已经配置了 wiredTigercachesizeGB 的参数
启动参数如下:
mongod --bind_ip-a11 --auth --journal --oplogsize 8192 --wiredTigercachesizeGB 28 --1ogpath logs/mongod.log --1ogappend --dbpath data --directoryperdb
操作系统的日志为:
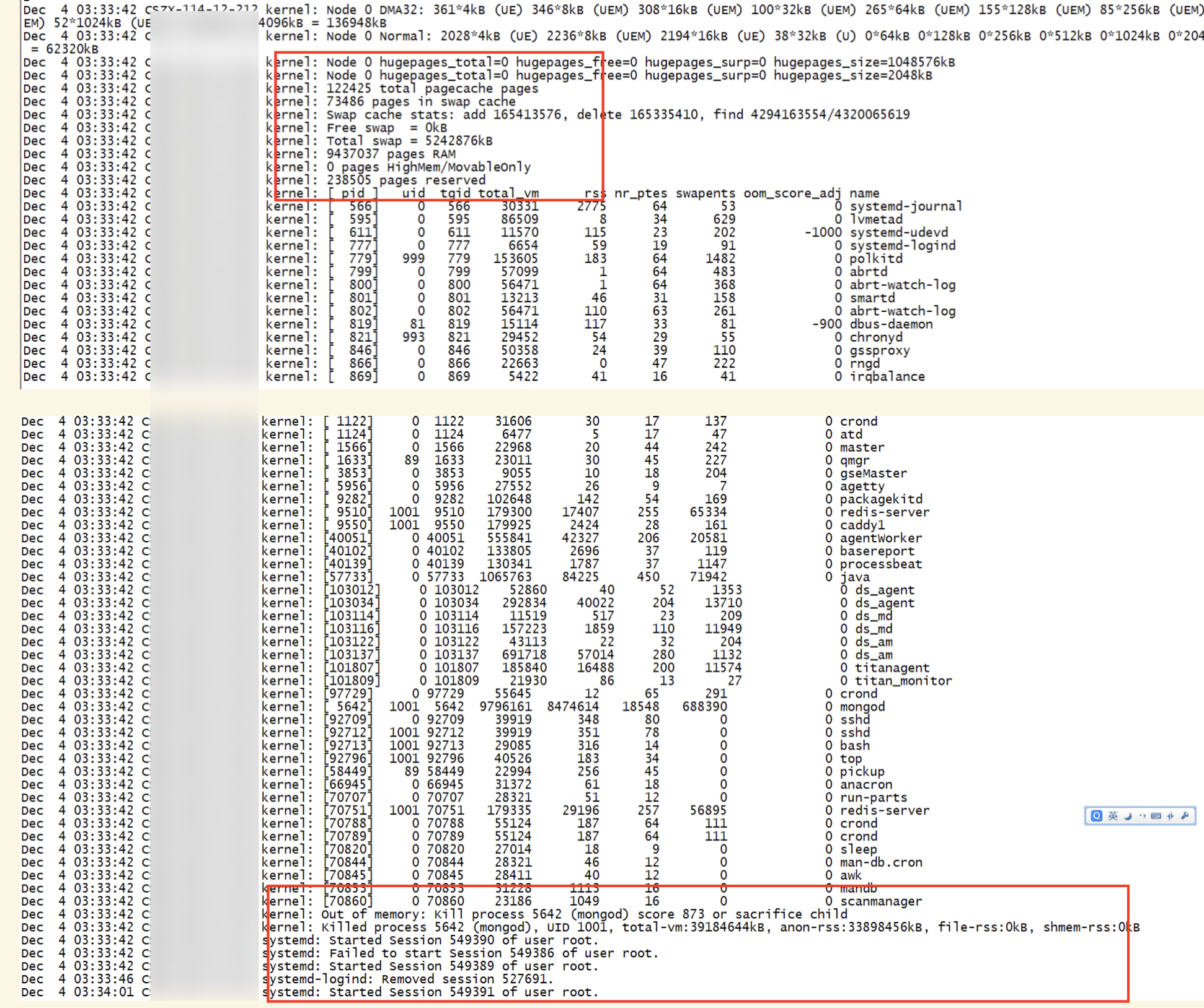

updateOne: { filter: {id: id}, update: {$set: item}, upsert: false } 在某时刻跑太多任务时,mongodb 偶发性会挂掉,出现以下错误:
MongoBulkWriteError: connection 20 to 127.0.0.1:27017 closed 这时我只能临时执行一下systemctl restart mongod命令重启一下就好了,请问大佬们,这是不是写入的数据太多了超过限制呢?是什么原因呢?该如何优化?谢谢!
