我的博客 前言
本文比较啰嗦,更倾向于是自言自语。不过我写完回顾,这更像是这段时间,自由思考的总结 :P
不过我不是游戏领域的人,这部分都是业余摸鱼思考的记录,如果有勘误,请与我联系,非常乐意交流。
文章可能需要 30 分钟。
主要涉及的主题:
- 游戏之难
- 游戏基本构成
- 游戏引擎
- 游戏与交互程序
- 框架和库思考
- 语言是否是游戏的瓶颈
- 双缓冲模式
- 线程和协程的讨论
- 线程队列&中断
使用 Ruby 实现 demo 。
rb2048
项目安装: gem install rb2048
进入游戏
帮助信息: rb2048 --help
Usage: rb2048 [options] --version verison --size SIZE Size of board: 4-10 --level LEVEL Hard Level 2-5
开始游戏 rb2048
-- Ruby 2048 -- ------------------------------------- | 16 | 16 | 2 | 16 | ------------------------------------- | 0 | 0 | 0 | 0 | ------------------------------------- | 0 | 0 | 0 | 2 | ------------------------------------- | 0 | 0 | 0 | 0 | ------------------------------------- Score: 16 You:UP Control: W(↑) A(←) S(↓) D(→) Q(quit) R(Restart)
升级难度 rb2048 --size=10 --level=5
-- Ruby 2048 -- ----------------------------------------------------------------------- | 8 | 16 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | ----------------------------------------------------------------------- | 0 | 16 | 0 | 16 | 0 | 8 | 0 | 0 | 0 | 0 | ----------------------------------------------------------------------- | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 16 | 8 | ----------------------------------------------------------------------- | 0 | 16 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 2 | ----------------------------------------------------------------------- | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ----------------------------------------------------------------------- | 0 | 8 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ----------------------------------------------------------------------- | 8 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | ----------------------------------------------------------------------- | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ----------------------------------------------------------------------- | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | ----------------------------------------------------------------------- | 0 | 4 | 0 | 0 | 4 | 8 | 0 | 0 | 0 | 16 | ----------------------------------------------------------------------- Score: 0 Control: W(↑) A(←) S(↓) D(→) Q(quit) R(Restart)
背景
我觉得命令行的程序比较赛博朋克,一直想做个命令行的交互程序。 目前在游戏公司,虽然我不是游戏工程师,但是接触了一些游戏行业的优秀小伙伴,我也忍不住思考关于游戏的主题。
我想做的命令行交互式程序,其实和游戏的思想内核是一致的。一拍即合。
我以前做过一点点研究。记录了一些笔记。关于 Ruby 中如何实现交互式命令行程序。 本文也是建立在这个基础之上。
用最简单的方式实现了一个 [贪吃蛇]
rb2048 心路历程
rb2048 亮点
rb2048 有趣的地方在于,在设计的时候,没有简单实现了之。毕竟有太多 2048 了,不差这一个。
对于我不是完成一个任务。由于最近两天关注于线程的使用,于是我把线程方面的使用加入到 rb2048 。这算是一个实验性的例子。验证我的想法:
rb2048 将:
这三部分分别用单独的线程实现,用队列通信。麻雀虽小,五脏俱全。虽然粗糙,但是代表了游戏引擎典型的设计思路。 (虽然我了解的不多)
认知变化
简单说说我最近的思考吧:
1 )对于计算机不同领域认识发生了变化
以前会觉得:游戏是游戏,web 是 web ,语言是语言,元编程就是元编程……也许还有很多概念,但是渐渐现在觉得无非是一件事 —— 编程罢了。
随着看到思考的东西逐渐变多,很多计算机领域的问题,在我的角度觉得都一样。
2 )第一性原理 + 交流,向内习得
这次摸着石头过河,比较新奇的体验就是,从当初一个想法到原理的讨论到最后实现。主要是思考推理,还有和优秀的同事的聊天中习得 (这里感谢 @谷神)。
现实中有很多游戏引擎。他们也许内有乾坤,不过其实是否研究他们也不重要。
我也不在乎别人的实现,或者更好地实现,是否有实现过了可以参考。其实没什么可参考的。只要我们自己想明白了,别忘了我们上面说的,他们都是一件事 —— 编程罢了。 当我们面临新问题,我们也会加强我们的 “引擎”。从思想上,他们是平等的。:P
可能与以前向外求知,现在会额外的向内思考。比较神奇的体验是,一些东西听个大概,也能盲猜个七八分。
从游戏开始聊吧
游戏之难
其实 2048 没啥好聊,写 2048 的背后是对游戏的一些思考。
其实游戏是一个比较特别的存在。他是一种比较特殊的程序,特殊在哪儿呢?
