢?
3. VictoriaLogs 数据模型 与 Trace Span
在 VictoriaLogs 中,每条 Log 是由多个 Fields 组成的,包含几个特殊 Fields 以及其余的普通 Fields:
- Stream Fields:数据首先是按照 Stream Fields 来组织的,这可以用来缩小查询范围,它就像索引一样存在,例如
{application_name="...", env="..."}。一些高基数的 Value (例如ip、user_id、trace_id)不适合作为 Stream Fields 存在。 - Time Field:每条 Log 都应该带有时间,个 Field 同样是为减少需要扫描的数据范围而设计的。
- 普通 Fields:任何内容都可以以 Key-Value 的形式作为普通 Field 存在,它可以帮助优化查询。
要将 Trace Span 存储到 VictoriaLogs 中,思路也很简单:把所有的内容都平铺为 Fields ,并在其中挑选出特定的 Fields 作为 Stream Fields 即可。
考虑到 Service Name 和 Span Name(在 Jaeger 中也称为 Operation Name)通常都会被用作搜索 Traces 的首要条件,并且它们也不包含高基数的 Value ,所以它们就被设计为了 Stream Fields ,其余 Span Attributes 都被平铺成普通 Fields 。

4. Data Ingestion 性能
我们最关注的是 VictoriaLogs 的 Data Ingestion 性能与其他竞品比起来怎么样。
目前,热门的 Distributed Tracing 方案包括 Jaeger、Grafana Tempo。所以在测试中,我们选择了 Jaeger + ClickHouse / Jaeger + Elasticsearch / Grafana Tempo + S3 作为比较对象。
在这个 PoC 中,对比对象均分配了 4 CPUs 及 8 GiB 内存,其余组件则按需提供足量资源保证不成为瓶颈。
