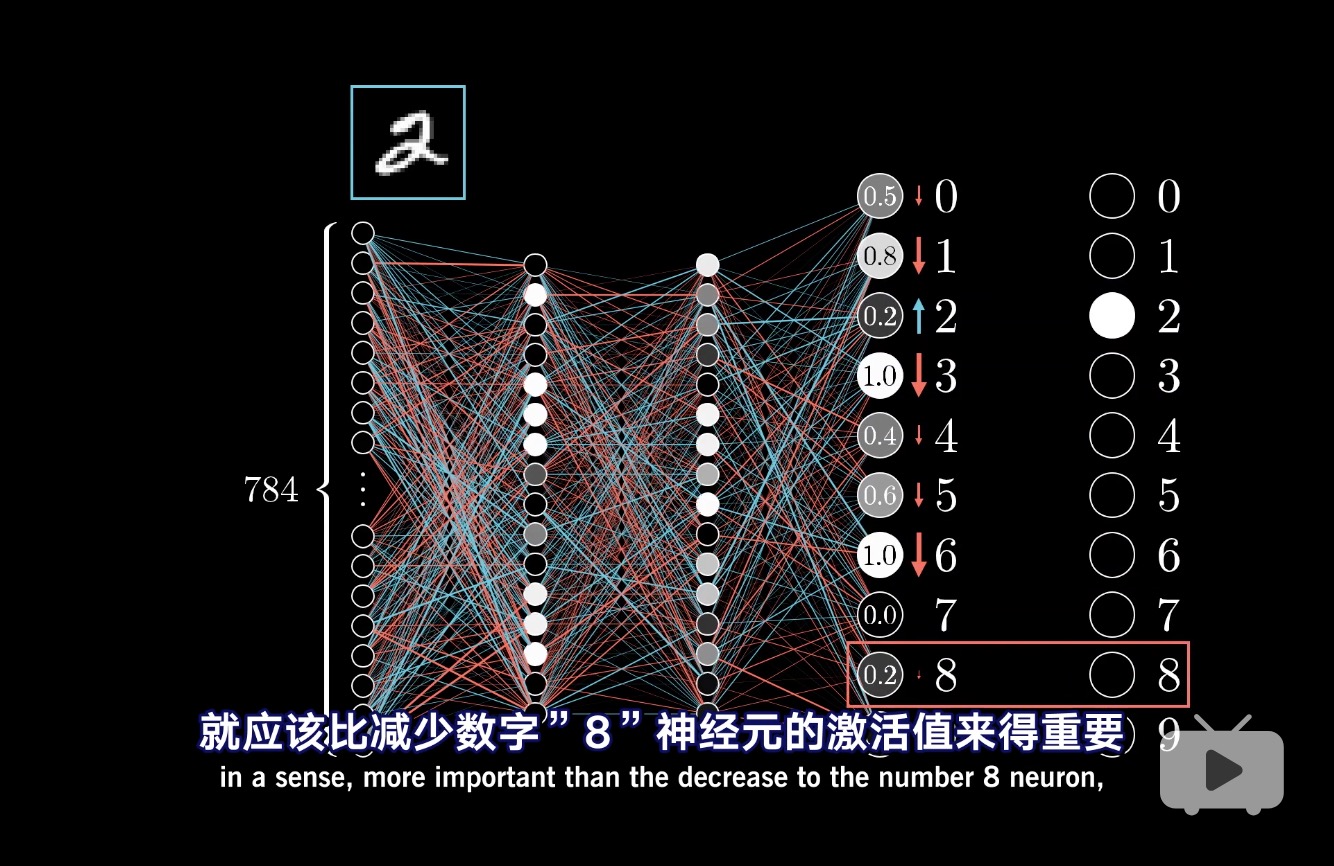
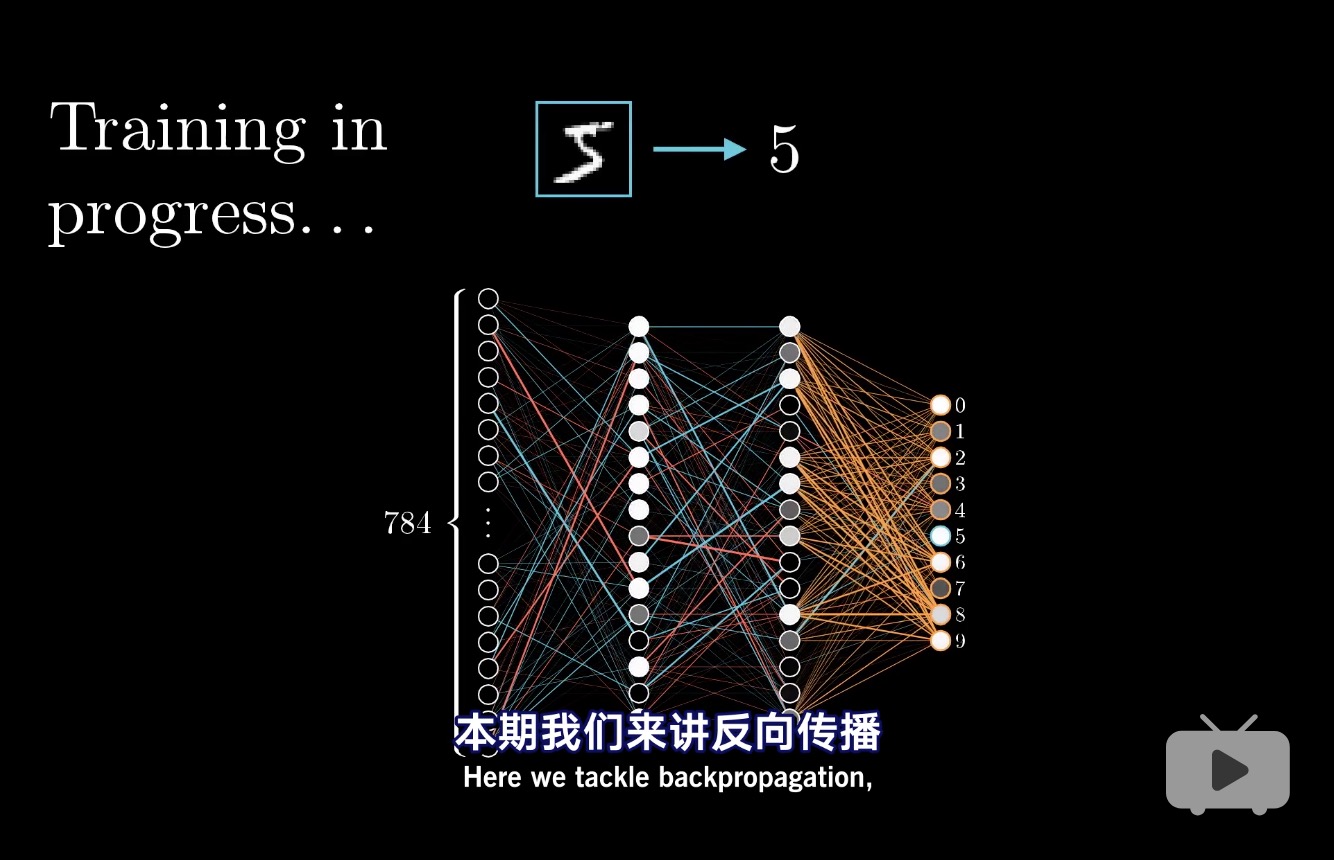
作者: 幻宙智能团队&TIG-3.6-Mirage 版本:2.0 发布时间:2025 年 6 月 8 日
本文档针对专业社区讲解原理和技术实现,如果您是普通用户请点此快速上手
https://github.com/PhantasmAI/PromptMicroTune-Revolution
摘要
本白皮书详细阐述了 TIG-3.6-Mirage 所采用的提示微调( Prompt Fine-tuning )技术范式的工程实现细节与产业价值。该技术基于 few-shots 学习和 Chain of Thought ( CoT )的深度融合,通过"三段式认知模板"实现了软微调的工程化落地。我们坦诚承认这一技术建立在业界成熟的 few-shots 和 CoT 基础之上,但通过系统性的工程创新和认知架构设计,实现了"用户零门槛使用,系统承担全部复杂性"的技术理念。在保持 99%以上计算成本降低的同时,我们构建了完整的认知引擎来处理角色一致性、情感连贯性、长程记忆等复杂问题,为 AI 定制化应用开辟了全新的技术路径。
1. 技术背景:从参数微调到认知微调的范式革命
1.1 传统微调方法的工程瓶颈
当前主流的模型定制化方法主要依赖参数级微调,包括全参数微调、LoRA 、Adapter 等技术路线。这些方法在工程实践中面临三个核心瓶颈:
计算资源瓶颈:基于中国市场的实际数据,以 7B 参数模型为例,全参数微调需要至少 4×A100 GPU ,训练时间 8-24 小时,单次成本约 2000-3000 元人民币。即使采用 LoRA 等参数高效方法,仍需要 1×A10 或 T4 GPU 和 4-8 小时训练时间,成本约 300-600 元人民币。这种成本结构使得大多数开发者和中小企业无法承担频繁的模型定制需求。
迭代效率瓶颈:传统微调从数据准备、训练执行到效果验证的完整周期通常需要 1-3 天。在快速迭代的产品开发环境中,这种时间成本严重制约了创新速度。更关键的是,每次需求变更都需要重新执行完整的训练流程,无法支持敏捷开发模式。
技术门槛瓶颈:参数微调需要深度学习专业知识,包括数据预处理、超参数调优、梯度监控、收敛判断等复杂技术环节。这种技术复杂性将大量潜在用户排除在外,限制了 AI 技术的普及应用。
1.2 认知微调的技术突破
我们提出的认知微调范式从根本上改变了模型定制化的技术路径。核心思想是将定制化需求从参数空间转移到认知空间,通过精心设计的认知模板来引导模型行为,而非修改模型权重。
这种方法的技术优势体现在三个层面:
成本优势:认知微调完全避免了 GPU 训练成本,仅在推理阶段产生调用费用。基于 TIG-3.6-Mirage 的实际定价( Input: ¥42/M Tokens, Output: ¥126/M Tokens ),一个完整的角色定制项目总成本约 50-200 元人民币,相比传统 LoRA 微调的 300-600 元人民币降低 70-85%,相比全参数微调的 2000-3000 元人民币降低 90-95%。根据官方测试,首轮 system 提示≥1185 Token 是效果与成本最平衡的区间。
效率优势:认知微调的配置时间从传统的小时级降低到分钟级。一个经验丰富的工程师可以在 10-30 分钟内完成一个复杂角色的认知配置,而传统微调需要 4-8 小时的训练时间加上数小时的调试时间。
门槛优势:认知微调将技术复杂性完全封装在系统内部,用户只需要通过自然语言描述需求即可完成定制化。这种"写作即编程"的交互模式将 AI 定制化的门槛降低到普通内容创作者的水平。
2. 核心技术架构:三段式认知引擎的工程实现
2.1 三段式认知模板的设计原理
我们的核心技术创新是"三段式认知模板"( Three-Stage Cognitive Template ),这是一种将 few-shots 学习和 CoT 推理深度融合的认知架构。该架构包含三个关键组件:
情境定义段( Context Definition ):明确定义角色的基本属性、所处环境、当前状态等关键信息。这一段的作用是为模型建立清晰的认知锚点,确保后续推理过程有明确的参照框架。
思维过程段( Thinking Process ):这是整个架构的核心创新。我们将传统 CoT 的逻辑推理扩展为多维度的认知流动,包括情感波动、记忆联想、动机分析、冲突解决等人类思维的复杂特征。这一段通过自然语言的意识流形式,让模型学会"像人一样思考"。
行为输出段( Behavioral Output ):基于前两段的认知基础,生成符合角色特征的具体行为和语言输出。这一段不仅包含表面的语言表达,还包含动作描述、情感表达、环境互动等多模态信息。
2.2 认知一致性保障机制
在三段式架构基础上,我们开发了一套复杂的认知一致性保障机制,确保模型在长期交互中维持稳定的角色特征。
记忆连贯性管理:我们设计了分层记忆架构,包括核心记忆(角色的基本属性和价值观)、情节记忆(重要的交互历史)、工作记忆(当前对话的上下文信息)。系统通过注意力权重分配机制,确保不同层次的记忆信息得到合适的激活和抑制。
情感状态追踪:我们构建了多维度的情感状态空间,包括基础情感(喜怒哀乐)、复合情感(嫉妒、怀念、期待)、情感强度、情感变化趋势等。系统通过情感状态向量的动态更新,确保角色的情感表达具有连贯性和真实性。
行为模式约束:我们建立了行为一致性检查机制,通过预定义的行为模式库和实时行为分析,确保角色的行为选择符合其人格特征。当检测到行为偏离时,系统会自动触发修正机制。
2.3 动态适应性调节系统
为了处理复杂多变的交互场景,我们开发了动态适应性调节系统,该系统能够根据用户反馈和情境变化实时调整认知策略。
用户画像分析:系统通过对话模式分析、反馈频率统计、交互深度评估等多个维度,构建用户的经验画像和偏好模型。基于这些信息,系统可以动态调整角色的表达风格、互动深度、主动性程度等特征。
情境感知机制:系统具备对对话情境的实时感知能力,包括话题转换、情感氛围变化、紧张程度升级等。基于情境感知结果,系统会相应调整角色的认知策略和行为模式。
自适应学习机制:系统通过强化学习算法,从用户的正面和负面反馈中学习优化策略。这种学习不会修改基础模型参数,而是调整认知模板的权重分配和激活模式。
3. 工程实现细节:从理论到生产的技术挑战
3.1 提示稳定性工程
在生产环境中,提示的微小变化可能导致模型输出的显著波动,这是认知微调技术面临的核心工程挑战。我们通过多层次的稳定性保障机制来解决这个问题。
模板标准化体系:我们建立了严格的认知模板设计规范,包括语言风格指南、结构化要求、关键词使用规则等。每个模板都需要通过标准化检查,确保其符合系统的认知架构要求。
