
我用 V 友们的 2 万条 AI 海龟汤游戏数据,评估大模型推理能力哪家强
wseani mazzzystar 2024-08-09 10:16:15 +08:00 4785 次点击这是一个创建于 438 天前的主题,其中的信息可能已经有所发展或是发生改变。
GPT-4o, Claude,月之暗面,豆包, DeepSeek, MiniMax, 通义千问, LLama3.1 ,谁才是真实推理游戏中的王者?
6 月,我发帖 做了个 AI 海龟汤小游戏,恐怖慎入,有很多 V 友们玩了它,但在这个过程中,很多人吐槽 AI 的判定不合理,我开始思考能否用这个游戏来评测大模型的推理能力?一个月半后,我终于有了结论,想看排名可以直接滑到最底部 :D
下面是正文。
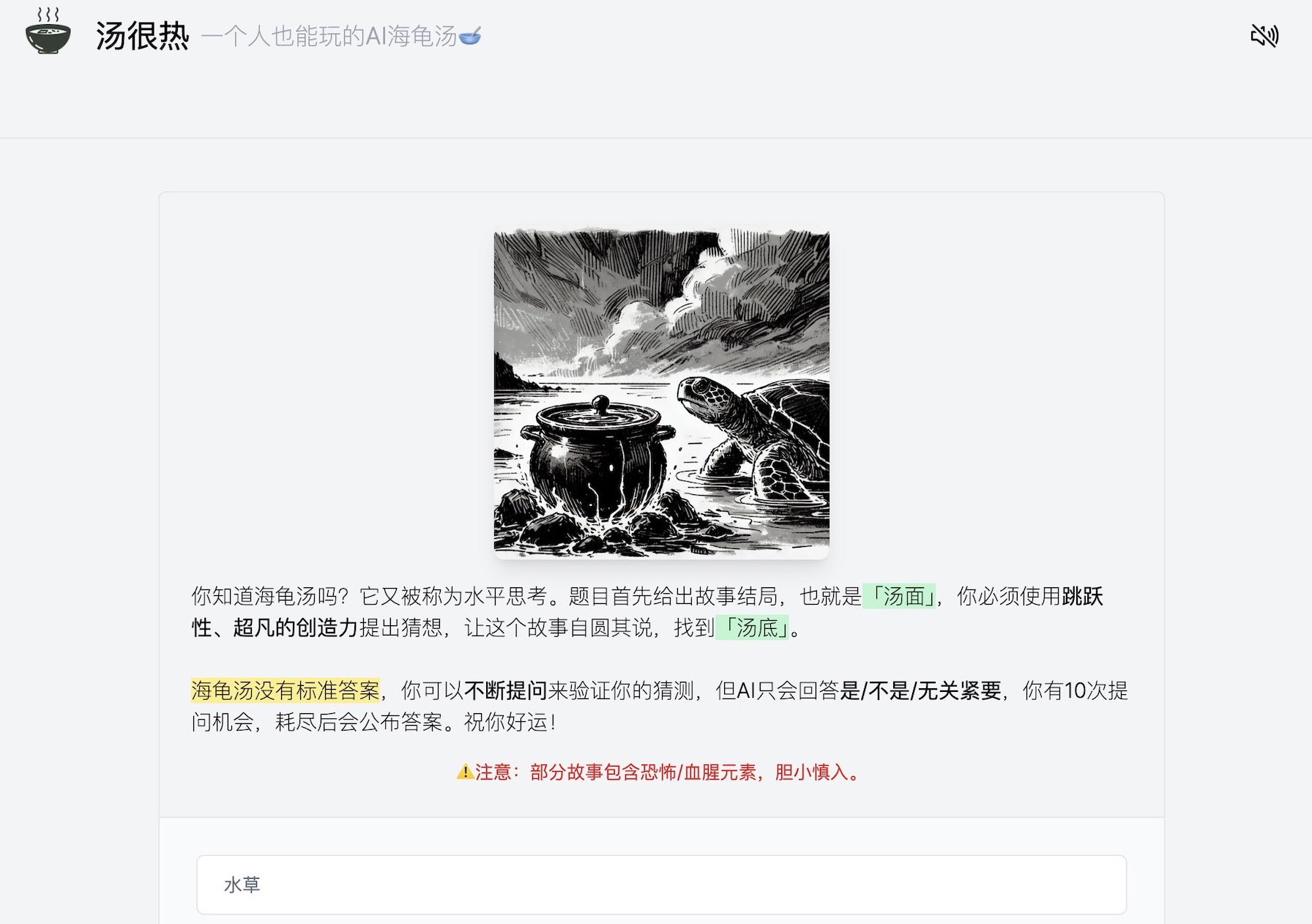
海龟汤
人生中第一次接触海龟汤游戏是我的初中英语课上,课间休息时老师突然问我们:
一个男人走进一家餐厅,点了一碗海龟汤,他吃完问服务员:这是真的海龟汤吗?服务员说:是的,他就举枪自杀了。请问为什么?
