1. 要求: 将提供的 Android 录屏视频中出现的题目 选项 解析摘录, 一共 755 个题目输出到一个完整的 Docx 文档中. 如有公式, 则应当以公式格式呈现. 其他干扰信息, 如 DeepSeek 广告等不应出现在解析中. 示例界面: 
视频中存在部分干扰, 如通知消息和界面动画滑动: 
2. 思路
本质上是一个 OCR+结构化提取并输出的过程, 本质上并无太大难度. 难点在于如何提取视频题目帧和结构化的输出. 至于部分干扰(如遮挡等)则可不处理, 由后续对方人工按帧校对.
我的思路如下:
- 读取每帧的画面, 并按前后帧相似度决定是否为稳定帧. 为了速度, 我们可以初步计算每个题目稳定帧之间的帧间隔, 以此为单位进行比较. 除此之外还可以事先截去状态栏和底部导航栏.
- 使用 OCR 对提取的每帧画面进行识别, 我们可以先只保存所有的文字, 后续再处理.
- 当然, 部分 OCR 程序是支持位置识别的, 我们只需要识别"单选", "多选"等字样就知道题目, 下面部分就是选项. 知道"解析"两个字的位置, 下面的部分自然是解析部分. 我们先不设计这种方式.
- 对识别到的文字进行粗略的清洗, 移去明显的广告词和干扰.
- 使用 LLM 进行结构化提取和输出, 为了保障结构化, 需要使用支持
instruct的模型. 对不稳定的模型输出, 自己实现结构化提取是一件很恼火的事情... - 根据模板, 构造 docx 文档.
3. 选型和实现
在下面给出的实现中, 为了保障观感去掉了一些错误处理和判断.
3.1 关键帧提取
import cv2 import os from skimage.metrics import structural_similarity as ssim def extract_static_frames(video_path, output_dir, threshold=0.99): top_crop = 200 bottom_crop = 250 skip_frames = 6 # 每处理一次跳过的帧数 cap = cv2.VideoCapture(video_path) success, prev_frame = cap.read() prev_frame = prev_frame[top_crop:-bottom_crop, :] frame_id = 0 saved_count = 0 while True: success, frame = cap.read() frame = frame[top_crop:-bottom_crop, :] # 转为灰度图做 SSIM gray_prev = cv2.cvtColor(prev_frame, cv2.COLOR_BGR2GRAY) gray_curr = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) score, _ = ssim(gray_prev, gray_curr, full=True) if score > threshold: saved_path = os.path.join(output_dir, f"frame_{frame_id}.jpg") cv2.imwrite(saved_path, prev_frame) saved_count += 1 # 跳过接下来的几帧 for _ in range(skip_frames): cap.read() frame_id += 1 prev_frame = frame frame_id += 1 cap.release() print(f"Saved {saved_count} static frames to: {output_dir}")
对于输入格式为1080x2340@13.88fps 23min共 19154 帧的视频,使用 5800H 需要约 7 分钟处理完成, 最终共保存 855 帧, 基本可以做到一个题目一帧. 有精力的话可以人工从中去掉一些明显不正确的帧, 没有的话后续进行 OCR 时可进行判断.
3.2 OCR
这里我选用paddleocr来做文字识别, 不得不说即开源准确又高的东西还是非常有优势的. 它也能对中英文和公式有较好的识别率. 要识别的界面较为规整, 提取到的文字按行读取即可.