mongodb/ mongodb/WiredTiger.lock mongodb/index-3--2162478702715552952.wt mongodb/diagnostic.data/ mongodb/diagnostic.data/metrics.2019-11-12T20-37-31Z-00000 mongodb/diagnostic.data/metrics.2019-12-03T12-08-23Z-00000 mongodb/diagnostic.data/metrics.2019-11-26T13-42-24Z-00000 mongodb/diagnostic.data/metrics.2019-12-05T17-38-23Z-00000 mongodb/diagnostic.data/metrics.2019-11-15T02-22-31Z-00000 mongodb/diagnostic.data/metrics.2019-12-01T03-58-23Z-00000 mongodb/diagnostic.data/metrics.2019-11-04T12-04-09Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-32-45Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-22-27Z-00000 mongodb/diagnostic.data/metrics.2019-11-20T17-17-16Z-00000 mongodb/diagnostic.data/metrics.2019-11-08T14-42-31Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-27-58Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-33-52Z-00000 mongodb/diagnostic.data/metrics.2019-11-10T20-37-31Z-00000 mongodb/diagnostic.data/metrics.2019-11-23T05-48-39Z-00000 mongodb/diagnostic.data/metrics.2019-11-22T23-37-16Z-00000 mongodb/diagnostic.data/metrics.2019-11-04T10-51-02Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-37-15Z-00000 mongodb/diagnostic.data/metrics.2019-11-06T09-32-31Z-00000 mongodb/diagnostic.data/metrics.2019-12-10T06-10-22Z-00000 mongodb/diagnostic.data/metrics.2019-11-18T12-06-17Z-00000 mongodb/diagnostic.data/metrics.2019-12-07T23-00-22Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-24-19Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-26-23Z-00000 mongodb/diagnostic.data/metrics.2019-11-28T20-58-23Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T10-08-45Z-00000 mongodb/diagnostic.data/metrics.2019-11-03T09-39-15Z-00000 mongodb/_mdb_catalog.wt mongodb/collection-0--2162478702715552952.wt mongodb/collection-4--6287796740362363623.wt mongodb/index-5--2162478702715552952.wt mongodb/journal/ mongodb/journal/WiredTigerPreplog.0000000001 mongodb/journal/WiredTigerPreplog.0000000002 mongodb/journal/WiredTigerLog.0000000434 mongodb/WiredTiger.wt mongodb/collection-2--4216008088303394775.wt mongodb/WiredTigerLAS.wt mongodb/WiredTiger.turtle mongodb/index-6--6287796740362363623.wt mongodb/index-4--2162478702715552952.wt mongodb/collection-2--6287796740362363623.wt mongodb/index-3--6287796740362363623.wt mongodb/index-1--2162478702715552952.wt mongodb/index-1--4216008088303394775.wt mongodb/collection-0--4216008088303394775.wt mongodb/mongod.lock mongodb/WiredTiger mongodb/collection-0--6287796740362363623.wt mongodb/index-4--4216008088303394775.wt mongodb/storage.bson mongodb/sizeStorer.wt mongodb/index-2--2162478702715552952.wt mongodb/index-3--4216008088303394775.wt mongodb/index-1--6287796740362363623.wt mongodb/index-5--6287796740362363623.wt 有没有熟悉 mogodb 的大佬看一眼,这究竟是啥备份数据呀,怎么恢复呀,我用 MongoDB 自带的导入命令尝试,始终说格式不对。我从最新的 7.0.4 版本,一路试到 3.0 版本,全部说格式不对。难不成这个是什么第三方工具导出的数据?
]]>就光一个 ObjectId ,我始终搞不清 mongoose.Types.ObjectId mongoose.Schema.Types.ObjectId有什么区别。
然后文档里面还有一个 mongoose.ObjectId,这玩意 ide 直接提示类型错误了,好蛋疼。
生产环境,需要添加一个索引,有没有不影响线上业务的方案,或者有什么方案和经验可以分享下,把影响降到最低。
]]>不过有些业务代码有在多线程下访问 MySQL 的场景时,更新数据会用 select ... for update 锁行,比如常见的锁个订单,然后调用外部接口后修改状态,失败的时候回滚数据,此时其他的线程访问都是阻塞住的。
用 MongoDB 的话,是否原生指令就可以实现同样的效果(好像没搜到)?是必须得额外搞个分布式锁来?