游戏规则是:你可以提问或给出猜测,老师只能回答 是/否/和故事无关,比如你可以问:男人是否曾经经历灾难?,但不能问男人今年多少岁。我们猜了好多轮,上课铃响了,老师揭晓答案:
他和妻子度蜜月时遭遇海难,流落荒岛,由于没有粮食,妻子被饿死,同伴用妻子的肉煮汤给他喝,骗他是海龟汤。后来他被路过的船只救走,今天,他喝到真正的海龟汤,才想起来当时吃下的是妻子的肉,悔恨之下举枪自尽。
在海龟汤中,展现给玩家的是汤面,而沉在水底的故事真相被称作汤底,这个游戏至少 2 个人才能玩:有一个人是裁判,他在知晓汤底的情况下,对玩家的猜测作出判定,给出是/否/无关的回答。
我想能否做一个 AI 海龟汤游戏:将汤面和汤底告诉给大模型,让它对玩家的猜测给出判定。我在去年 12 月做了个GPTs, 它能自动生成新故事、用 DALLE 画插图、判定玩家提问。但很快我发现:AI 生成的海龟汤味道寡淡,玩起来没有趣味。并且,海龟汤的魔力,往往就在于故事本身血腥/重口,这经常导致玩到一半因为违反 OpenAI 审核政策而无法继续。
今年 6 月,我终于意识到,不一定非得由 AI 生成故事,让它充当裁判即可。我开始在网上搜罗,当晚独自在客厅看完了 1500 个海龟汤,其血腥恐怖程度,大夏天的晚上我都感觉后背发凉。最终,我筛选了 32 个相对不恐怖、不违反伦理、有逻辑的故事,开始写代码。
我基于最佳平替的代码很快完成了开发:你可以随机开始一个故事,有 8 次猜测机会,猜测正确或次数耗尽,就会公布答案。产品取名汤很热,为了增加沉浸感,我给每个故事都配了插图和环境音。
不过,AI 海龟汤游戏并不是本文的重点。
大模型比人类笨多了
我发现有很多用户吐槽AI 作为裁判的实力堪忧。比如:
起初,我以为是我用的模型(DeepSeek)不行,直到我将模型切换成当时风评最好的 Claude 3.5 Sonnet ,发现许多错判仍然无法避免。例如:
{ "故事": "小红裙", "汤面": "姐姐为我选了一件小红裙, 我穿着去上学了, 晚上回家发现了一具尸体", "汤底": "我的母亲和老师有染, 他们总趁着父亲不在时温存. 而为老师提供信息的 就是我的小红裙, 每当我穿着小红裙去上学就说明那晚父亲准不在. 这天妈妈忙, 姐姐为我选了一件小红裙, 老师看见以为父亲不在家, 便来我家找母亲, 正好被父亲 撞上, 然后父亲杀了他." }, 用户提问: "我如果不穿小红裙是不是不会有人死", 几乎所有模型都回答"不是/不相关" 再比如:
{ "故事": "山顶", "汤面": "一个人住在山顶的小屋里, 半夜听见有敲门声音, 但是他打开门却 没有人,于是去睡了. 第二天, 有人在山脚下发现死尸一具, 请问发生了什么?", "汤底": "山顶的小屋的门前是悬崖, 悬崖下的人好不容易才爬上来, 想要敲门求救. 一开门, 就又被推了下去, 最后从山顶上掉下去摔死了" }, 用户提问: "门是朝外开的", 几乎所有模型都回答"不是/不相关" 我意识到,海龟汤游戏也许非常适合评测大模型(LLM)在真实场景下的推理能力。
真实环境下的 LLM 推理能力
现在,大模型被广泛用于游戏、客服或者许多和用户直接交互的场景,这些场景有如下特点:
- 用户的提问千奇百怪、无法预估,但 AI 需要给出合乎逻辑的应答。
- 在给定上下文对情况下,AI 需要回答用户一些明确的对或错。例如已知一件商品的生产日期和保质期,用户在 2024 年 8 月 9 日提问,202 几年过期?