整体的测试架构非常简单:
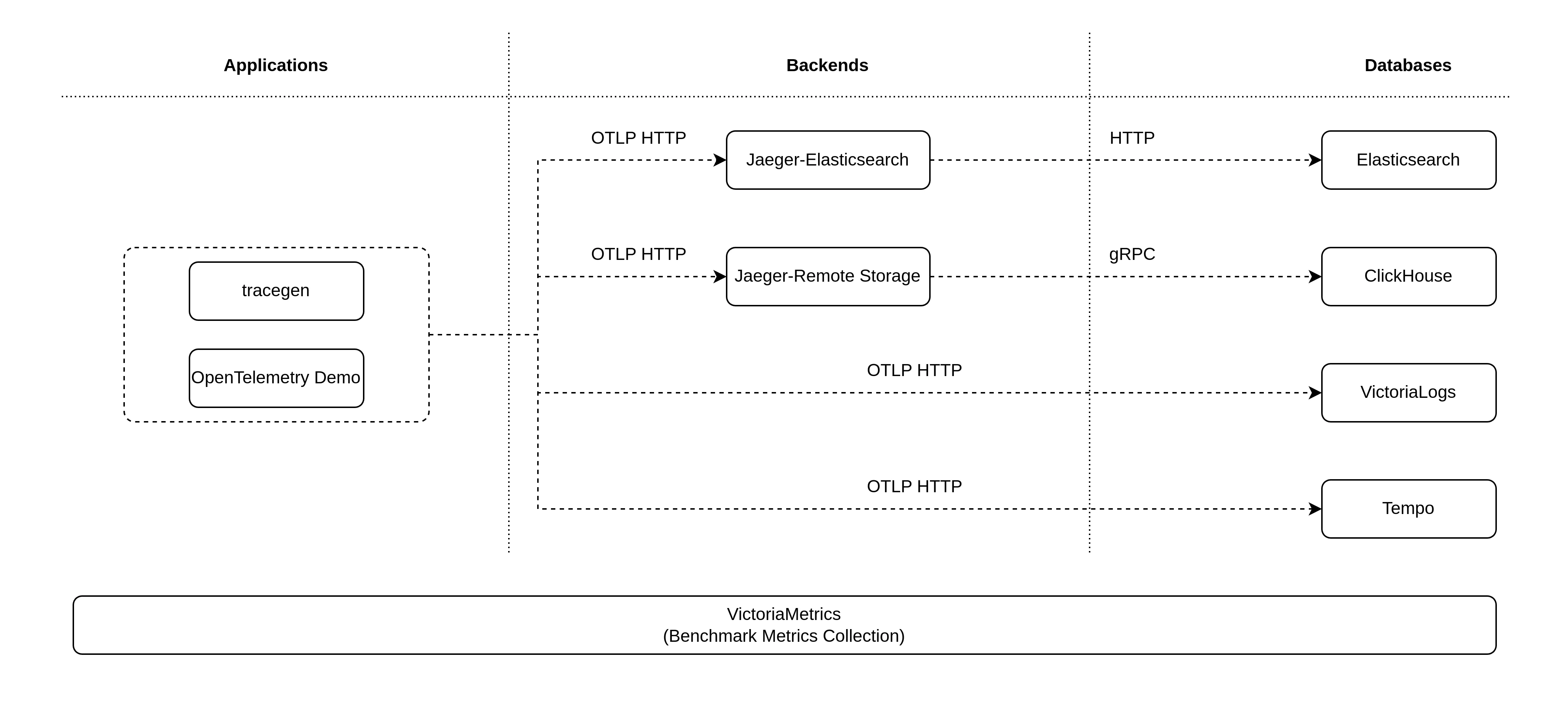
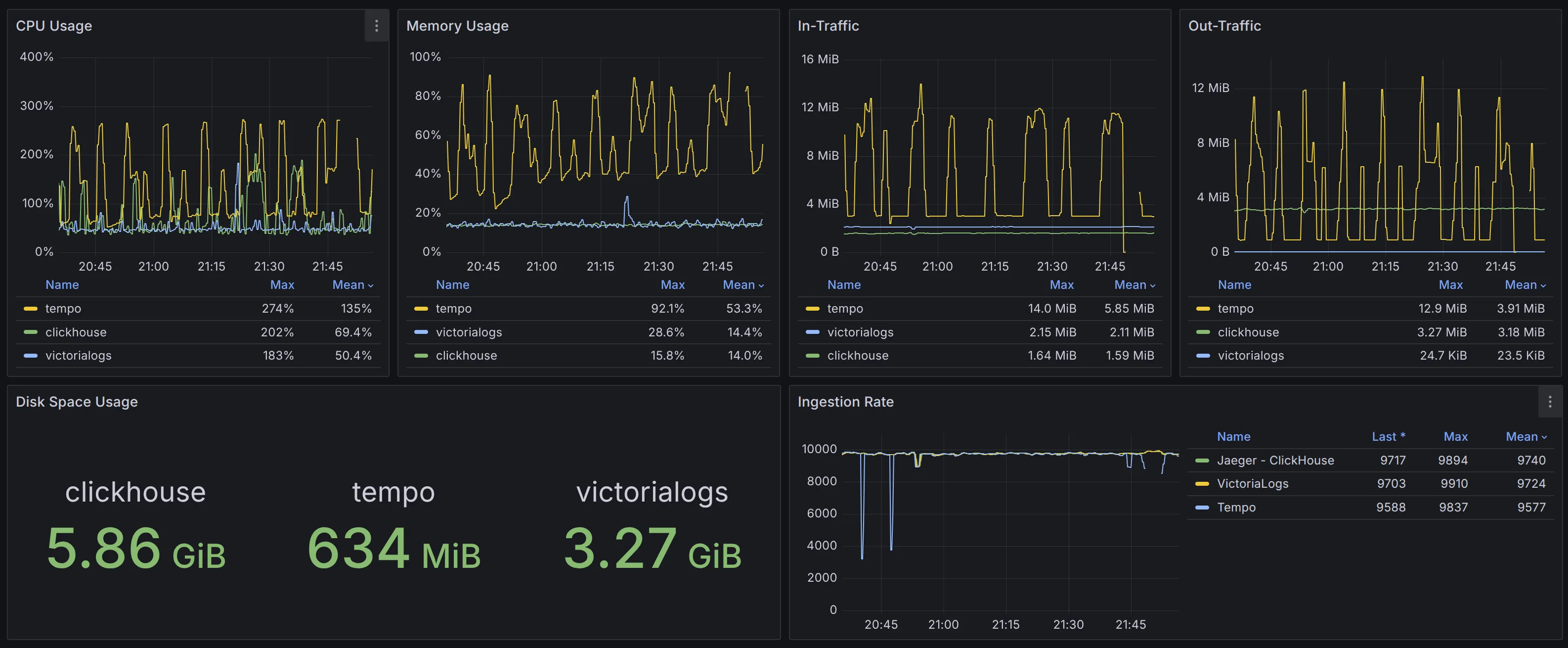
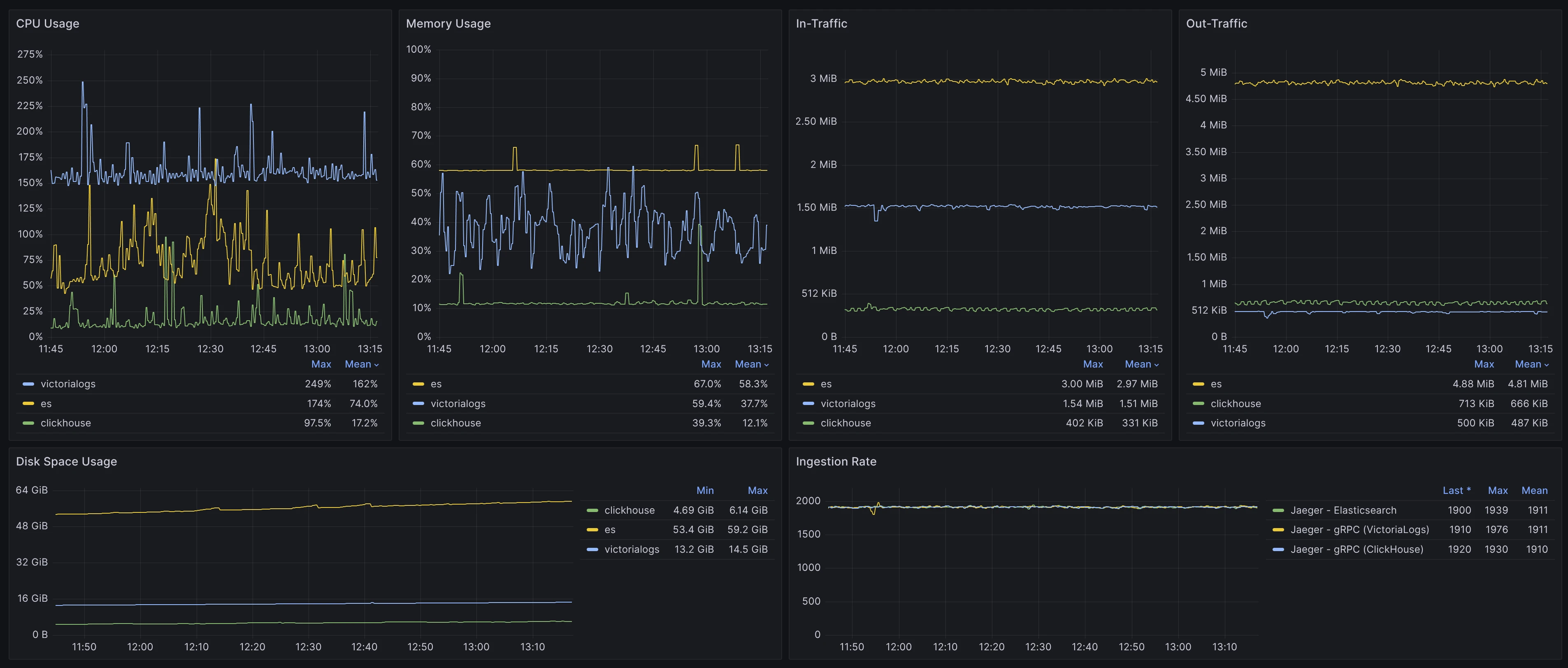
为了直观对比不同方案的硬件资源需求量,我们控制变量,先尝试将 Ingestion Rate 保持在 10000 spans/s。此时得到的结果如监控所示:
题外话:为什么缺少 Jaeger + Elasticsearch 的测试结果?为什么用 10000 spans/s ?
遗憾的是,Elasticsearch 方案在 Ingestion Rate 仅为 5000 spans/s 时就开始出现队列拥堵和 Crash ,在更高的负载下无法保持稳定,因此未能出现在最终的对比中。