1 )他是持续交互程序
不同于简单的脚本,跑完结束。或者传递一个初始参数,就像函数一样运行完结束。
他是一个持续交互的过程,随着时间累计游戏的方方面面都在变化。
2 )多面平衡
不同于你写一段 function 就结束了。游戏要在运行的生命周期里:
在至少这三个方面互相作用。
还可能有:
- 网络
- 调度
- 硬件 CPU 、GPU 加速渲染
- AI
- 资源生成
- 数据采集
- 各种优化技术
其他周边并不展开
3 )稳定的帧率
如果是 60HZ 的游戏,必须在 16.6ms 内完成动作进行刷新。
这也不是普通业务脚本、程序一直跑自己的线性逻辑就算了,根本不关心时间。
4 )密集对象计算
简单的游戏还好,传统的模式是面向对象建模,一切看起来还算自然。
但是也出现了万人同台的游戏,这里传统的编程模式已经满足不了游戏对象的遍历了,很快会达到性能瓶颈。
这几年,出现了 ECS 架构( Entity-Component-System )。
浅谈《守望先锋》中的 ECS 构架
小结:
其实还有各种发散。如何使用 CPU 、GPU 加速渲染,这就不再提了。
游戏是一个非常特殊的存在,它意味着密集型计算、密集型 IO 混合出现的场景。我理解是比 Web 复杂在另一个维度上。
游戏涉及到 编程架构、网络、图形学、美术设计、资源加载…… 诸多丰富的话题。
这些就不是我这个门外汉靠管窥蠡测能够说得清的。我今天可以只谈谈我对游戏的理解和认识,以及构建 2048 的思考。
游戏基本构成
其实一个基本游戏可以用如下代码描述:
loop do IOEvent UpdateGameData Render end
游戏处在一个主循环中,我们依次要处理用户输入事件,根据用户输入事件进行游戏模型的变化,最后再把数据渲染在屏幕上。
这是一个单线程,主循环的例子。
现实中每个部分都可以额外变得复杂。也可以用线程单独实现。一切看需求。
游戏与交互应用程序
你会发现游戏就是交互程序。
上面的三部分,你也可以和 MVC 强行扯在一起。
- M 就是 Model 游戏数据
- V 就是 View 负责渲染视图
- C 就是 Controler 可以对应事件控制
MVC 的典型程序,除了桌面软件,Web 也算是,App 也算。