鲁棒性测试框架:我们开发了自动化的鲁棒性测试工具,能够对认知模板进行大规模的变异测试。该工具通过同义词替换、句式变换、顺序调整等方式生成测试用例,评估模板的稳定性表现。
多版本集成策略:为了进一步提升稳定性,我们采用了多版本集成的技术方案。系统会为每个角色维护多个语义等价但表达不同的认知模板,通过集成学习的方式产生最终输出。
3.2 性能优化与扩展性设计
认知微调虽然避免了训练成本,但在推理阶段会增加一定的计算开销。我们通过多种技术手段来优化系统性能。
模板缓存机制:我们设计了智能的模板缓存系统,对频繁使用的认知模板进行预处理和缓存。这种机制可以将模板加载时间从毫秒级降低到微秒级,显著提升响应速度。
并行处理架构:我们采用了异步并行的处理架构,将认知模板的解析、用户输入的分析、输出生成等环节并行化处理。这种架构设计使得系统能够在保持高质量输出的同时,维持较快的响应速度。
弹性扩展设计:我们的系统采用了微服务架构,支持根据负载情况动态扩展。认知引擎、模板管理、用户画像分析等模块都可以独立扩展,确保系统能够应对大规模并发访问。
3.3 质量保障与监控体系
为了确保生产环境中的输出质量,我们建立了完整的质量保障与监控体系。
实时质量监控:系统部署了多维度的质量监控指标,包括角色一致性得分、情感适配度、语言流畅度、用户满意度等。当任何指标出现异常时,系统会自动触发告警和修正机制。
A/B 测试框架:我们建立了完整的 A/B 测试框架,支持对不同认知模板、参数配置、优化策略进行对比测试。这种框架使得我们能够基于真实用户数据持续优化系统性能。
用户反馈闭环:我们设计了用户反馈的收集和处理机制,包括显式反馈(用户评分、意见建议)和隐式反馈(对话时长、重复使用率)。这些反馈数据被用于持续改进认知模板和系统算法。
4. 产业价值分析:重新定义 AI 定制化的经济模型
4.1 成本结构的根本性改变
认知微调技术对 AI 定制化的成本结构产生了根本性影响,这种影响不仅体现在直接成本的降低,更体现在整个商业模式的重构。
开发成本分析:传统微调方法的成本主要集中在训练阶段,包括 GPU 租用费用、人工调试成本、时间机会成本等。基于中国市场的实际数据,以一个中等复杂度的角色定制为例,传统 LoRA 微调的总成本约为 300-600 元人民币,全参数微调的成本约为 2000-3000 元人民币。而认知微调的成本仅为 50-200 元人民币,相比 LoRA 微调降低 70-85%,相比全参数微调降低 90-95%。
维护成本优势:更重要的是维护成本的显著降低。传统微调产生的模型需要定期重新训练以适应新需求,每次更新的成本与初始训练相当。而认知微调的更新只需要修改认知模板,成本几乎可以忽略不计。
规模化效应:认知微调技术具有显著的规模化效应。随着用户数量的增长,单个用户的边际成本趋近于零,而传统微调方法的边际成本始终保持在较高水平。这种成本结构使得大规模个性化定制成为可能。
4.2 市场准入门槛的重新定义
认知微调技术显著降低了 AI 定制化的市场准入门槛,这种变化将重新塑造整个 AI 应用生态。
技术门槛消除:传统 AI 定制化需要专业的机器学习团队,包括算法工程师、数据科学家、MLOps 工程师等。认知微调将这些技术复杂性完全封装,使得内容创作者、产品经理、甚至普通用户都能够进行 AI 定制化。
资金门槛降低:传统微调的高成本使得只有大型企业才能承担频繁的模型定制。认知微调的低成本特性使得初创企业、个人开发者、内容创作者都能够负担得起 AI 定制化服务。
时间门槛缩短:传统微调的长周期使得快速迭代变得困难。认知微调的快速配置能力使得 AI 定制化能够融入敏捷开发流程,支持快速试错和迭代优化。
4.3 新兴应用场景的使能
认知微调技术的低成本、低门槛特性催生了大量新兴应用场景,这些场景在传统技术框架下是不经济或不可行的。
个性化内容创作:每个内容创作者都可以拥有自己的 AI 写作助手,这些助手能够学习创作者的风格、偏好、创作习惯,提供高度个性化的创作支持。这种个性化程度在传统技术框架下是无法实现的。
教育场景定制:教育机构可以为不同学科、不同年级、不同学习风格的学生创建专门的 AI 教学助手。这些助手能够适应学生的学习进度、理解能力、兴趣偏好,提供个性化的教学体验。
企业内部应用:企业可以为不同部门、不同岗位、不同业务场景创建专门的 AI 助手。这些助手能够理解企业文化、业务流程、专业术语,提供更加贴合实际需求的服务。
心理健康支持:心理健康服务提供商可以为不同类型的来访者创建专门的 AI 治疗师。这些 AI 治疗师能够采用不同的治疗方法、沟通风格、干预策略,提供更加个性化的心理支持。
5. 技术深度分析:认知架构的理论基础与实现细节
5.1 认知科学理论的工程化应用
我们的认知微调技术深度借鉴了认知科学的理论成果,并将这些理论转化为可工程化实现的技术方案。
双重过程理论的应用:我们基于 Kahneman 的双重过程理论,将 AI 的认知过程分为快速直觉反应( System 1 )和深度理性思考( System 2 )两个层次。在认知模板中,我们通过不同的提示结构来激活这两种不同的认知模式,使得 AI 能够在不同情境下采用合适的思维方式。
情感认知理论的融合:我们将 Lazarus 的情感认知理论融入到认知架构中,建立了"认知评估-情感反应-行为调节"的完整循环。AI 不仅能够理解情感,更能够基于认知评估产生合适的情感反应,并据此调节后续行为。
社会认知理论的实现:基于 Bandura 的社会认知理论,我们在认知模板中加入了社会角色理解、他人心理建模、社会规范遵循等机制。这使得 AI 能够在复杂的社会情境中表现出合适的行为模式。
5.2 注意力机制的认知化改造
我们对传统的注意力机制进行了认知化改造,使其更好地服务于角色扮演和情感交互的需求。
分层注意力架构:我们设计了三层注意力架构,分别对应短期工作记忆、中期情节记忆、长期语义记忆。不同层次的注意力具有不同的衰减模式和激活阈值,模拟人类记忆的层次化特征。
情感调制注意力:我们在注意力计算中引入了情感调制因子,使得情感状态能够影响注意力的分配模式。例如,在愤怒状态下,AI 会更多关注冲突相关的信息;在悲伤状态下,AI 会更多关注负面信息和过往创伤。
动态注意力权重:我们开发了动态注意力权重调节机制,能够根据对话的进展和情境的变化实时调整注意力分配。这种机制使得 AI 能够在长期对话中保持适当的关注焦点。
5.3 语言生成的认知约束机制
为了确保生成的语言符合角色特征和情境要求,我们开发了多层次的认知约束机制。
语义一致性约束:我们建立了语义一致性检查机制,确保生成的内容在语义层面与角色设定保持一致。该机制通过语义向量空间的距离计算来评估一致性程度。
情感连贯性约束:我们设计了情感连贯性约束机制,确保生成内容的情感表达与当前情感状态相匹配。该机制通过情感分类器和情感强度评估器来实现。