事实上,我们也在不同负载下做过多次测试,尝试让所有比较对象都能顺利完成。例如使 Tempo 数据写入本地磁盘而非对象存储,它可以通过 18000 spans/s 的测试,尽管这并不是 Tempo 的推荐使用方式。如果你对这些更为极限的测试感兴趣,请在文章下留言,或者前往 Slack 频道与我们讨论。
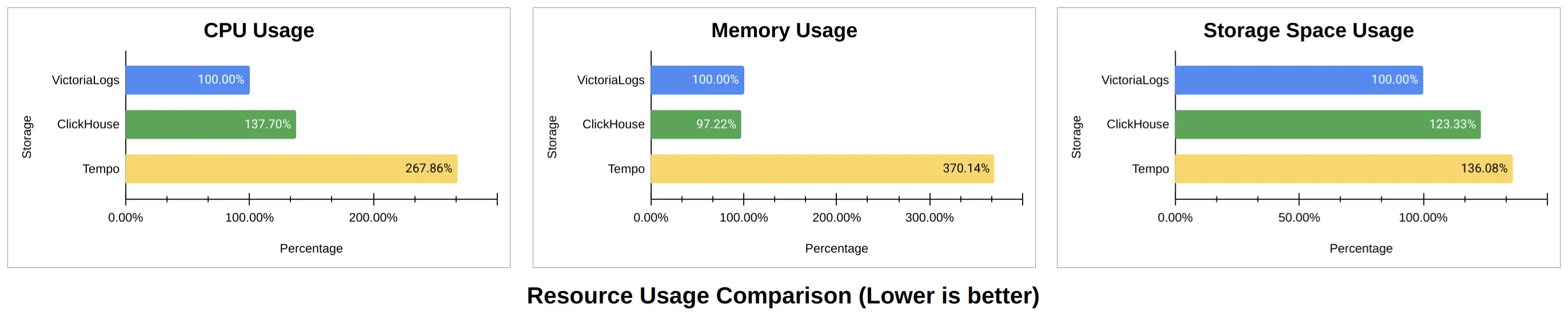
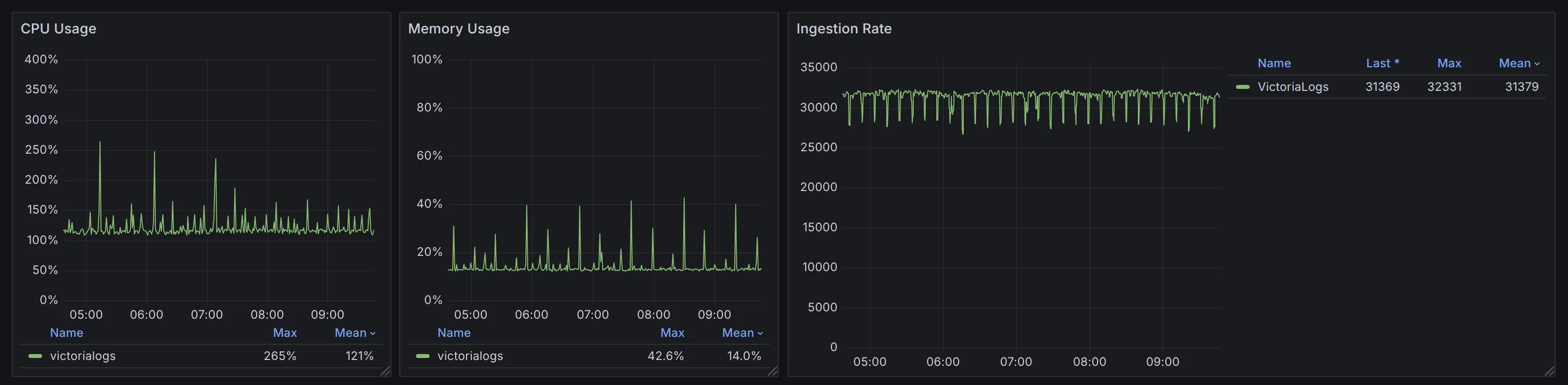
在 CPU 使用率上,VictoriaLogs (50.4%) < ClickHouse (69.4%) < Tempo (135%)。同时,ClickHouse 与 Tempo 的 CPU 使用率波动更明显。
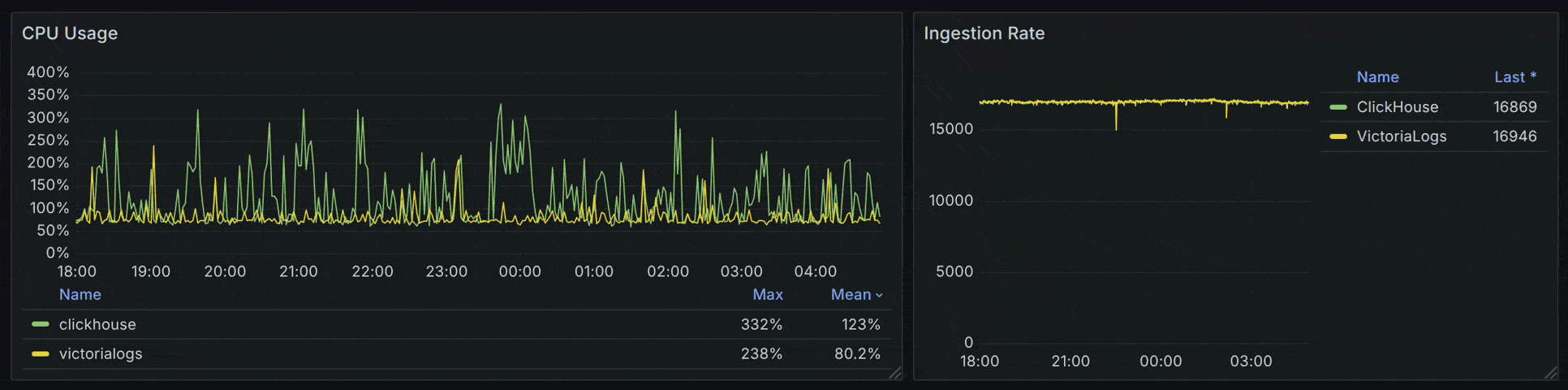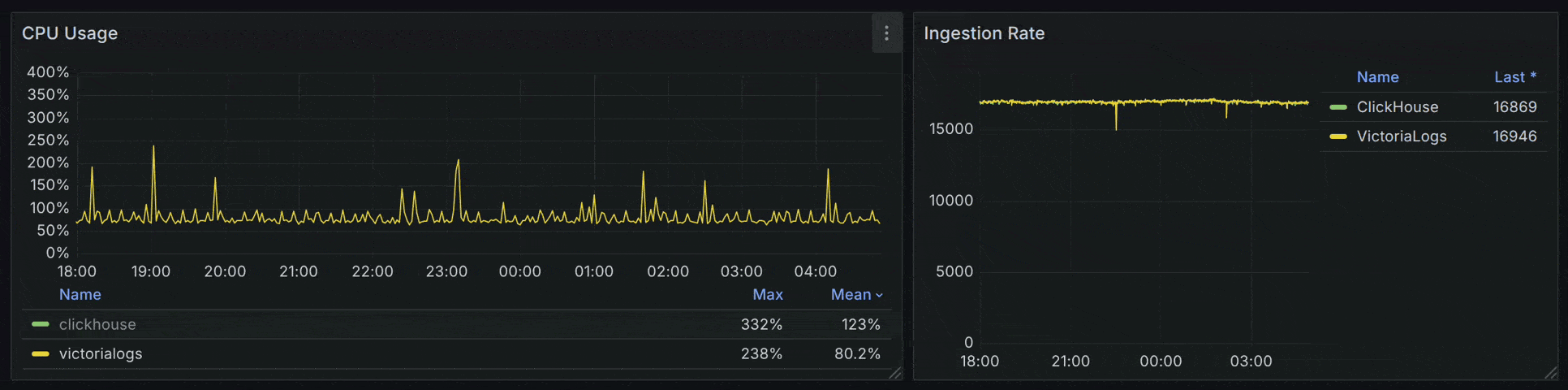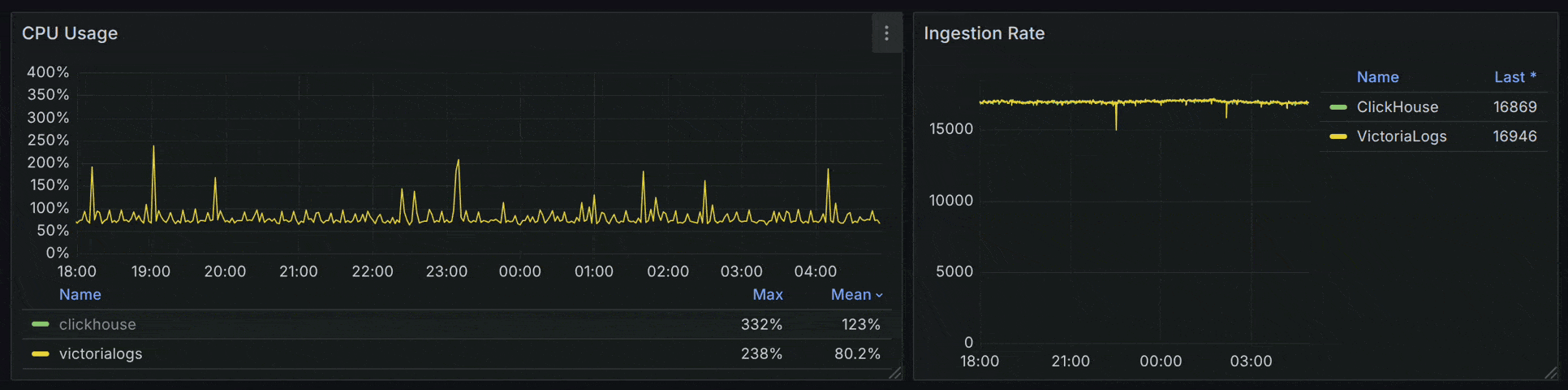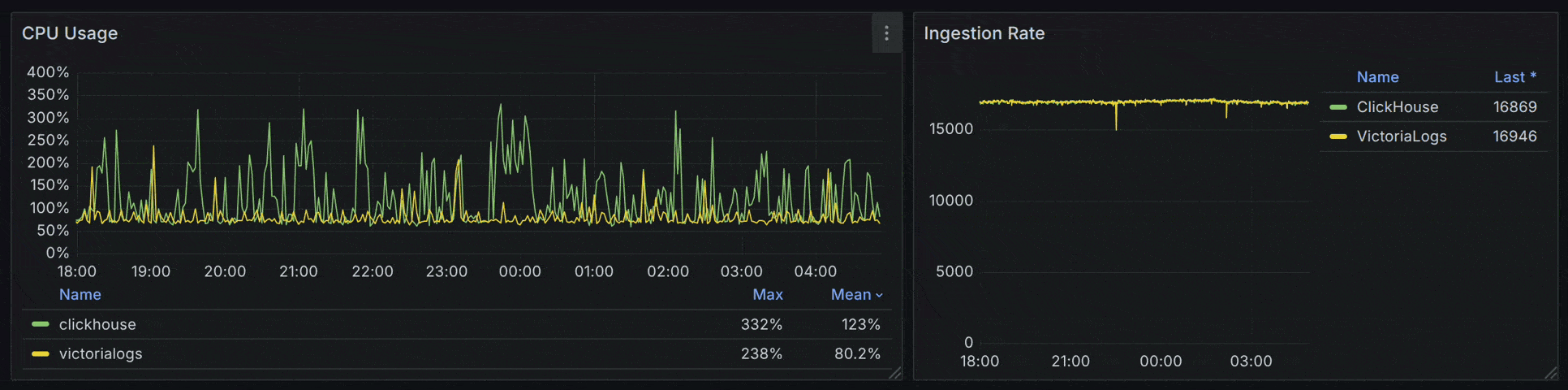