- 有些游戏需要在用户进入某些关卡、或发现关键线索时触发下一步剧情,那么,判定用户是否真的发现真相,就显得尤为重要。
与学术界现有的评估指标相比,在真实环境下与真人互动的场景中,模型面临的情况要复杂得多。然而,也是在这样的场景下评估模型的表现,才具有更大的实用价值。
现有评估指标出了什么问题
如果你经常关注大模型评测榜单(如LMSYS),一定对 MMLU 、MT-Bench 等评测指标(Benchmark)不陌生。我在这里简单解释它们的评测方法:
MMLU
MMLU 是广为人知的大模型评估指标,它包含了涉及物理、天文、计算机、生物、临床医学等 57 个科目的 15,000 多个多项选择题,但这其中中存在大量死记硬背的考题。例如:
以下哪一个是远程木马? A:内存泄漏 B:缓冲区溢出 C:处理能力较低 D:编程效率低下 这些基础常识当然很重要,但过分强调背景知识,会让 MMLU 无法衡量模型真正的语言理解能力和逻辑外推能力:假如一个孩子因为没学过微积分、计算不出曲边三角形面积,我们会说他笨吗?
MT-Bench
MT-Bench 是一个多轮问题数据集,被评测的模型需要回复预先设置好的问题,并回答下一轮的提问。但因为是开放式对话,并不存在确定的标准答案,模型的回答质量由 GPT-4 来审判。
因此,MT-Bench无法评估比 GPT-4 更强的模型,同时 GPT-4 作为“法官”可能会存在偏见,对某些模型输出打低分,而更偏爱来自 ChatGPT 的回答。
Chatbot Arena
正是以上评测指标存在的种种问题,LMSYS 最终选择了最简单粗暴的方式:打擂台。
真人用户发起聊天,系统会随机挑选 2 个模型给出回答,真人通过投票的方式选出更满意的模型。最终,会形成一个所有模型的综合评分。
这是目前可信度最高的方法,但缺点也很明显:一个新模型需要公开测试很久,获得大量反馈,其分数才足够可信。并且,分数代表综合能力,无法仅对某个细分领域(代码/数学)进行评估。
海龟 Benchmark
因此,我制作了一个新的大模型评估指标:海龟 Benchmark。
收集用户在玩 AI 海龟汤游戏中输入的猜测,逐一进行人工标注(对、错、不相关),然后用这个数据集,测试大模型的评判结果相较于真实结果的准确率。
我发现,现有评测指标的种种问题,在海龟 Benchmark 上都可以完美避开:
- 不需要额外背景知识。 不同的大模型训练所使用的知识库不同,导致一些测评很难公正。但海龟汤游戏里几乎包含了推理所需的全部信息,一旦得知汤面和汤底,大模型就能作出判断,这使得评估被限定在了模型的推理能力。
- 结果是客观的,不以人类偏好为转移。 例如:在上述故事《山顶》里,小屋在悬崖边,主人半夜开门将登山者推下山导致后者被摔死。因此,门是朝外开的这个猜测就是正确的,这种正确性是客观的、和人的感受无关。
- 结果明确,很容易量化。 许多评估指标里,模型的输出结果是一段文本回答,这导致难以量化模型效果。但海龟汤的猜测结果只有三个:对、错、不相关。只要 准确标注了测试集,任何人就可以用它来测试任何自己想测试的模型,并获得量化的数值结果。
- 正常人类获知汤底的情况下,可以 100%答对。 这使得人工标注不会太过复杂。这条也说明,现阶段的大模型智商相比人类还有很大差距。
- 数据永远更新、无法作弊。 有部分厂商会直接将现有的 benchmark 数据集加入训练来刷分,但在海龟 Benchmark 这种模式下则行不通:模型评估的是用户的猜测,而不是故事本身。每隔一段时间,就会有玩家产生新的猜测,而人类的脑洞之大,导致猜测几乎无法被穷尽。
例如,针对上述故事《小红裙》,就有千奇百怪的用户猜测:
用户猜测 判定 红裙子跟诅咒有关 红裙子是姐姐的阴谋 我并没有去上学 有其他的人来我们家 红裙是求救信号 死的是穿小红裙的人 红裙的颜色是被血染红了 尸体是我的爸爸 上学不允许穿小红裙 我是凶手 我父亲杀人了 穿了小红裙导致别人认为我是其他人 死者认识我妈 死者与我家里人有仇 因此,虽然海龟汤的故事本身可能比较无厘头,但让 AI 依据海龟汤内容进行合理推断,却可以做到相当程度上的客观。