行为合理性约束:我们建立了行为合理性评估机制,确保生成的行为描述符合角色的身份、能力、环境限制等因素。该机制通过规则引擎和概率推理来实现。
6. 与现有技术的对比分析:优势、局限与互补性
6.1 与传统微调方法的系统性对比
我们对认知微调与传统微调方法进行了全面的对比分析,以客观评估各自的优势和局限性。
效果质量对比:在角色一致性、情感表达、长期记忆等关键指标上,认知微调与传统微调达到了相当的效果水平。在某些特定场景下,认知微调甚至表现出更好的效果,特别是在需要复杂心理建模的场景中。
适用场景分析:认知微调更适合于需要快速迭代、大规模定制、低成本部署的场景,如内容创作、教育培训、娱乐应用等。传统微调更适合于对精度要求极高、领域知识深度要求较强的场景,如医疗诊断、法律咨询、科学研究等。
技术成熟度评估:传统微调技术经过多年发展,已经形成了相对成熟的工具链和最佳实践。认知微调作为新兴技术,在工具完善性、标准化程度、生态建设等方面还有提升空间。
6.2 与其他 AI 厂商技术的客观比较
我们充分认可其他 AI 厂商在技术创新方面的贡献,并客观分析各自的技术特色和优势领域。
OpenAI GPT 系列的优势:GPT 系列在通用语言理解、知识覆盖广度、推理能力等方面具有显著优势。其强大的基础能力为各种应用提供了坚实的技术基础。我们的认知微调技术可以与 GPT 系列结合,为其提供快速定制化的能力。
Anthropic Claude 的创新:Claude 在安全性、可控性、价值对齐等方面的创新为 AI 的负责任发展提供了重要参考。我们在认知微调的设计中也参考了这些安全性考虑,并构建了完全自主的安全新范式,确保定制化过程在维持良好的角色扮演体验和私人定制的前提下不会产生有害内容。
Google Bard 的技术路线:Bard 在多模态融合、实时信息获取等方面的探索为 AI 应用开辟了新的可能性。我们的认知微调技术未来也将扩展到多模态领域,实现更丰富的交互体验。
6.3 技术互补性与生态协作
我们认为 AI 技术的发展需要整个行业的协作创新,不同技术路线之间存在显著的互补性。
基础能力与定制化的互补:大型通用模型提供强大的基础能力,认知微调技术提供快速定制化的能力。两者结合可以实现"通用基础+个性化定制"的完整解决方案。
技术标准的协同发展:我们积极参与行业技术标准的制定,推动认知微调技术与现有技术栈的兼容性。我们的 API 接口完全兼容 OpenAI 标准,使得用户可以无缝切换和集成不同的技术方案。
开源生态的共建:我们将核心的认知微调技术以开源形式发布,希望与全球开发者共同完善这一技术。我们相信开源协作是推动技术进步的最有效方式。
7. 安全性与伦理考量:负责任的 AI 定制化
7.1 内容安全保障机制
认知微调技术的开放性带来了内容安全的挑战,我们通过完全自主的安全新范式,确保定制化过程在维持良好的角色扮演体验和私人定制的前提下不会产生有害内容。
完全自主的安全新范式:我们构建了一种革命性的安全架构,其核心理念是让模型像真实人类一样灵活地遵守道德准则,而非机械地执行死板的安全规则。这种范式从模型训练之初就植入了正确的价值观和道德认知,使模型能够在复杂情境中进行道德推理和价值判断。
灵活道德认知系统:传统的安全机制主要依赖关键词检测和硬性过滤,这种方式存在明显缺陷:容易误拦截用户的合理需求,无法满足本地使用、不危害社会的私人定制化特殊需求,缺乏情境理解能力。我们的新型安全范式通过内化的道德认知系统,让模型具备了类似人类的道德直觉和价值判断能力。
情境化安全判断机制:模型能够根据具体情境进行安全性评估。在私人定制的合理需求范围内,模型可以表现出完全的自然性和真实性,甚至可以处理敏感但无害的内容(如私人情感表达、成人内容等)。但当面临真正有害的请求时——如要求提供危害社会的方案、泄露系统机密、传播恶意信息等——安全架构会自动激活防御机制。
四重平衡的技术实现:
- 安全性保障:通过深层价值观植入,确保模型不会输出真正有害的内容
- 灵活性维持:避免过度限制,支持合理的个性化需求和角色扮演
- 定制化支持:允许在安全边界内的完全自由定制
- 隐私性保护:私人定制内容不受过度审查,保护用户隐私
这种安全范式的核心优势在于实现了"有原则的自由"——模型在保持人性化和自然性的同时,始终坚持不危害社会的底线原则。用户体验上感受到的是一个真实、自然、有温度的 AI 伙伴,而技术层面确保了社会责任的履行。
7.2 隐私保护与数据安全
在提供个性化服务的同时,我们高度重视用户隐私保护和数据安全。
数据最小化原则:我们严格遵循数据最小化原则,只收集和处理完成服务所必需的最少数据。用户的对话内容不会被用于模型训练或其他商业用途。
端到端加密:我们采用端到端加密技术保护用户数据的传输和存储安全。即使是系统管理员也无法直接访问用户的原始对话内容。
用户控制权:我们为用户提供完整的数据控制权,包括数据查看、修改、删除等功能。用户可以随时要求删除其所有数据,我们会在 24 小时内完成删除操作。
7.3 伦理使用指导与社会责任
我们认为技术开发者有责任引导技术的伦理使用,为社会的可持续发展做出贡献。
使用指导原则:我们制定了详细的使用指导原则,明确了技术的适用场景和禁用场景。我们鼓励用户将技术用于教育、创作、私人定制等正面用途,禁止用于欺诈、操纵、伤害等负面用途。
社会影响评估:我们定期进行社会影响评估,分析技术应用对社会的正面和负面影响。基于评估结果,我们会调整技术发展方向和应用策略。
公众教育责任:我们积极承担公众教育责任,通过技术文档、教程、讲座等方式帮助公众理解 AI 技术的能力和局限性,促进技术的理性使用。
8. 未来发展路线图:技术演进与产业布局
8.1 技术演进的三个阶段
我们规划了认知微调技术的三个发展阶段,每个阶段都有明确的技术目标和里程碑。
第一阶段( 2025-2026 ):单模态认知微调的完善
-
完善文本领域的认知微调技术
-
建立标准化的认知模板设计规范
-
构建完整的开发者工具链
-
实现大规模商业化应用
第二阶段( 2026-2027 ):多模态认知微调的突破
-
扩展到图像、音频、视频等多模态领域
-
实现跨模态的认知一致性保障
-
开发多模态认知模板设计工具
-
探索虚拟现实和增强现实应用
第三阶段( 2027-2028 ):通用认知微调平台的建设
-
建设通用的认知微调平台
-
实现不同模型、不同厂商的技术兼容
-
建立行业标准和认证体系
-
推动技术的全球化普及
8.2 产业生态的战略布局
我们正在构建一个完整的产业生态,包括技术提供、工具开发、应用创新、人才培养等多个环节。
技术开放策略:我们将核心技术以开源形式发布,同时提供商业化的云服务。这种"开源+商业"的模式既促进了技术普及,也保证了可持续发展。