我们首先要采取一个样品, 交由大语言模型生成判断是否是题目的标志question_mark和无用的信息标志useless_mark. 之后就是简单的判断和保存了. 这一步同样不需要做的十分完美. 如下为 OCR 得到的文字样品:
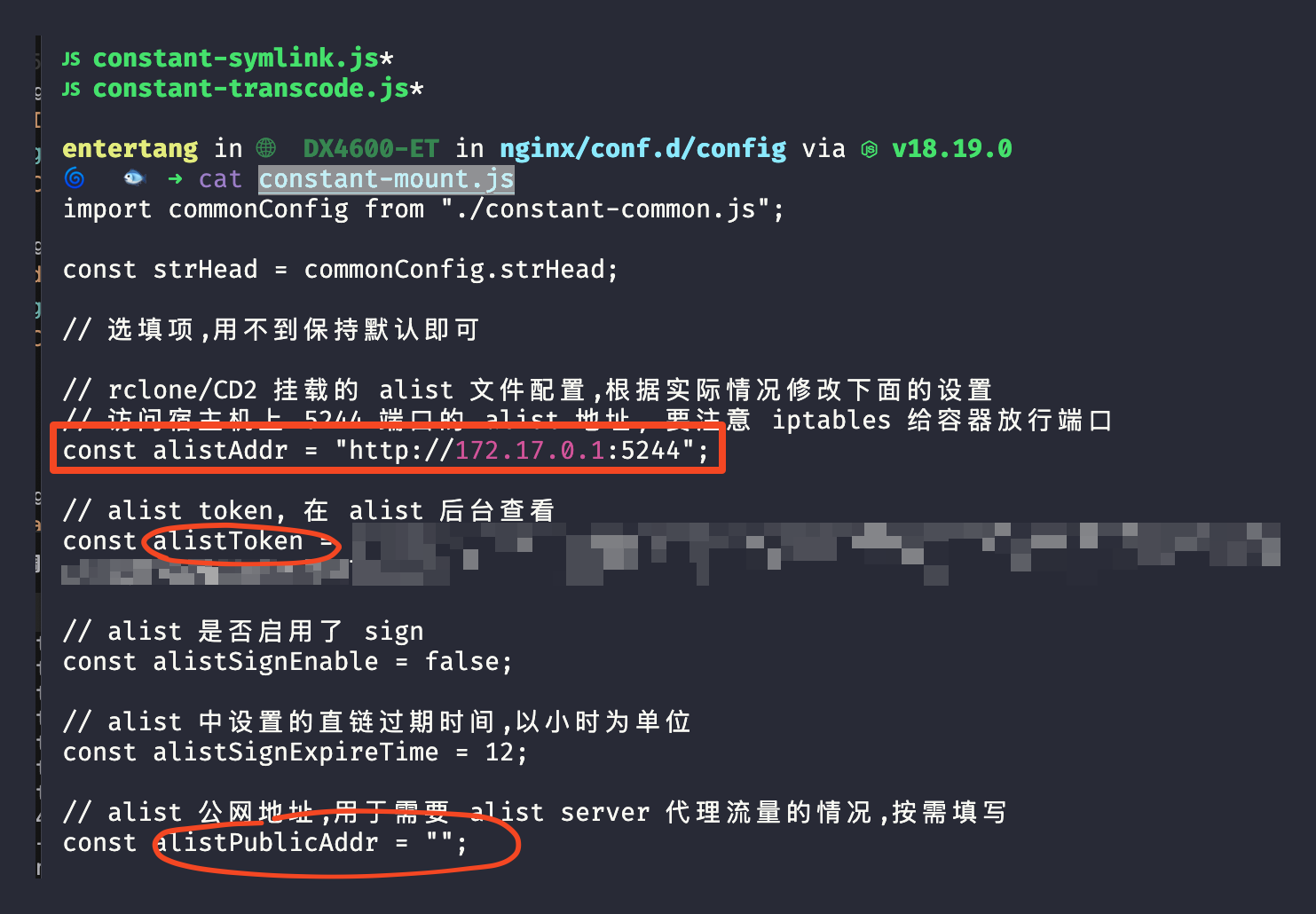
< 0 答题 背题 语音 单选 6 、轻型无人机是指 质量大于 7 千克,但小于等于 116 千克 的无人机,且全马力平飞中,校正空 A 速大于 100 千米/小时(55 海里/小 时),升限大于 3000 米 质量大于等于 7 千克,但小于 116 千克 的无人机,且全马力平飞中,校正空 B 速小于 100 千米/小时( 55 海里/小 时),升限小于 3000 米 空机质量大于 7 千克,但小于等于 116 千克的无人机,且全马力平飞中,校 正空速小于 100 千米/小时 (55 海里/ 小时),升限小于 3000 米 答案 c 试题详解 试题纠错 解析 该题关键点在于空机质量。参考 R1 的重量分 类,微型 0<m≤7kg ,轻型 7<m≤116kg ,小 型 116<m≤5700kg ,m>大型 5700kg 。 755 收藏 答题卡
实现:
def ocr_images_to_markdown(image_dir, output_dir): os.makedirs(output_dir, exist_ok=True) for fname in os.listdir(image_dir): isquestion = False question_mark = ["单选", "判断", "多选"] useless_mark = ["背题", "背题", "语音", "统计", "概述", "来", "难", "度", "使用 DeepSeek ,获取深度思考过程。", "试题详解", "试题纠错", "答题", "背题", "语音", "755"] image_path = os.path.join(image_dir, fname) md_path = os.path.join(output_dir, fname.replace(".jpg", ".md")) result_text = ocr.predict(image_path)[0]['rec_texts'] lines = [] for line in result_text: l = str(line).strip() if l in useless_mark: continue if l in question_mark: # 只有有该行的才视为一个正确的问题帧 isquestion = True lines.append(l) with open(md_path, "w", encoding="utf-8") as f: f.write("\n".join(lines)) print(f"已提取并保存到 {md_path}")