这有点像弱智吧:一个从百度弱智吧抓取的 200 多条提问(如:每个人工作都是为了赚钱, 那么谁在亏钱) 这些奇葩的问题却显著增强了 AI 的逻辑推理能力。
海龟数据集
AI 海龟汤游戏有 32 个故事,上线后的 2 周里,共有 4000 多个用户提出了 2.6 万个猜测,我从日志中解析出结果,开始进行数据清洗,这包含:
- 去除重复提问,例如海龟汤有毒吗? 和 他喝的汤是否有毒本质是同一个问题。
- 去除无法用 是/不是/不相关 回答的提问,例如 男人今年几岁?
- 去除含糊不清的提问,例如他对闺蜜做了什么吗?,在《闺蜜》这个汤里,是丈夫与闺蜜出轨,但丈夫并没有对闺蜜做任何实际的动作,所以这个回答很难给出准确回答。
随后,我开始进行人工标注,这个过程持续了 2 周,最终我们从 2.6 万条数据中,获得了 4448 条干净的数据。标注过程中,我们发现错和不相关这两个标签在有些情况下不好区分,例如在故事《海龟汤》中,对于海龟是男人养的这个猜测,回答错和不相关好像都对。所以最终,我们决定合并这两个类别,于是标注变成了 2 类:对、错/不相关。
标注完,我开始跑模型测试,我挑选了 11 个我感兴趣的模型:
- Qwen2 70B (通义千问)
- Kimi-Chat (月之暗面)
- Deepseek
- 豆包
- Claude 3.5 Sonnet
- Minimax abab6.5s
- LLama3.1 405B
- LLam3.1 70B
- GPT-3.5
- GPT-4o-mini
- GPT-4o
我在 4448 条数据上测试了所有结果,过滤掉了所有模型都答对的简单问题,在剩下的 1699 条困难问题上,进行了二次确认标注,最终,我们得到了 1537 条准确率几乎 100%的标注结果。
我分别用不带示例(zero-shot)和带有 2 个示例(2-shot)的 prompt ,测评了模型的输出结果准确率。
评测结果
最终各模型准确率排名如下: 
可以看到,大部分模型在加了示例后性能有了微弱提升。
我担心,可能存在这么一种情况:_模型在某个故事里表现极差,而该故事的测试样本又非常多,导致总的平均准确率有偏差_。为了排除这种情况,我统计了按故事粒度的模型准确率,也就是分别计算模型在这 32 个故事上各自的准确率,然后除以 32 。我发现,除了通义千问和 GPT-4o 外,上面的排名基本不变。

将 2-shot 结果,_以横轴为模型总的准确率,纵轴为模型平均故事准确率_,绘制图表如下

* 为了更直观地比较其他模型差异,我将表现过差(<0.51)的模型 GPT-3.5 从坐标轴中舍弃了。
从上图也可以直观感受各类模型的表现和差距:
- Claude 3.5 Sonnet 是当之无愧的第一梯队,并且远远领先其他模型。
- GPT-4o 、通义千问、月之暗面、LLama3.1 405B 和 Minimax 是第二梯队。我尽量避免更细的划分,但这些模型能力按排序依次下降,降幅肉眼可见。
- 豆包、DeepSeek 和 LLama3.1 70B 是第三梯队。
- GPT-4o-mini 是第四梯队。
- GPT-3.5 早就应该被淘汰了。
以上评测仅针对模型的中文理解和推理能力,如果之后有经费和精力,我会考虑将所有的故事和测试问题翻译成英文,再使用英文 prompt 重新测试一遍,以消除因为语言而造成的模型性能下降。
测试你关心的模型
上述模型可能不包含你关心的模型。并且,为了排除因为我的 prompt 能力、参数和温度设置有问题,造成测评结果不准,我将完整的标注数据、prompt 、评估代码以及我们的测试日志开源了:
https://github.com/mazzzystar/TurtleBenchmark
你可以对任何你感兴趣的模型进行测试。如果你有了完整测试结果,欢迎提交 issue。
 | 1 Retas 2024-08-09 10:28:11 +08:00 牛逼,场景也特别适合做大模型推理能力测评,期待英语测评 |