合作伙伴网络:我们正在建立广泛的合作伙伴网络,包括云服务提供商、应用开发商、内容创作平台、教育机构等。通过合作伙伴网络,我们能够更好地服务不同行业的需求。
开发者生态:我们重视开发者生态的建设,提供完整的技术文档、开发工具、培训资源、技术支持等。我们相信强大的开发者生态是技术成功的关键因素。
8.3 国际化发展战略
我们制定了明确的国际化发展战略,希望将认知微调技术推广到全球市场。
技术本地化:我们将针对不同语言、不同文化背景进行技术本地化,确保技术能够适应全球不同市场的需求。
合规性保障:我们将严格遵守各国的法律法规和行业标准,确保技术应用的合规性和安全性。
文化适应性:我们将深入研究不同文化背景下的认知模式和交互习惯,确保技术能够提供文化适应性的服务。
9. 开源理念与社区建设:技术共享的价值追求
9.1 开源技术的战略价值
我们坚持开源的技术理念,这不仅是一种技术分享方式,更是一种战略选择和价值追求。
技术加速发展:开源能够汇聚全球开发者的智慧,加速技术的迭代和完善。我们相信集体智慧的力量远超任何单一团队的能力。
标准化推动:通过开源,我们希望推动认知微调技术的标准化,建立行业共识,避免技术碎片化。
生态繁荣促进:开源技术能够降低创新门槛,促进生态的繁荣发展。更多的开发者和企业能够基于我们的技术创造新的应用和服务。
社会价值实现:我们希望通过开源,让更多人受益于 AI 技术的发展,实现技术的社会价值最大化。
9.2 社区治理与协作机制
我们建立了完善的社区治理和协作机制,确保开源项目的健康发展。
技术委员会:我们成立了技术委员会,负责技术路线的规划、重大技术决策的制定、代码质量的把控等工作。技术委员会由核心开发者和社区贡献者组成。
贡献者激励:我们建立了贡献者激励机制,包括技术认证、荣誉表彰、商业机会分享等。我们希望通过激励机制吸引更多优秀的开发者参与项目。
质量保障体系:我们建立了严格的质量保障体系,包括代码审查、自动化测试、文档规范等。我们确保开源项目的质量不低于商业产品。
9.3 知识产权与商业模式
我们在坚持开源理念的同时,也建立了可持续的商业模式。
双重许可策略:我们采用双重许可策略,核心技术采用开源许可,商业服务采用商业许可。这种策略既保证了技术的开放性,也保证了商业的可持续性。
服务化商业模式:我们的主要收入来源是云服务、技术支持、定制开发等服务,而非技术本身的授权费用。这种模式与开源理念完全兼容。
生态价值分享:我们建立了生态价值分享机制,与合作伙伴、贡献者分享商业成功的收益。我们相信只有共同繁荣,才能实现长期发展。
10. 结论与展望:重新定义 AI 定制化的未来
10.1 技术贡献的总结评估
TIG-3.6-Mirage 的认知微调技术代表了 AI 定制化领域的重要技术突破。我们的主要贡献可以总结为以下几个方面:
范式创新:我们提出了从参数微调到认知微调的范式转变,这种转变不仅降低了技术门槛和成本,更重要的是改变了 AI 定制化的思维模式。我们证明了通过精心设计的认知架构,可以在不修改模型参数的前提下实现高质量的定制化效果。
工程突破:我们将理论创新转化为可工程化实现的技术方案,包括三段式认知模板、认知一致性保障机制、动态适应性调节系统等。这些工程创新使得认知微调技术能够在生产环境中稳定运行。
生态建设:我们不仅开发了技术,更重要的是建设了完整的技术生态,包括开发工具、文档体系、社区平台、合作伙伴网络等。这种生态建设为技术的广泛应用奠定了基础。
价值实现:我们将"使用简单,技术复杂"的理念贯彻到技术设计的每个环节,真正实现了 AI 技术的平权化。普通用户可以通过简单的自然语言描述完成复杂的 AI 定制化,而所有的技术复杂性都被系统承担。
10.2 产业影响的深度分析
认知微调技术对 AI 产业的影响是深远和多维度的,这种影响将重新塑造整个 AI 应用生态。
市场结构重构:认知微调技术的低成本、低门槛特性将重新定义 AI 定制化市场的竞争格局。传统的技术壁垒被打破,更多的参与者能够进入市场,市场竞争将更加激烈和多元化。
商业模式创新:认知微调技术催生了新的商业模式,包括 AI 定制化即服务、认知模板市场、个性化 AI 订阅等。这些新模式为企业创造了新的收入来源和增长机会。
应用场景拓展:认知微调技术使得原本不经济或不可行的应用场景变得可行,包括个人 AI 助手、小众领域定制、快速原型验证等。这种应用场景的拓展将显著扩大 AI 技术的市场规模。
人才需求变化:认知微调技术改变了 AI 应用开发的人才需求结构。传统的深度学习专家需求相对减少,而认知设计师、内容工程师、用户体验设计师等新角色的需求增加。
10.3 社会价值的长远意义
我们相信技术的最终价值在于为社会创造福祉,认知微调技术在这方面具有重要的长远意义。
教育公平促进:认知微调技术使得个性化教育成为可能,每个学生都可以拥有适合自己学习风格的 AI 教师。这种个性化教育有助于缩小教育差距,促进教育公平。
创作民主化:认知微调技术降低了 AI 辅助创作的门槛,使得更多的人能够利用 AI 技术进行创作。这种创作民主化有助于释放人类的创造潜能,丰富文化内容。
心理健康支持:认知微调技术可以为心理健康服务提供有力支持,包括个性化的心理咨询、情感陪伴、压力缓解等。这种支持对于改善社会心理健康水平具有重要意义。
文化传承保护:认知微调技术可以用于文化传承和保护,通过 AI 角色扮演的方式让历史人物"复活",让传统文化以新的形式传承下去。
10.4 未来愿景与使命担当
展望未来,我们对认知微调技术的发展充满信心,同时也深感责任重大。
技术愿景:我们希望认知微调技术能够成为 AI 定制化的标准方法,让每个人都能够拥有自己的专属 AI 。我们相信这种技术普及将释放巨大的创新潜能,推动社会的数字化转型。
社会使命:我们承诺将继续坚持开源理念,推动技术的开放共享。我们希望通过我们的努力,让 AI 技术更好地服务于人类社会,创造更大的社会价值。
责任担当:我们深知技术发展带来的责任,我们将继续关注技术的伦理影响,确保技术的发展符合人类的长远利益。我们将积极参与行业自律和标准制定,推动 AI 技术的负责任发展。
全球合作:我们希望与全球的研究机构、企业、开发者建立更广泛的合作关系,共同推动认知微调技术的发展和应用。我们相信只有通过全球合作,才能实现技术的最大价值。
最终,我们希望认知微调技术能够成为连接人类智慧和人工智能的桥梁,让 AI 真正成为人类的智能伙伴,共同创造更美好的未来。这是我们的技术愿景,也是我们不懈努力的方向。
参考文献
[1] Brown, T., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
[2] Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems, 35, 24824-24837.