]]>{ "_id": { "$oid": "63ed9bd52b031a24fdbe1e1e" } "creatorId": { "$oid": "63e51a155ca7f018d6038967" }, "text": "评论内容 0216" } 子评论文档:
{ "_id": { "$oid": "63ee03eb98b24f5603c044da" }, "linkCommentId": { "$oid": "63ed9bd52b031a24fdbe1e1e" }, "replyToUserId": { "$oid": "63e51a155ca7f018d6038967" }, "creatorId": { "$oid": "63e51a155ca7f018d6038967" }, "text": "测试子评论 0216-2" } 代码
[ { $match: { _id: ObjectId("63ed9bd52b031a24fdbe1e1e"), }, }, { // 从子评论集合中找到评论的子评论(假设该评论不存在子评论,replies 为空数组) $lookup: { from: "dynamicChildComment", localField: "_id", foreignField: "linkCommentId", as: "replies", }, }, { // 展开子评论(得到一条没有 replies 的文档) $unwind: { path: "$replies", preserveNullAndEmptyArrays: true, }, }, { // 1 、给子评论寻找发布者,执行后:replies 对象只存在一个属性 creator ,值为空数组 $lookup: { from: "users", localField: "replies.creatorId", foreignField: "_id", as: "replies.creator", }, }, { // 2 、执行后:replies 对象没有属性 $unwind: { path: "$replies.creator", preserveNullAndEmptyArrays: true, }, }, { // 3 、执行后:replies 对象只存在一个属性 replyToUser ,值为空数组 $lookup: { from: "users", localField: "replies.replyToUserId", foreignField: "_id", as: "replies.replyToUser", }, }, { // 4 、执行后:replies 对象没有属性 $unwind: { path: "$replies.replyToUser", preserveNullAndEmptyArrays: true, }, }, { $group: { _id: "_id", replies: { $push: "$replies", // 到这里,就出现了一个 replies 数组,有一个空对象作为第 0 个元素 }, }, }, ] 我该如何将 replies 数组变成空数组
]]>现在有两个 document, order 和 product. 数据分别如下
// order { "id": 1, "name": "我的订单", "products": [ { "productId": 1, "num": 2 }, { "productId": 2, "num": 1 } ] } // product { "id": 1, "name": "测试商品", "price": 10.0 } { "id": 2, "name": "正式商品", "price": 18.8 } 如果我想得到下面这样的数据结构, 应该怎么写查询呢
{ "_id": 1, "name": "我的订单", "products": [ { "productId": 1, "num": 2, "product": { "id": 1, "name": "测试商品", "price": 10.0 } }, { "productId": 2, "num": 1, "product": { "id": 2, "name": "正式商品", "price": 18.8 } } ] } 已经配置了 wiredTigercachesizeGB 的参数
启动参数如下:
mongod --bind_ip-a11 --auth --journal --oplogsize 8192 --wiredTigercachesizeGB 28 --1ogpath logs/mongod.log --1ogappend --dbpath data --directoryperdb
操作系统的日志为:
const orderSchema = new mongoose.Schema({ user: { type: mongoose.SchemaTypes.ObjectId, ref: "User", required: true }, orderNum: { type: String, required: true }, }) const UserSchema = new mongoose.Schema({ nickname: String, avatarUrl: String, phone: String, appId: { type: String, } }); 求教: 为什么字符串解析的问题, 会影响其他两个字段的赋值呢? 我在本地也没复现出这个情况
]]>结果隔三差五就会丢失一部分 collection ,代码里没查出问题,加上每天都会重抓补齐数据,就一直没管
前两天想着还是解决一下,用 Celery 做了一个每分钟执行的任务,检查 collections 里缺少某一张表就发消息报警
结果三天过去了,数据都没再丢了
MongoDB 是第一个使用概率云形式存储数据的数据库吗,一直被观察就会坍缩,不观察就会逸散的
(其实是想问问丢数据的原因,和排查的方法)
]]>Migration Results for the last 24 hours: 36 : Success 1 : Failed with error 'aborted', from shard1 to shard3 1 : Failed with error 'aborted', from shard1 to shard2 2022-05-30T10:46:18.407+0800 I SHARDING [conn1034] about to log metadata event into changelog: { _id: "rabbit-node1-2022-05-30T10:46:18.407+0800-62942ffa44ce915f01bbaa4d", server: "rabbit-node1", clientAddr: "ip:33616", time: new Date(1653878778407), what: "moveChunk.error", ns: "data.m", details: { min: { a: 27, originTime: 1646064091546 }, max: { a: 144, originTime: 1646092716120 }, from: "shard1", to: "shard2" } } 2022-05-30T10:47:26.036+0800 I SHARDING [conn1034] about to log metadata event into changelog: { _id: "rabbit-node1-2022-05-30T10:47:26.036+0800-6294303e44ce915f01bc43b2", server: "rabbit-node1", clientAddr: "ip:33616", time: new Date(1653878846036), what: "moveChunk.error", ns: "data.m", details: { min: { a: 144, originTime: 1646092716120 }, max: { a: 265, originTime: 1646098360020 }, from: "shard1", to: "shard3" } } 1.比如修改 maxTransactiOnLockRequestTimeoutMillis=36000000 2.应用层限制,比如实现排队系统 请问大佬有什么好的建议吗,感谢感谢
]]>比如布隆过滤器,一般是怎么导入亿级数据的?