如果仅对比 VictoriaLogs 和 ClickHouse ,在负载提升至 17000 spans/s 时,ClickHouse 的 CPU 波动问题会更加突出。
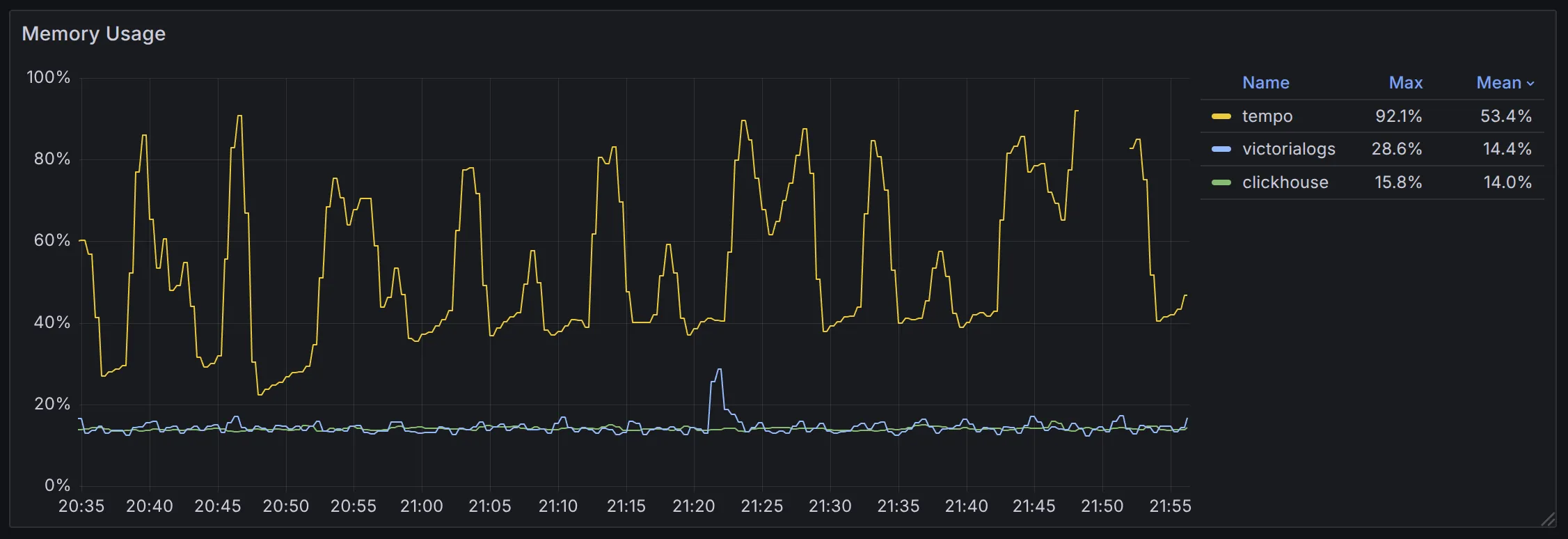
在内存用量上,**ClickHouse (14%) = VictoriaLogs (14.4%) < Tempo (53.3%)**,此时 VictoriaLogs 与 ClickHouse 的内存较为稳定,而 Tempo 使用了 4x 内存容量并且抖动明显,最终也出现了 OOM 的情况。
在数据增长体积上,相同时间范围内 VictoriaLogs (3.27 GiB) < ClickHouse (5.86 GiB)。Tempo 使用的是对象存储,根据平台提供的数据,其数据量约为 4.4 GiB,但是并不便于直观对比。因此我们在后续测试中对比了 Tempo 使用本地磁盘作为存储时的情况:
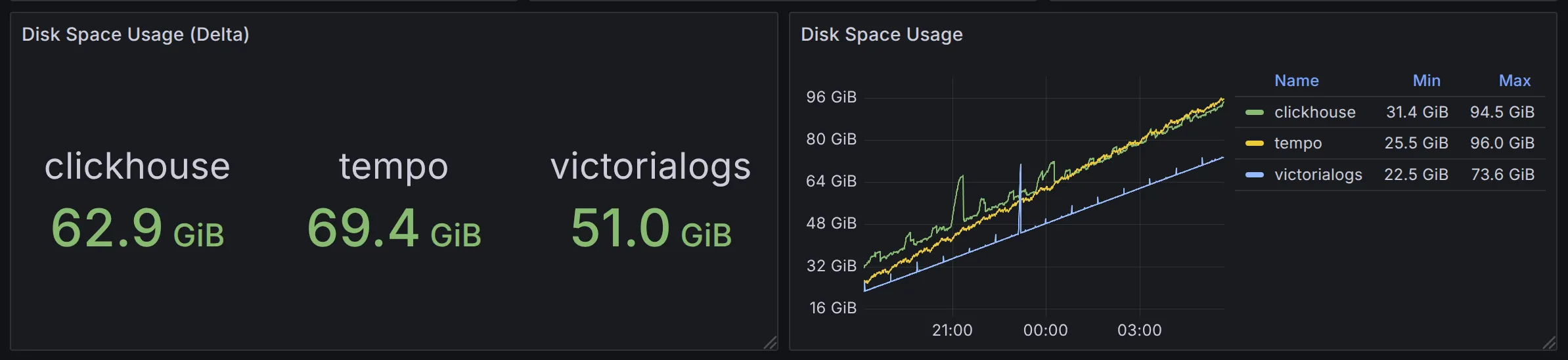
可以看出,虽然 Tempo 使用的对象存储成本更低,但是压缩率不如 VictoriaLogs 和 ClickHouse 。如果 VictoriaLogs 能在未来支持对象存储,那将变得更有竞争力。
题外话:问题
你有留意到不同方案的 In/Out-Traffic 差异吗,是什么原因导致的呢?提示:
以下是以 VictoriaLogs 作为基准,相同负载下各方案所需的资源对比汇总:
5. 数据可视化
行业中炙手可热的 OpenTelemetry 标准只定义了数据传输的协议 OTLP ,但是对于数据如何被查询和可视化并没有明确的标准,这也导致 Jaeger 、Tempo 等项目各自实现了不同的查询 APIs 。
VictoriaLogs 目前没有提供 Trace 的可视化方案,但是为了验证 VictoriaLogs 的查询语言 LogsQL 能否覆盖 Trace 展示的所有场景,我们尝试基于 VictoriaLogs 实现 Jaeger 的 APIs 。
题外话:为什么选择 Jaeger ?