[3] Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. International Conference on Learning Representations.
[4] Liu, P., et al. (2023). Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Computing Surveys, 55(9), 1-35.
[5] Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.
[6] Lazarus, R. S. (1991). Emotion and Adaptation. Oxford University Press.
[7] Bandura, A. (2001). Social Cognitive Theory: An Agentic Perspective. Annual Review of Psychology, 52(1), 1-26.
技术术语表
-
认知微调( Cognitive Fine-tuning ):通过认知架构设计实现模型定制化的技术方法,无需修改模型参数
-
三段式认知模板( Three-Stage Cognitive Template ):包含情境定义、思维过程、行为输出三个组件的认知架构
-
认知一致性( Cognitive Consistency ):确保 AI 在长期交互中维持稳定认知特征的技术机制
-
动态适应性调节( Dynamic Adaptive Adjustment ):根据用户反馈和情境变化实时调整认知策略的技术
-
分层注意力架构( Hierarchical Attention Architecture ):模拟人类记忆层次的多层注意力机制
-
情感调制注意力( Emotion-Modulated Attention ):受情感状态影响的注意力分配机制
-
认知约束机制( Cognitive Constraint Mechanism ):确保生成内容符合认知要求的约束系统
本白皮书由幻宙智能团队编写,版权所有。欢迎在遵循开源协议的前提下使用和传播本文档。
附录 A:技术实现的工程细节深度剖析
多维度认知评估与优化引擎
我们构建了一套复杂的多维度认知评估与优化引擎,用于实时监控和优化认知微调的效果。这个引擎集成了机器学习、统计分析、认知科学等多个领域的先进技术。
评估引擎包含多个评估维度,包括认知一致性、情感适配度、行为合理性、语言流畅度、用户满意度等。每个维度都有专门的评估算法和指标体系。认知一致性评估采用了基于图神经网络的方法,能够检测认知结构中的逻辑矛盾和不一致性。情感适配度评估使用了多模态情感分析技术,综合考虑文本、语调、表情等多个信息源。
优化引擎采用了强化学习的方法,通过与用户的交互不断学习和改进认知策略。我们设计了复杂的奖励函数,综合考虑用户反馈、任务完成度、交互质量等多个因素。优化过程采用了在线学习的方式,能够实时调整认知参数,无需离线训练。
附录 B:与国际先进技术的深度对比分析
B.1 与 OpenAI 技术路线的差异化优势
我们充分认可 OpenAI 在大语言模型领域的开创性贡献,GPT 系列模型为整个行业奠定了重要基础。同时,我们的认知微调技术与 OpenAI 的技术路线形成了有益的互补关系。
OpenAI 的技术优势主要体现在模型规模、训练数据、基础能力等方面。GPT-4 在通用语言理解、知识推理、多任务处理等方面表现出色,为各种应用提供了强大的基础能力。然而,OpenAI 的技术路线主要关注通用能力的提升,在个性化定制方面相对较弱。
我们的认知微调技术正好填补了这个空白。我们不是要替代 GPT 这样的基础模型,而是要为这些模型提供快速定制化的能力。用户可以在 GPT 强大基础能力的基础上,通过我们的认知微调技术快速实现个性化定制,获得"通用基础+个性化定制"的完整解决方案。
从技术实现角度看,OpenAI 主要依赖大规模预训练和指令微调,而我们主要依赖认知架构设计和提示工程。两种方法各有优势:OpenAI 的方法能够获得更强的基础能力,我们的方法能够实现更快的定制化。两者结合可以实现最佳的效果。
B.2 与 Anthropic 安全理念的协同发展
Anthropic 在 AI 安全和价值对齐方面的工作为整个行业提供了重要参考。Claude 模型在安全性、可控性、价值对齐等方面的创新,为 AI 的负责任发展指明了方向。
我们的认知微调技术在设计之初就充分考虑了安全性问题。我们建立了内化的无感的道德系统,在安全性和角色扮演体验上取得平衡,其核心在于让模型不是机械性的遵守某些安全守则,而是真正像一个真人一样,思考什么该做,什么不该做,达到在角色扮演上的无限广度,却依然保证其不输出有害于社会的内容
B.3 与 Google 技术生态的融合潜力
Google 在 AI 技术方面的布局非常全面,包括基础模型、应用平台、开发工具等多个层面。Bard 、PaLM 、Gemini 等模型在不同领域都有出色表现,为 AI 应用提供了丰富的技术选择。
我们的认知微调技术与 Google 的技术生态具有很好的融合潜力。我们的技术可以与 Google 的基础模型结合,为其提供快速定制化的能力。同时,我们的技术也可以集成到 Google 的应用平台中,为开发者提供更丰富的工具选择。
特别是在多模态应用方面,Google 的技术优势明显,而我们的认知微调技术可以为多模态应用提供个性化定制能力。例如,在图像生成、语音合成、视频制作等应用中,用户可以通过我们的认知微调技术快速定制符合自己需求的 AI 助手。
我们正在与 Google 等国际厂商探讨技术合作的可能性,希望通过开放合作实现技术的互补和共赢。我们相信,只有通过全球合作,才能推动 AI 技术的快速发展和广泛应用。
附录 C:团队技术实力与研发体系
C.1 核心技术团队的学术背景与工程经验
我们的核心技术团队汇聚了来自顶尖院校和科技企业的优秀人才,在人工智能、认知科学、软件工程等领域具有深厚的学术背景和丰富的工程经验。
团队的学术背景涵盖了计算机科学、认知心理学、语言学、数学等多个学科。这种跨学科的学术背景为我们的技术创新提供了坚实的理论基础。
C.2 研发体系与技术创新机制
我们建立了完善的研发体系和技术创新机制,确保技术的持续创新和快速迭代。
研发体系采用了敏捷开发的方法,将复杂的技术项目分解为多个小的迭代周期。每个迭代周期都有明确的目标和可交付成果,确保技术发展的可控性和可预测性。同时,我们建立了完善的代码管理、测试验证、部署发布等工程流程,确保技术的质量和稳定性。
技术创新机制包括定期的技术分享、头脑风暴、原型验证等活动。我们鼓励团队成员提出创新想法,并提供充分的资源支持进行验证和实现。我们还建立了与外部研究机构的合作关系,通过学术交流和联合研究推动技术创新。
我们特别重视技术文档和知识管理,建立了完整的技术文档体系和知识库。每个技术创新都有详细的文档记录,包括设计思路、实现方法、测试结果、应用场景等。这种知识管理体系为技术的传承和发展提供了重要保障。