看似是在说游戏,实际上他们是一回事。
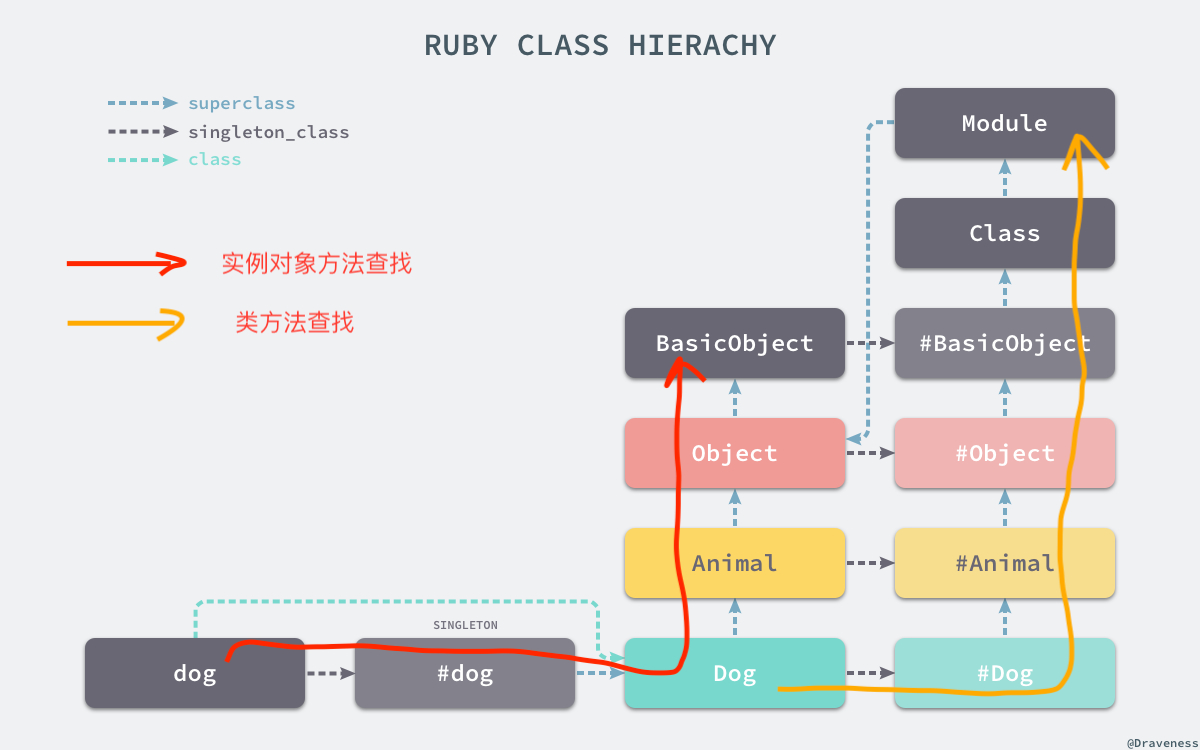
游戏引擎的秘密
游戏引擎其实就是框架,很佩服他们会起名字。
框架、引擎其实是一个东西,他们的特征就是一个半成品的软件。
loop do IOEvent UpdateGameData Render end
比如这个游戏循环,如果我们封装了主循环,封装了事件对象。对外暴露了一些生命周期。 这种半成品软件就是 所谓的框架,在游戏领域就是引擎。
作为下游,游戏引擎 /框架的使用者来说,我们写的程序就像填空一样和主循环工作在一起。
主循环决定了什么是框架、什么是库
所以我个人觉得,决定了什么是 框架 Framework 和 库 Library 的本质区别是 —— 主循环。
当你的程序是一种可被调用的状态,那么基本上你的程序可以看成一个 lib 当你的程序如果拥有了主循环的状态,基本宣告了不可被直接调用。那么它其实是一个 Framework 了。除了各种 Pattern 很少见到主循环的 lib 展示,不存在的原因是因为拥有主循环的程序,一般以具体的软件形态出来:
- 某种语言,比如 自带调度的 golang 、自带 EventLoop 的 Javascript 引擎 V8
- 某种框架,比如 Web 框架自带监听循环
- 某种引擎,比如 游戏引擎
Framework 式的程序,你的工作任务就会转向熟悉这个程序暴露的对象,期待你的程序和主循环能一起工作。
编程语言会是游戏的瓶颈么?
我们再来聊聊游戏引擎和编程语言。
Unity 的背后是 C# 支撑;虚幻引擎的背后是 C++。他们采用了更底层的语言。那么问题来了,编程语言会成为制约游戏的瓶颈么?
这也是我自己思考的一个问题。
我们可能会很粗暴地觉得 动态语言普遍慢,当然是越接近底层越好。其实我更想知道,如此这样选择的标准在哪儿?
其实我们可以思考下,这个结论不难获得。
动态语言真的慢么?
其实动态语言在执行一个命令的时候,Ruby 这种最后 C 实现; Golang 最后也落在 C ( Golang 实现自举之后,那就用汇编思考吧)。其实他们在执行一个具体操作的时候,数量级一致的。
他们其实差不多。
速度差距在哪儿呢?