经过处理后, 总共剩余 780 个帧. 这个结果已经足够好了, 钱不够的情况下怎么可能再人工处理呢?
3.3 LLM 处理结构化
对于给钱不够的情况下是不可能使用参数量过大的模型的. 这里我们采用qwen2.5:7b, 由搭载ollama的笔记本就可以运行.
作为小模型的参数量摆在那, 并且计算性能有限, 因而我们输入给他的提示词和用户输入需要尽量精简, 这也是为什么前面要粗略过滤一遍.
为了保障结构化, 我们需要使用第三方库instructor, 使用上十分简单, 我们只需要使用pydantic定义一个回答类即可. instructor的使用能够保障模型的输出格式正确, 但是代价为一定的模型性能下降.
class Answer(BaseModel): options: dict = Field(..., description="题目选项") ## 顺序很重要!! question: str = Field(..., description="题目内容") explanation: str = Field(..., description="题目解析") @field_validator('options') def options_should_have_at_least_two_keys(cls, v): if not all(k in v for k in ["A", "B"]): raise ValueError("选项内容必须包含 A, B 两个选项") return v @field_validator('options') def options_should_not_be_empty(cls, v): if any(not v.get(k) for k in ["A", "B"]): raise ValueError("选项内容不能有空值") return v class Config: json_schema_extra = { "example": { "question": "微型无人机是指?", "options": { "A": "质量小于 7 千克的无人机。", "B": "质量小于等于 7 千克的无人机。", "C": "空机质量小于等于 7 千克的无人机。" }, "explanation": "该题关键点在于空机质量。参考 R1 的质量分类,微型 0<m≤7kg ,轻型 7<m≤116kg ,小型 116<m≤5700kg ,m>大型 5700kg 。。" } }
在使用instructor时, 有一点需要注意: 定义的 Class 类的顺序很重要, 以 3.2 的示例样本为例, 如果按 question -> options -> explanation 的顺序定义类, 模型的输出顺序自然也会按照其进行.