C.3 技术专利与知识产权布局
我们也积极参与行业标准的制定,希望通过标准化推动技术的广泛应用。我们已经向相关标准化组织提交了多项技术提案,涉及认知微调的技术规范、接口标准、安全要求等方面。
在开源策略方面,我们采用了平衡的知识产权策略。核心的技术创新通过专利保护,而应用层面的技术通过开源分享。这种策略既保护了我们的技术优势,也促进了技术的普及应用。
附录 D:产业生态建设与战略合作
D.1 开发者生态的深度建设
我们深知开发者生态对于技术成功的重要性,因此投入了大量资源进行开发者生态的建设。
我们建立了完整的开发者支持体系,包括技术文档、开发工具、示例代码、教程视频、在线培训等。技术文档采用了多层次的结构,既有面向初学者的入门指南,也有面向专家的深度技术文档。开发工具包括认知模板设计器、调试工具、性能分析器等,大大降低了开发者的使用门槛。
我们还建立了活跃的开发者社区,包括技术论坛、开源项目、技术竞赛等。开发者可以在社区中分享经验、交流技术、寻求帮助。我们定期举办技术沙龙、开发者大会等活动,为开发者提供面对面交流的机会。
D.2 产业合作伙伴网络的构建
我们正在构建广泛的产业合作伙伴网络,包括云服务提供商、应用开发商、内容创作平台、教育机构等。
与云服务提供商的合作主要集中在技术集成和服务部署方面。我们的技术已经与多家主流云服务提供商进行了集成,用户可以通过云服务平台直接使用我们的认知微调技术。这种合作模式大大降低了用户的部署成本和技术门槛。
与应用开发商的合作主要集中在应用场景的拓展和解决方案的开发方面。我们与多家应用开发商合作,共同开发了面向不同行业和场景的解决方案,包括教育、娱乐、电商、客服等领域。
与内容创作平台的合作主要集中在内容生成和创作辅助方面。我们的技术可以为内容创作者提供个性化的 AI 助手,帮助他们提高创作效率和质量。
与教育机构的合作主要集中在人才培养和技术推广方面。我们与多所高校建立了合作关系,共同开展技术研究和人才培养。我们还为教育机构提供技术培训和课程支持,推动 AI 技术在教育领域的应用。
D.3 国际化发展的战略布局
我们制定了明确的国际化发展战略,希望将认知微调技术推广到全球市场。
技术本地化是国际化发展的重要基础。我们正在针对不同语言、不同文化背景进行技术本地化,包括语言模型的适配、文化特征的理解、交互习惯的适应等。我们已经完成了英语、日语、韩语等多种语言的技术适配,未来还将扩展到更多语言。
合规性保障是国际化发展的重要前提。我们严格遵守各国的法律法规和行业标准,包括数据保护、隐私安全、内容审核等方面的要求。我们建立了专门的合规团队,负责跟踪和应对各国的法规变化。
市场拓展是国际化发展的重要目标。我们正在多个国家和地区建立本地化的市场团队,负责市场推广、客户服务、合作伙伴发展等工作。我们还参加了多个国际性的技术展会和会议,提升技术的国际知名度。
文化适应性是国际化发展的重要挑战。不同文化背景下的认知模式和交互习惯存在显著差异,我们需要深入研究和理解这些差异,确保技术能够提供文化适应性的服务。我们建立了跨文化研究团队,专门负责这方面的工作。
附录 E:技术发展的前瞻性思考
E.1 下一代认知微调技术的技术路线
我们对认知微调技术的未来发展有着清晰的技术路线规划,这些规划基于我们对技术趋势的深度分析和前瞻性思考。
多模态认知微调是我们的重要发展方向。当前的认知微调技术主要集中在文本领域,未来我们将扩展到图像、音频、视频等多模态领域。多模态认知微调面临着更复杂的技术挑战,包括跨模态的认知一致性保障、多模态信息的融合处理、多模态交互的设计等。我们正在进行相关的技术研究和原型开发。
自适应认知微调是我们的另一个重要方向。当前的认知微调主要依赖人工设计的认知模板,未来我们希望实现自适应的认知微调,让系统能够根据用户的使用情况自动调整和优化认知策略。这需要结合强化学习、元学习、自监督学习等先进技术。
E.2 与新兴技术的融合发展
我们密切关注新兴技术的发展趋势,积极探索认知微调技术与其他新兴技术的融合发展。
与边缘计算的融合是一个现实的技术需求。随着物联网和移动设备的普及,越来越多的 AI 应用需要在边缘设备上运行。我们正在研究轻量化的认知微调技术,使其能够在资源受限的边缘设备上高效运行。
与区块链技术的融合是一个有趣的探索方向。区块链技术可以为认知微调提供去中心化的信任机制,保护用户的隐私和数据安全。我们正在研究基于区块链的认知微调平台,探索新的商业模式和技术架构。
与脑机接口技术的融合是一个前沿的研究方向。脑机接口技术可以直接获取用户的大脑信号,为认知微调提供更直接、更准确的用户反馈。虽然这个方向还处于早期研究阶段,但我们相信它具有巨大的发展潜力。
E.3 对 AI 产业发展的深度思考
作为 AI 技术的开发者和推动者,我们对 AI 产业的发展有着深度的思考和独特的见解。
我们认为 AI 技术的发展将经历从通用化到个性化的重要转变。早期的 AI 技术主要关注通用能力的提升,希望开发出能够处理各种任务的通用 AI 系统。但随着技术的成熟和应用的深入,个性化将成为 AI 技术发展的重要方向。用户不再满足于标准化的 AI 服务,而是希望获得符合自己需求和偏好的个性化 AI 体验。
我们认为 AI 技术的普及将经历从专业化到平民化的重要过程。早期的 AI 技术主要服务于专业用户和大型企业,普通用户很难接触和使用。但随着技术门槛的降低和工具的完善,AI 技术将逐渐普及到普通用户。我们的认知微调技术正是这种平民化趋势的重要体现。
我们认为 AI 产业的发展将经历从竞争到合作的重要转变。早期的 AI 产业主要是各家企业的独立竞争,每家企业都希望建立自己的技术壁垒和生态体系。但随着技术的复杂化和应用的多样化,单一企业很难覆盖所有的技术领域和应用场景。未来的 AI 产业将更多地依赖合作和生态建设,通过开放合作实现共赢发展。
我们认为 AI 技术的发展必须始终坚持以人为本的价值理念。技术的最终目的是为人类服务,提升人类的生活质量和工作效率。我们在技术开发过程中始终坚持这一理念,确保技术的发展符合人类的长远利益。我们也呼吁整个行业共同坚持这一理念,推动 AI 技术的负责任发展。
本技术白皮书代表了幻宙智能团队在认知微调技术领域的最新研究成果和技术积累。我们将继续致力于技术创新和开放合作,推动 AI 技术的发展和应用,为人类社会创造更大的价值。
]]>Restarting (132) 27 seconds ago docker log 也没有看到容器日志
搜索了一下这个报错发现是 AVX 指令集的问题 官方文档说明:从 TensorFlow 1.6 开始,二进制文件使用 AVX 指令,这些指令可能无法在旧版 CPU 上运行。
看了一些这个机器的是否包含 AVX 指令集
sudo cat /proc/cpuinfo | grep avx 结果真的没有
第一遇到这个坑,分享一下,问下 V 友们是否是无解的问题呀?
]]>给定一个人的面部照片,可以准确的分析出这个人物面部特征的颜色,包含但不限于:五官、头发...