1 )载入环境
C 、Golang 这种可以打包成二进制的语言。他编译阶段会把需要执行的代码编译成二进制。
所以执行的时候载入的是所需要用到的部分功能。
Python 、Ruby 这种其实 二进制是语言的解释器。运行的时候更多的时间花费在加载解释器。
不过,当你的程序复杂到涉及大量 IO 、基础库的时候,Golang 的打包结果会趋向于接近一个解释器的大小,比如 Ruby 差不多在 30M 左右。
我曾经比较过:
Golang 的一个项目命令行编辑器 micro 、Ruby 的一个项目命令行编辑器 diakonos
micro 运行内存 16M ,也就是他本地大小; diakonos 运行内存 30M ,也就是 Ruby 解释器差不多的大小。ruby 代码会执行才加载,所以可以忽略不计。
最大的差距,在于 30-16 的载入速度差,这个量级是不同的。
2 )语言构件
C 语言就像是一个高级一点的汇编。C 的角度一切都需要手动管理。那么其实对于底层语言,更现实一点的是会自己手动实现数据结构。
Ruby 这种动态语言,内部默认会有一个数据结构。
举个例子:
比如 a = "GAME"
C 语言实际上只会手动创建 "GAME" 四个字符
Python 底层可能创建一个 20 字符长度的数组。存 GAME 。也有好处,可以不定长支持动态扩容。
在生成语言构建的时候存在速度差。 动态语言等于多创建了很多语言在内存里的解构。
3 )解析时间
二进制的文件,直接载入内存执行。
动态语言有一个解析的过程。当然,也有优化空间,我们可以提前编译动态语言为虚拟机字节码。这样就获得了 对于解释器是二进制类似的东西。
4 ) GC 时间
和 C 语言相比,Python 、Ruby 自带 GC 。
他们存在一个 必须 GC 暂停的那么一个问题。C 语言的策略是手动回收。
双缓冲模式
我们好像列举了一大堆 动态语言的缺点似的。实际上自动管理的数据结构、自带 GC 、可以动态的编译执行…… 这些都是动态语言的缺点。
虽然付出了些许时间的代价。只要我们不滥用语言构件 和 特别烂的算法,真是巧妙的接近底层高效的实现。
其实我想说,动态语言至少在目标上不是特别大的瓶颈。
Java 也有游戏的例子; C# 也是自带 GC 。GC 不会是瓶颈。
语言的速度不会绝对意义上成为一个游戏组成的阻碍。
EVE 这样的大型游戏,内部使用了 巨慢的 Python 就可以说明问题。
之所以语言不一定构成拖慢游戏的原因,还有一个就是游戏和屏幕的刷新机制 —— 双缓冲模式。
其实可以理解为一个 内存空间,我们称之为 Buffer 。我们有两个 Buffer ,分别叫 A Buffer 、B Buffer 。
显示器先从 A Buffer 中读取数据渲染屏幕。我们程序写入 B Buffer ,等我们真的写完了,可慢或者快,但是无所谓,反正屏幕这时候在稳定的读取 A Buffer 内容。我们计算完毕,B Buffer 中写入了我们想要的东西,这时候只要把显示器读取的指针指向 B Buffer ,下次屏幕就会获得我们想要的画面。这就是双缓冲模式。由于存在双缓冲解构,算快和快慢,至少不会成为画面撕裂的原因。
rb2048 使用了 Curses 库来绘制界面,而 Curses 内部使用了双缓冲模式。
线程和协程的讨论
我们自己研究了两天线程和队列。主要是 Ruby 的实现。
这里不教线程和协程,只记录我觉得好玩的交流结果。
Ruby 线程的问题
缺点:
Ruby 存在线程锁,这导致每一时刻只能运行一个线程。线程就像背后虽然有很多工人,但是只能交替的一人一锤子。
这背后的原因在于 Ruby 考虑安全更多一点 —— 线程安全。
这样的多线程无法利用 CPU 多核心并行的特点。希望利用多核的,可以去用 JRuby ,因为 Java 底层没有加锁。