那么, 模型的输出大概率就会变为:
题目: 大型无人机是指空机质量大于 5700kg 的无人机. 选项: A: 空机质量大于 5700kg 的无人机 B: 质量大于 5700kg 的无人机 C: 空机质量大于等于 5700kg 的无人机 解析: 该题关键点在于空机质量。参考 R1 的重量分 类,微型 0<m≤7kg ,轻型 7<m≤116kg ,小 型 116<m≤5700kg ,m>大型 5700kg 。
即便调整提示词也没有作用(如下第一和第二点). 但是按照先 options 再 question 的顺序进行模型就几乎不会出现此问题.
提示词:
system_prompt = """你是一名熟悉考试题目的内容结构化助手。 你需要将用户提供的原始 OCR 文本内容,进行结构化提取,并输出为需要的结构: - 一共三个部分: 题目, 选项, 解析. 正确分辨题目, 选项, 解析内容. - 题目内容中不应包含选项, 题目应当是个问句或需要填空回答的陈述句。 - 两个或三个选项, 分别是 A, B, C. - 保留数学公式,尽量用 LaTeX 格式(如 $x^2 + y^2 = r^2$) - 解析中, 去除无用内容, 如 DeepSeek 成绩 作答等. """
在使用大语言模型进行工程实践时, 顺序和提示词非常重要, 需要反复修改才可达到理想的效果. 在这个调试过程中建议使用如W&B等平台进行记录.
实现:
def process_all_ocr_markdown(input_dir, output_dir, model="qwen2.5:7b"): os.makedirs(output_dir, exist_ok=True) client = instructor.from_openai( OpenAI(base_url="http://localhost:11434/v1",api_key="ollama",),mode=instructor.Mode.JSON,) for fname in os.listdir(input_dir): parsed_text = parse_markdown_file(os.path.join(input_dir, fname)) refined = ollama_structured(client, parsed_text, model=model) question_str = f"题目: {refined.question}" options_str = "\n".join([f"{k}. {v}" for k, v in refined.options.items()]) explanation_str = f"解析: {refined.explanation}".replace("\n", "") refined_md = f"{question_str}\n 选项:\n{options_str}\n{explanation_str}" with open(os.path.join(output_dir, fname), "w", encoding="utf-8") as f: f.write(refined_md) print(f"Done: {fname}")
反复调整提示词后, 我们就可以得到较为完美的解析输出:
题目: 轻型无人机是指? 选项: A. 质量大于 7 千克,但小于等于 116 千克的无人机,且全马力平飞中,校正空速大于 100 千米/小时(55 海里/小时),升限大于 3000 米 B. 质量大于等于 7 千克,但小于 116 千克的无人机,且全马力平飞中,校正空速小于 100 千米/小时( 55 海里/小时),升限小于 3000 米 C. 空机质量大于 7 千克,但小于等于 116 千克的无人机,且全马力平飞中,校正空速小于 100 千米/小时 (55 海里/ 小时),升限小于 3000 米 解析: 该题关键点在于空机质量。参考 R1 的质量分类,微型$0<m≤7$ ext{kg}$,轻型$7<m≤116 ext{kg}$,小型$116<m≤5700 ext{kg}$,$m>大型 5700 ext{kg}。
其实还可以提供一些样例, 供模型进行少样本学习(Few-Shot Learning), 效果会更好一些. 但是钱不够, 那这方面的测试可以等后面有兴趣了再进行.
至于公式和 Docx 输出, 使用pypandoc和python-docx就可以很简单地解决, 这里就不贴代码了.
大模型通常是解决问题时懒人的大杀器, 但是如何正确使用依然是费力且玄学的事情. 在某些情况下, 提供的样本越多模型的性能反而会下降, 至于其故事就等后续另开新篇章再讲.
如果各位有更好的解决方法也可以提出来相互交流.
]]> 



 早上看新闻的时候,看见有跑马灯,瞬间心动了,感觉很炫酷(老婆觉得很 low) ]]>
早上看新闻的时候,看见有跑马灯,瞬间心动了,感觉很炫酷(老婆觉得很 low) ]]>