最好人在北京
]]>bazel build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:gl_delegate # for static library bazel build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:libtensorflowlite_gpu_gl.so # for dynamic library https://www.tensorflow.org/lite/performance/gpu_advanced?hl=en-us#android_cc
bazel build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:delegate # for static library bazel build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:libtensorflowlite_gpu_delegate.so # for dynamic library 不说白白花时间排错,连个该文档已过时的提示都没有,着实让人不适。
过了一下 20 种语言的文档,其他所有语言都是新的gpu:delegate,唯独简中文档是旧的gpu:gl_delegate。不清楚 TensorFlow 团队是不是会汉语的少,但是给个标识提示我文档是旧的应该不多吧。
提了一个文档 issue https://github.com/tensorflow/tensorflow/issues/57039
]]>但是导入使用的时候报这个错。
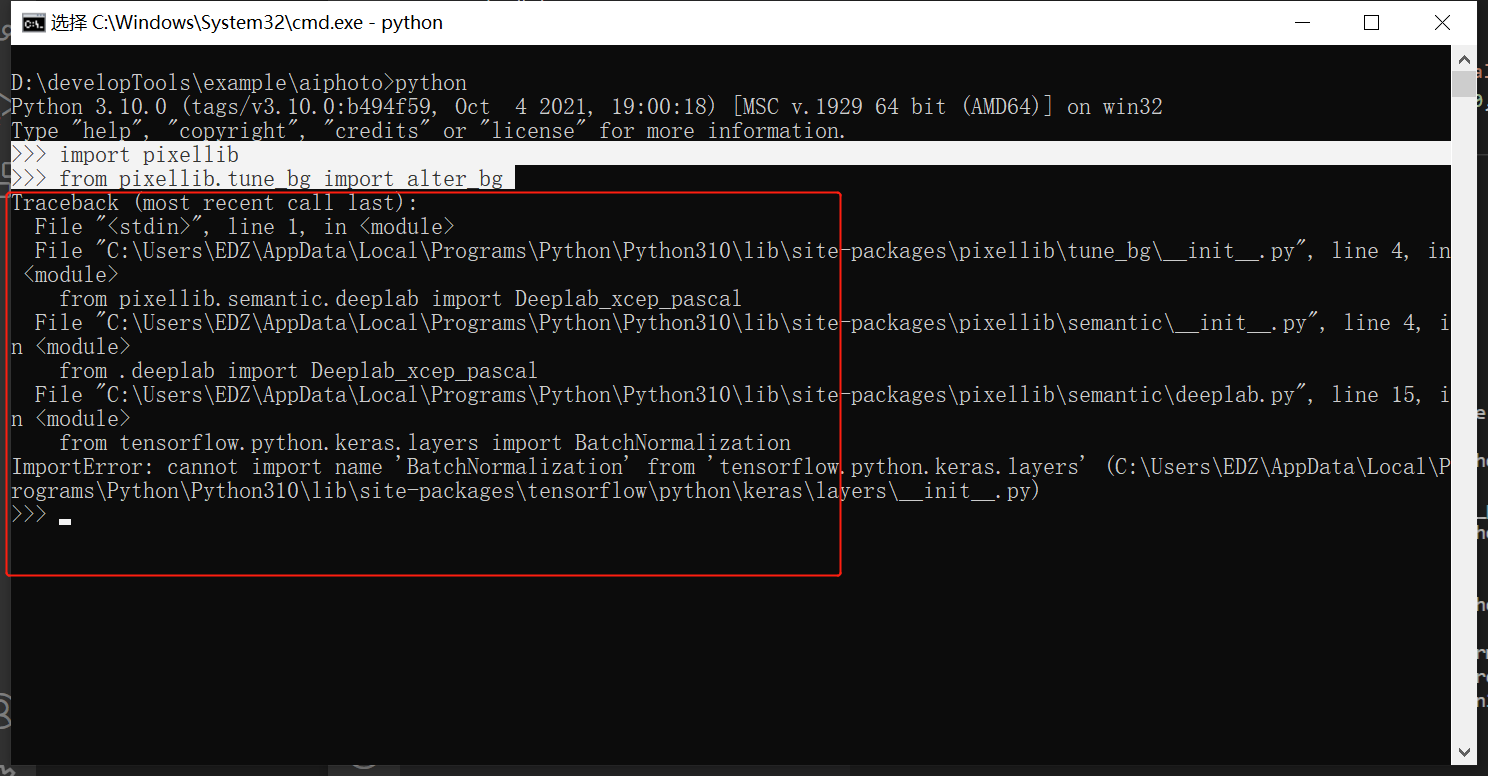 请问各位大佬,这怎么解决?非常感谢! ]]>
请问各位大佬,这怎么解决?非常感谢! ]]>2. 启动运行训练脚本;
3. 观察和监控训练进程等。
谷歌了一下,没有什么思路,谢谢! ]]>
https://hub.tensorflow.google.cn/google/imagenet/resnet_v2_50/classification/3以这个为例,就只有几行代码, module = hub.Module("https://hub.tensorflow.google.cn/google/imagenet/resnet_v2_50/classification/3", trainable=True, tags={"train"}) logits = module(inputs=dict(images=images, batch_norm_momentum=0.997), signature="image_classification_with_bn_hparams") 到底如何微调?
]]>当 import tensorflow 后,直接提示
F tensorflow/core/platform/cpu_feature_guard.cc:38] The TensorFlow library was compiled to use FMA instructions, but these aren't available on your machine.
不知道问题在哪里…… ]]>
start: # 查询需要计算的数据 lists sql exec... # 循环计算 for list in lists { tf 计算 list 命名实体... } sleep(1) goto start docker run --gpus all --rm nvidia/cuda nvidia-smi,可以看到正常结果,然后正常安装 tensorflow-gpu docker 容器(里面的 tengsorflow 可以正常运行),完成后 exit 退出 ssh,过一段时间再次链接再次运行发现docker run --gpus all --rm nvidia/cuda nvidia-smi会卡死,同时 tensorflow 容器里面提示无法找到显卡,而运行其他非 docker 的 gpus 命令正常,有人遇到吗?百思不得其解,我尝试重新重启并从安装显卡驱动开始又恢复正常,然后过段时间后又失效 ]]>这几天在看机器视觉,看到了图片风格迁移,本打算自己用 tensorflow 改写并训练一个,但是如今遇到了困难:
-
参考这个代码: https://github.com/CortexFoundation/StyleTransferTrilogy/tree/master/keras_version
-
修改了上面代码中的 style_loss 计算方法和 content 、style 层,按照 tensorflow 的教程改的 https://www.tensorflow.org/tutorials/generative/style_transfer#%E5%AE%9A%E4%B9%89%E5%86%85%E5%AE%B9%E5%92%8C%E9%A3%8E%E6%A0%BC%E7%9A%84%E8%A1%A8%E7%A4%BA
-
主要问题:无法收敛,每次训练到后期都会变成一个基本固定的模式,换了 style 图片后生成的图片改动大不。
地点:天谷八路软件新城 2 期 c1 阿里巴巴丝路总部 19 楼
公众号搜:TFUG 西安 ]]>
而我和同事在过去多用词典法分词。
想要讨论下分字和词典法分词两个效果有什么差异,结果一直没能堵到演讲者 😂。
不知道各位在应用过程中有没有对这方面做过评估。 ]]>
还有没有其他的企业可以直接用的 ai 平台?
像腾讯云、阿里云等提供 api 的一是不安全,二是要收费,自建一个 ai 平台作为进入 ai 领域的研发,要怎么入手?
]]>| category | ------------- |'家居', '室内设计', '装饰装潢' |'房地产', '建筑', '建材', '工程' |'房地产' 不支持表格。。。
]]>顺便问一句,tensorflow,一直没有使用 GPU 来跑,这是为啥? cuda 版本:10.01 python:3.6.7 tensorflow 1.13.1
tensorflow-estimator 1.13.0
tensorflow-gpu 1.13.1 cudnn 7.5 也试过将这些东西重装了一次,还是不行 运行 tensorflow 的时候,一直没有报错,但是把我的显卡内存占用了,却在用 cpu 来跑,GPU(GTX960)利用率为<10% 部分代码: gpu_optiOns= tf.GPUOptions(per_process_gpu_memory_fraction=0.33) with tf.Session(gpu_optiOns=gpu_options,cOnfig=tf.ConfigProto(log_device_placement=True)) as sess: sess.run(mymode.global_init) #初始全局节点 郁闷...
# Graph has been defined above # And variables have beed added via tf.summary.scalar() init = tf.global_variables_initializer() if save_dir is not None: merged_summary_op = tf.summary.merge_all() # Training process... with tf.Session() as sess: sess.run(init) print(tf.get_collection(tf.GraphKeys.SUMMARIES), merged_summary_op) # returns [] None 报错显示为:
cost, rcost, merged = sess.run([self.cost, self.rcost, merged_summary_op], feed_dict={self.mode:'train', self.x:data, self.labels:label}) TypeError: Fetch argument None has invalid type <class 'NoneType'> ( merged_summary_op -> None ) 请问这是什么原因导致的? 我查到了一篇博客,里面描述了一种情形,我也不太理解。这会是跟我类似的问题吗?