Ruby3 中也有了无锁线程的替代品 Ractor 也可以了解下。
CRuby 如果想利用多核心可以使用进程替代线程。如果设计得当,其实差不多。Ruby 里面 Webserver 有名气的 Puma 采用的就是多进程实现。
优点:
加上锁最大好处是线程安全,你可以自由的编码,Ruby 帮你加锁。这样多线程访问变量的时候,不会出错。
但是你退出来想,反正你自己也要加锁啊,谁加不是加。Ruby 默认的线程其实书写起来非常友好。
进程、线程、协程 傻傻分不清楚
我觉得再这样介绍这三个概念,这文章太冗长了。
直接说结论吧,直观上,这三者存在量级差,不仅体现在空间资源,时间资源都差不多。
进程 >> 线程 >> 协程
比如一台机器 4G 内存:
可能只能实际生成几百个进程就不太行了。 同样,可以生成几千个线程,就动不了了。 协程可以生成几十万个。
他们大概就是这个差距(有更好数据支持的,请联系我)。
他们切换上下文的时间也遵循这个比较关系。
所以我们一般的策略,尽量多用协程&线程,少用进程。
如果任务独立运行还好,就怕彼此还要通信,出现互相等待的局面。
线程具有 CPU 亲和性(一般语言来讲)。
比如 Golang 的 M:N 模型,主张 先生成 M 个线程,M 是机器 CPU 核心数,然后再在 M 个线程之间调度实际产生的 N 个任务。
比如 Nginx 的配置也主张 配置线程核心数和 CPU 核心数一致。
什么时候用线程、什么时候用协程?
线程、协程产生的原因是什么?
其实还是为了调度。
线程是细分进程下共享内存的场景;协程是为了细化调度。
因为进程、线程本质上是操作系统在调度。操作系统并不清楚什么时候应该调度。只能采用各种优先计算法、平均算法。再怎么算,也是盲人摸象罢了。
协程给了程序员一个口子,你可以用 协程在 涉及阻塞部分进行让出控制权。
简而言之,经验之谈:
涉及到 计算密集型 请用线程。
如果涉及到 IO 阻塞密集,请用协程。
我们的目的不是为了用而用,而是使用调度,提高我们代码执行的效率,减少等待。
硬件中断
如果说其实没有 if-else\switch\while ,计算机器其实只有 goto 。
如果你看过汇编,大概理解我是什么意思。
同样,计算机里进程、线程、协程背后调度的秘密,都来自于 CPU 的硬件中断功能。
只不过是上下文快速切换,切换上下文多和少罢了。
2048 的实现
其实 2048 的关键就是相邻元素合并,实现这么一个算法,反复执行到无元素可以继续合并。再把这个应用到 x\y 方向所有行列就好了。
具体线程
目前实现成通过队列来实现通信:
IO 线程,用户产生一个输入,进入事件队列。 游戏读取事件队列,开始计算游戏数据,把结果塞入渲染队列。 渲染线程,读取渲染队列数据进行渲染。
后续讨论
我和同事交流了一下,就 2048 而言其实可以很多方式做:
- 如果是队列依赖式
我们等于做出一个 pipline 的方式了
- 我们也可以解开队列阻塞
真正的自由渲染。虽然 2048 看不出效果
队列追赶问题
用户不断地敲击,产生时间,如果队列里一致产生数据,那不是渲染永远追不上?
多线程队列需要思考 生产者、消费者模型,需要设计匹配的方式。
解决方法
1 )控制生产频率,生产和消耗相抵消
事件采样、渲染 可以保持一个频率
2 )不控制生产,但是跳过生产
事件采样,可以携带时间戳。
如果渲染的时候,每次时间超时,跳过关键帧。
当然这些都是很细化的问题了。
总结
我倾向于研究一个东西,思考他的全部,寻找最佳的路径。 这些都是摸鱼结果,简单分享下。更深的感受还需要实践和交流。
后续
上文提到游戏里面最新流行 ECS 架构。ECS 抛弃了面向对象的思想,把同类数据摆放在一起,亲和 CPU 运行机制,方便大规模属性遍历。
ECS 应该如何用 Ruby 实现呢?
我的博客
]]>