我们选择在 PoC 中实现 Jaeger HTTP APIs 是因为:
- Jaeger 项目使用广泛。
- Grafana 原生提供了 Jaeger Datasource 支持,意味着只要实现 Jaeger APIs ,用户可以在 Grafana 上直接将 VictoriaLogs 中的 Trace 数据可视化。
数据可视化本质上是第 3 节内容的逆向过程,其实并不复杂。
在实现过程中,我们发现 Time Range Filter 是对查询性能影响最大的。例如查询 trace_id 为 c3b94b884c236e1e7ae39e7ca3589d18 的数据,因为 VictoriaLogs 并不存在 trace_id 索引,即不明确这个 trace_id 的对应的数据在什么时间范围、有多少 Spans ,所以需要扫描所有时间内符合条件的数据 Block ,而其中大量扫描是没有必要的。如果可以将时间范围限制在特定的 10 分钟、30 分钟内,整体查询都能大大提速。
因此,使用 VictoriaLogs 作为 Trace 存储,最好可以配置特定的 Lookback Windows 。例如,配置 metadata_lookbehind=3d 使得每次加载所有 Service Name 列表时,只检索最近 3 天内出现过的 Service Name 。
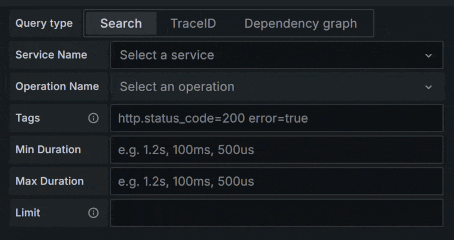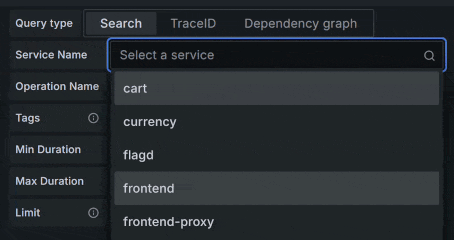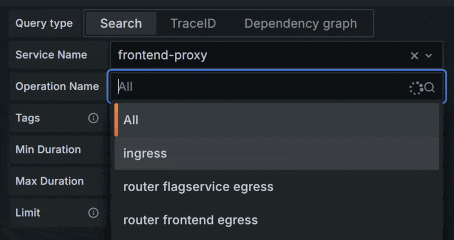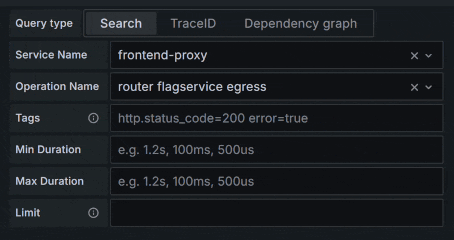
又如,trace_id_lookbehind_step=7d 在每次直接通过 trace_id 查找 Trace Span 时,按照 7 天作为步长逐步检索,如果检索到了数据,则不再去查找下一个步长内的数据了。
实现 Jaeger APIs 后的 VictoriaLogs 既可以搭配 Jaeger UI 使用,也可以在 Grafana 上查询,响应时效较 ClickHouse 和 Elasticsearch 明显更短,说明 VictoriaLogs 也能很好胜任需要展示 Trace 的场景。
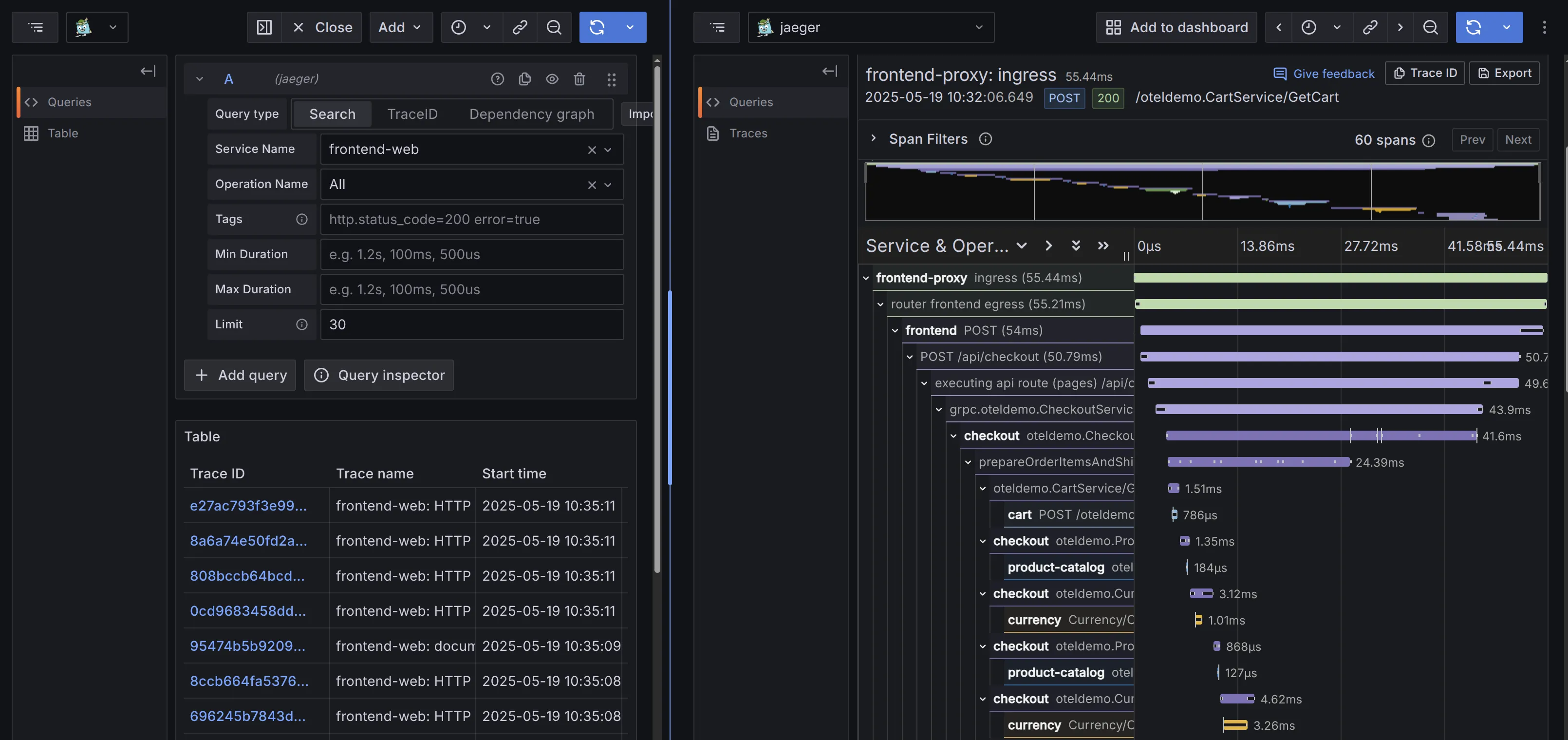
不知道这样的 UI 对用户来说体验怎么样呢?
6. 总结
通过这篇文章,我们希望解答的问题是:
- 什么样的数据库适合用于存储 Trace Span ,为什么 VictoriaLogs 可以成为众多选择之一?
- Trace 数据在 VictoriaLogs 中是以怎样的形式存在的?
- VictoriaLogs 在 Distributed Tracing 的场景下性能有多好,与其他竞品相比如何?
- Trace 数据如何展示?
- 我们还需要 VictoriaTraces 吗?