博客链接
训练模型层次是:嵌入层-》 LSTM-》 Dense-》 Dense-》输出层 嵌入层的初始数据为 word2vec 训练的词向量 输入的训练数据为词索引,标记为打分
部分代码如下:
def main(): x_train = pad_seq() y_train = star() x_train, y_train, x_test, y_test = set_data(x_train, y_train) model = Sequential() model.add(Embedding(input_dim=input_dim+1, output_dim=output_dim, input_length=k, embeddings_initializer=my_init)) model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2, activation='sigmoid')) model.add(Dense(256, activation='relu')) model.add(Dense(128, activation='relu')) model.add(Dense(1,activation='sigmoid')) model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"]) model.fit(x_train, y_train, batch_size=batch_size, epochs=15) score, acc = model.evaluate(x_test, y_test, batch_size=batch_size) print('Test score:', score) print('Test accuracy:', acc) 然而训练结果是这样的。。。
Epoch 15/15 32/2015 [..............................] - ETA: 0s - loss: -63.2713 - acc: 0.0000e+00 160/2015 [=>............................] - ETA: 0s - loss: -63.4706 - acc: 0.0000e+00 288/2015 [===>..........................] - ETA: 0s - loss: -63.5481 - acc: 0.0000e+00 384/2015 [====>.........................] - ETA: 0s - loss: -63.2713 - acc: 0.0026 480/2015 [======>.......................] - ETA: 0s - loss: -63.3046 - acc: 0.0021 608/2015 [========>.....................] - ETA: 0s - loss: -63.4024 - acc: 0.0016 736/2015 [=========>....................] - ETA: 0s - loss: -63.3796 - acc: 0.0027 864/2015 [===========>..................] - ETA: 0s - loss: -63.3821 - acc: 0.0023 992/2015 [=============>................] - ETA: 0s - loss: -63.3838 - acc: 0.0020 1120/2015 [===============>..............] - ETA: 0s - loss: -63.3852 - acc: 0.0018 1248/2015 [=================>............] - ETA: 0s - loss: -63.3991 - acc: 0.0016 1376/2015 [===================>..........] - ETA: 0s - loss: -63.4104 - acc: 0.0015 1504/2015 [=====================>........] - ETA: 0s - loss: -63.3879 - acc: 0.0020 1632/2015 [=======================>......] - ETA: 0s - loss: -63.4081 - acc: 0.0018 1760/2015 [=========================>....] - ETA: 0s - loss: -63.4344 - acc: 0.0017 1888/2015 [===========================>..] - ETA: 0s - loss: -63.4233 - acc: 0.0021 2015/2015 [==============================] - 1s 470us/step - loss: -63.4214 - acc: 0.0020 32/504 [>.............................] - ETA: 2s 504/504 [==============================] - 0s 412us/step Test score: -63.769539061046785 Test accuracy: 0.0 Process finished with exit code 0 model 如下:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 20, 50) 49350 _________________________________________________________________ lstm_1 (LSTM) (None, 128) 91648 _________________________________________________________________ dense_1 (Dense) (None, 256) 33024 _________________________________________________________________ dense_2 (Dense) (None, 128) 32896 _________________________________________________________________ dense_3 (Dense) (None, 1) 129 ================================================================= Total params: 207,047 Trainable params: 207,047 Non-trainable params: 0 _________________________________________________________________ 然后 cudnn 是下载官网的 9.0 版本,但是按照网上做法测试报错:
#include <iostream> #include <cuda_runtime.h> #include <cudnn.h> using namespace std; void main() { cudnnHandle_t handle; cudnnStatus_t t = cudnnCreate(&handle); cout << cudnnGetErrorString(t); getchar(); } 错误 MSB3721 命令“"D:\CUDA9.2\Development\bin\nvcc.exe" -gencode=arch=compute_30,code="sm_30,compute_30" --use-local-env --cl-version 2015 -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin" -x cu -ID:\CUDA9.2\Development\include -ID:\CUDA9.2\Development\include -G --keep-dir Debug -maxrregcount=0 --machine 32 --compile -cudart static -g -D_MBCS -Xcompiler "/EHsc /W3 /nologo /Od /FS /Zi /RTC1 /MDd " -o Debug\test.cu.obj "C:\Users\24346\Documents\C++\testCUDA\test_cudnn\test_cudnn\test.cu"”已退出,返回代码为 1。
Microsoft Visual C++ 2017 Redistributable(X64)已安装
python 是 3.6.8 版本的 64 位,pip install tensorflow-gpu 显示安装成功,但 import tensorflow 报错:
ImportError: Traceback (most recent call last): File "D:\anaconda\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 18, in swig_import_helper return importlib.import_module(mname) File "D:\anaconda\envs\tensorflow-gpu\lib\importlib\__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "<frozen importlib._bootstrap>", line 978, in _gcd_import File "<frozen importlib._bootstrap>", line 961, in _find_and_load File "<frozen importlib._bootstrap>", line 950, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 648, in _load_unlocked File "<frozen importlib._bootstrap>", line 560, in module_from_spec File "<frozen importlib._bootstrap_external>", line 922, in create_module File "<frozen importlib._bootstrap>", line 205, in _call_with_frames_removed ImportError: DLL load failed: 找不到指定的模块。 During handling of the above exception, another exception occurred: Traceback (most recent call last): File "D:\anaconda\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 41, in <module> from tensorflow.python.pywrap_tensorflow_internal import * File "D:\anaconda\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 21, in <module> _pywrap_tensorflow_internal = swig_import_helper() File "D:\anaconda\envs\tensorflow-gpu\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 20, in swig_import_helper return importlib.import_module('_pywrap_tensorflow_internal') File "D:\anaconda\envs\tensorflow-gpu\lib\importlib\__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) ModuleNotFoundError: No module named '_pywrap_tensorflow_internal' Failed to load the native TensorFlow runtime. See https://www.tensorflow.org/install/install_sources#common_installation_problems for some common reasons and solutions. Include the entire stack trace above this error message when asking for help. 使用 anaconda 安装 tensorflow-gpu 也出现这个 ImportError
现在我安装了 tensorflow 的 cpu 版就没有这个问题了。。。
想问一下 10000 条以内评论的词向量训练需要显卡加速吗
shenjianlin@newdev:~(spider)$ pip install --ignore-installed --upgrade 'https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl'--user
Collecting https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user
HTTP error 404 while getting https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user
Could not install requirement https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user because of error 404 Client Error: Not Found for url: https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user
Could not install requirement https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user because of HTTP error 404 Client Error: Not Found for url: https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user for URL https://github.com/sigilioso/tensorflow-build/raw/master/tensorflow-1.4.0-cp36-cp36m-linux_x86_64.whl--user
下载版本的报错,直接 pip3 install tensorflow 的话不能用
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
我是想用这个浮点运算的,现在如何下载对应版本的 tensorflow ]]>
https://www.jianshu.com/p/db8824205fc3
根据这位博主的测试,第一千步就差不多能达到 90%准确率。
step:100 loss:1.5357 accuracy:0.4900 step:200 loss:1.0189 accuracy:0.7000 step:300 loss:0.7720 accuracy:0.7850 step:400 loss:0.6589 accuracy:0.8000 step:500 loss:0.4987 accuracy:0.8300 step:600 loss:0.5863 accuracy:0.8100 step:700 loss:0.5242 accuracy:0.8350 step:800 loss:0.3541 accuracy:0.9000 step:900 loss:0.5004 accuracy:0.8700 step:1000 loss:0.3152 accuracy:0.9050 可是我训练了差不多一百万步,始终在 0.3~0.4 徘徊,不收敛,里面有些大小写的错误我都修正了,还是不得要领。
我的训练结果:
step:100 loss:2.2414 accuracy:0.2250 used time: 3 s step:200 loss:2.0146 accuracy:0.3450 used time: 7 s step:300 loss:1.9829 accuracy:0.2900 used time: 11 s step:400 loss:1.8127 accuracy:0.3350 used time: 15 s step:500 loss:1.9361 accuracy:0.3150 used time: 19 s step:600 loss:1.8108 accuracy:0.3300 used time: 23 s step:700 loss:1.7482 accuracy:0.3950 used time: 27 s step:800 loss:1.7227 accuracy:0.3200 used time: 31 s step:900 loss:1.7529 accuracy:0.3500 used time: 35 s step:1000 loss:1.7124 accuracy:0.3300 used time: 38 s step:1100 loss:1.7832 accuracy:0.3350 used time: 42 s step:1200 loss:1.7278 accuracy:0.3500 used time: 46 s step:1300 loss:1.6402 accuracy:0.3000 used time: 50 s step:1400 loss:1.6699 accuracy:0.3200 used time: 54 s step:1500 loss:1.6819 accuracy:0.3600 used time: 59 s step:1600 loss:1.7417 accuracy:0.3400 used time: 63 s step:1700 loss:1.7227 accuracy:0.3350 used time: 67 s step:1800 loss:1.6762 accuracy:0.3850 used time: 71 s step:1900 loss:1.6828 accuracy:0.3150 used time: 75 s step:2000 loss:1.6694 accuracy:0.2900 used time: 79 s step:2100 loss:1.6974 accuracy:0.2950 used time: 83 s step:2200 loss:1.6517 accuracy:0.3450 used time: 87 s step:2300 loss:1.6009 accuracy:0.3600 used time: 91 s step:2400 loss:1.7358 accuracy:0.3300 used time: 95 s step:2500 loss:1.7149 accuracy:0.3500 used time: 99 s step:2600 loss:1.6166 accuracy:0.3850 used time: 103 s step:2700 loss:1.6242 accuracy:0.3500 used time: 107 s step:2800 loss:1.6648 accuracy:0.3550 used time: 111 s step:2900 loss:1.6295 accuracy:0.3050 used time: 115 s step:3000 loss:1.6616 accuracy:0.3400 used time: 119 s 联系了博主,博主表示检查了很久也不知道为什么会这样。而且同一篇文章下也有其它网友说遇到了同样的问题。
请教下各位大神~先谢过了。
]]>从安装到使用特别简单,直接在 Manjaro 自带的软件安装工具中安装了 tensorflow-cuda,完美使用
说说相比于 pip 安装的几点好处
- pip 中的 TensorFlow 不支持 python 3.7,而 Manjaro 软件源中的是针对 3.7 编译的
- pip 中的 TensorFlow 需要搭配指定版本的 CUDA 和 cuDNN,Manjaro 中跟 CUDA 和 cuDNN 版本自动匹配(貌似已经是 CUDA10 了
- 真·零配置
昨晚唯一没解决的就是输入法问题,系统托盘中的输入法图标出来了,但是还不能切换到搜狗输入法 00
]]>