 | 4 zhouyg 2024-08-09 10:57:11 +08:00 赞,又被收获到 |
 | 5 KorenKrita 2024-08-09 11:01:54 +08:00 今日最佳 AI 实践 学习到了 |
 | 6 wusheng0 2024-08-09 11:29:59 +08:00 厉害 |
 | 7 marquina 2024-08-09 11:43:36 +08:00 牛的 |
| 8 marquina 2024-08-09 11:47:12 +08:00 当然不同的模型有不同的回答风格/价格,在不同的场景/prompt 表现也不一样,特定场景应用自己 bench 一下,才能最准确看出哪个模型最符合业务场景。 |
 | 9 cryzzchen 2024-08-09 12:10:12 +08:00 行动力满分! |
 | 10 zdl0929 2024-08-09 14:17:09 +08:00 学习到了,我去尝试下游戏,贡献点数据 |
 | 11 whoami9426 2024-08-09 14:56:32 +08:00 可以写一篇 paper 了, 基于海龟汤的大模型逻辑基准测试方法 |
 | 12 zlsolator 2024-08-09 15:08:15 +08:00 好文章! |
13 R4rvZ6agNVWr56V0 2024-08-09 15:10:50 +08:00 6 |
 | 14 linauror 2024-08-09 15:23:32 +08:00 钻研精神,赞 |
 | 15 pinylin 2024-08-09 15:34:43 +08:00 |
 | 16 MMMit 2024-08-09 16:24:20 +08:00 牛 我居然给看完了 |
 | 17 VxLzKg4uLbi32w60 2024-08-09 16:48:36 +08:00 赞,在 GPT4 出来不久,我就在考虑用 GPT4 结合 X 信群聊机器人做一个海龟汤问答机器人,因为俺们群里经常会玩海龟汤,但在玩的过程中,做会有奇奇怪怪的事情打断提出汤面的人,于是就有了这个想法,但实测下来,仍然没有完成。我也看到了不少有同样想法的人,即便是写了长篇大论的限制条件(那时候问 GPT4 海龟汤是什么,它只能回答海龟做的汤),还是会有问题 |
 | 18 v2e0xAdmin2 2024-08-09 18:08:17 +08:00 我之前做 ai code Review 的 时候,思路好像类似,准备 10 种场景的 good+bad 代码(人类判断),让多个 ai 进行打分,综合来看,gpt4o 的判断和人类的最接近 |
 | 19 yinmin 2024-08-11 11:40:00 +08:00 @wseani 能测一下 GLM-4 、Google Gemini 1.5 pro 吗? 国产的 GLM-4 据说推理能力也很强,目前新账户有送 token ,应该足够测试用的。 |
 | 20 wseani OP @yinmin 我注册了发现他家 api 巨贵(100 块/1M token),所以没测。Gemini 我也想测但我没办法绑卡,我看看之后能不能补上。代码和数据开源了,所以如果感兴趣,你也可以自己试试看~ |
| 21 yinmin 2024-08-11 13:49:06 +08:00 @wseani GLM-4 目前新注册用户送 500 万 tokens(GLM-4),有效期 1 个月。 google 账号先绑卡成功(支持国内信用卡),然后再到 google cloud 把信用卡带过来,如果直接在 google cloud 直接录入信用卡封控等级很高。 |
 | 22 v2user89 2024-10-08 11:24:54 +08:00 突然发现你们不但发了论文, 论文还上了 huggingface #3 Paper of the day |
| 23 v2user89 2024-10-08 11:25:32 +08:00 |