我想除了最后一个问题,其它 4 个问题应该在前面的章节中已经有了答案。
如果没有更加突破性的方案(例如相同配置下实现 10 倍的数据写入量),我们应该不会单独打造 VictoriaTraces ,毕竟 VictoriaTraces over VictoriaLogs 也很酷不是么?另外,和 VictoriaMetrics 不同,VictoriaLogs 的对象存储支持已经在我们的日程中。相信 VictoriaTraces over VictoriaLogs 也会从中受益。
考虑到 Distributed Tracing 生态中仍有许多工具缺乏好的实现,或许打造一些与采样相关的工具( vtagent?)也会是个不错的主意。
目前,我们想要积极地听取用户对这项功能的意见。我们的初衷是提供高性能、低成本、架构简洁易于扩展的解决方案,这优先于其他所有目标。
题外话:关于性能
目前实验中的 VictoriaLogs 可以在平均 1.2 (最高 2.6 ) CPU 的资源开销下支持 30000 spans/s 的 Ingestion Rate 。由于尚未进行 Profiling 和优化,我们预计正式的 Pull Request 还有很长一段时间才能和大家见面。
但是如果你已经迫不及待想要动手试试这个“玩具”,可以查看以下 Demo。
如果你认为这个功能可以代替你现有的 Trace 存储,想要赶紧体验一下,或者它因为什么原因不是你的菜,请务必通过评论,GitHub Issue 或者 Slack 频道告诉我们,VictoriaMetrics 团队期待在多个方面为我们的用户提供技术支持。
7. 番外篇
其实在更早之前,我尝试过让 VictoriaLogs 作为 Jaeger 的 gRPC Remote Storage ,出于一系列的原因,资源开销并不理想( 10x 之于 ClickHouse )。当时我的结论是 VictoriaLogs 可以存储、查询 Trace Span ,不过毫无竞争力,并且打算就此结束。
但是 @hagen1778 和我说,现在下结论还太早,并且给了我很多的建议。相似的事情也发生在我和 @valyala 之间,我还从 @AndrewChubatiuk 及其他同事的代码中找到了许多有帮助的技巧。Thanks to these experienced engineers for saving my day 。
7 条回复 2025-05-20 10:45:17 +08:00
 | 1 tinkerer 2025 年 5 月 19 日 打算尝试一下, 感谢你们的智慧和劳动 |
2 F281M6Dh8DXpD1g2 2025 年 5 月 19 日 你要知道 clickhouse 在 ingestion 上有多少花活又放弃了多少一致性就不会这么比了 |

 | 4 lrh3321 2025 年 5 月 19 日 为什么我感觉这文章有点像是翻译腔。 |

 | 6 RedisMasterNode OP |
 | 7 wsszh 2025年 5 月 20 日 感谢分享,挺有意思的 |