]]>[{ "date": "20220101", "id": "aaa", "name": "jack" }, { "date": "20220101", "id": "aaa", "name": "tony" }, { "date": "20220102", "id": "aaa", "name": "jack1" }, { "date": "20220102", "id": "aaa", "name": "jack2" }, { "date": "20220102", "id": "bbb", "name": "jack3" }, { "date": "20220103", "id": "aaa", "name": "jack" }] 需要按日期分组,再统计出每天的数据总数,各字段分组后的数量,期望得到这样的结果
date count id_count name_count 20220103 1 1 1 20220102 3 2 3 20220101 2 1 2 研究了下聚合查询,$group按照date分组后就没法统计其他字段的分组数量了。 还有个$push可以在分组时将其他字段压入到新数组,但是其中数据是重复的,而我只是想得到分组后的数量而已。
目前是傻乎乎的查多次。可以一次查出来我期望的结果吗?
]]>对这个数据,怎么实现类似 find({"groups.*.status": "closed"}) 这样的查询?
]]>
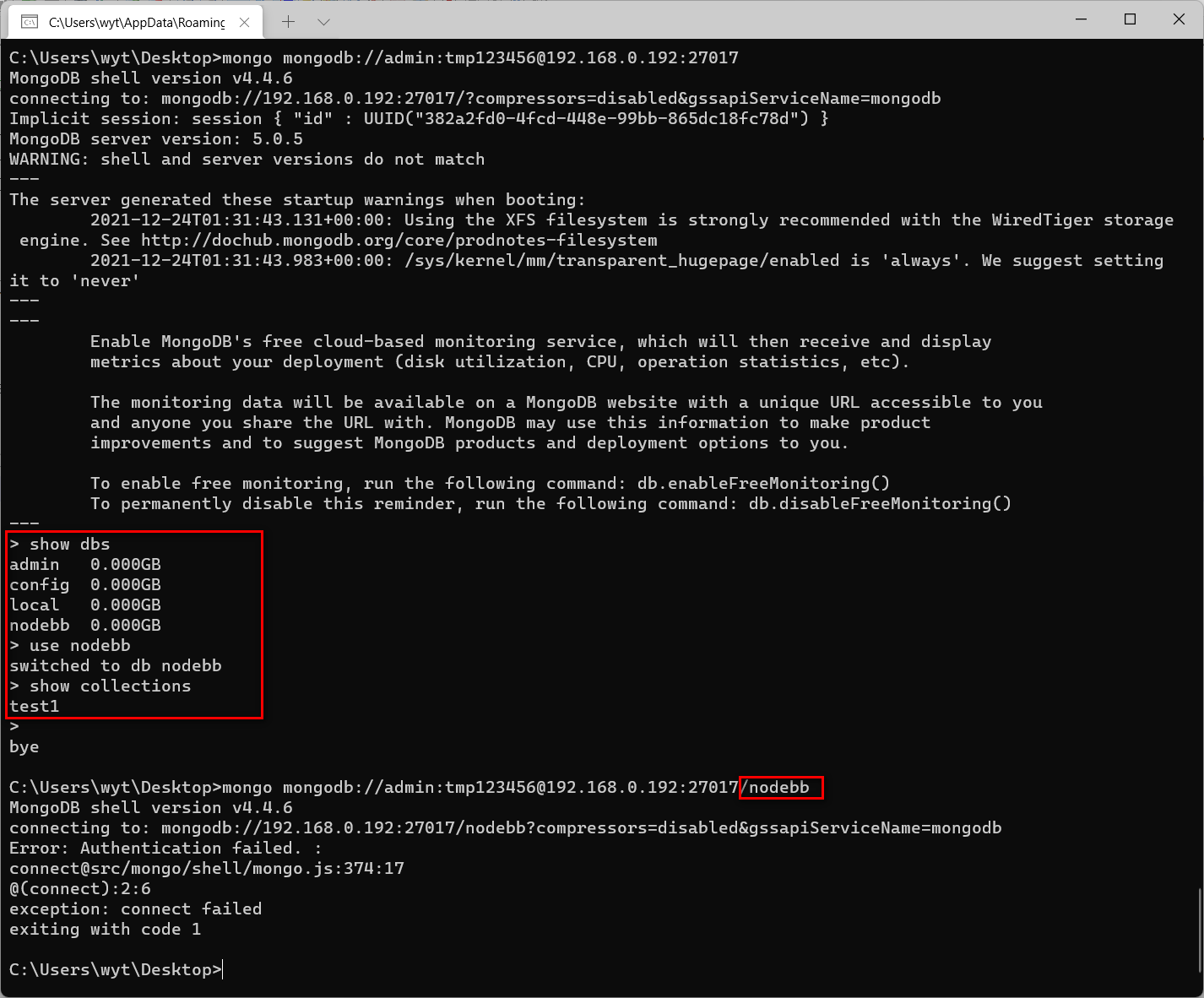
navicat 连接正常,mongo 命令行不带数据库名正常,但是后面加数据库名就失败了?
这是什么错误呢。谢谢
]]>构建缓存的时候,将 MongoDB 数据通过 JSON.srtingify 存储到 redis 中,这时候 ObjectId 类型的字段都会变为字符串。
取缓存的时候,如果我要获取 ObjectId 类型的字段,就必须手动做类型转换。
有其他办法可以根据 Schema 自动做类型转换嘛?或者 JSON.stringify 不转换 ObjectId 类型。
]]> await Promise.all( tuples.map(async ([list, count]) => { // await this.listModel.findOne({ _id: list }); // 存在这行也正常,不存在的话就不正常。 await this.listModel.updateOne( { _id: list }, { $inc: { sampleCount: -count, }, }, { session }, ); }), ); for (const [list, count] of tuples) { await this.listModel.updateOne( { _id: list }, { $inc: { sampleCount: -count, }, }, { session }, ); } 我排查了下,updateOne 方法都能返回修改成功一行数据,所以更新是成功的,但是最后事务执行完毕后只查到部分数据有正常更新。
MongoDB 4.4 。
]]># 目录表 class TC_struct(Document): name = StringField() #目录名 parent = ObjectIdField() #上层目录的 id # 文件表 class TC_item(Document): # 所在目录 parent = ReferenceField(TC_struct) #所在的目录 根据目录,递归查找目录中的所有文件。
#先找到所有的目录。path_id 为所选择目录的 id path_ls = recurs_path(TC_struct, path_id)
#然后找到目录下的所有文件 qry_list = Q(parent__in=path_ls)
#递归查找目录的方法。
def recurs_path(tb_cls, path_id): rds = tb_cls.objects(parent=ObjectId(path_id)).only('id') rt = list() rt.append(ObjectId(path_id)) for rd in rds: # 递归查找子目录中的子目录 rt.extend(recurs_path(tb_cls, rd._id)) return rt 现在的问题是,如果目录结构很深,如有 4000 多个目录,在递归的时候,耗时特别长。
有没有方法,可以提升递归时的效率。 根本的需求是:递归查找目录中的所有文件。
]]>问题: 那在 Golang 使用 MongoDB 过程中,如果 MongoDB 查询不传拼接后的 Javascript ,只有单纯的 string ,是否可以防止相关注入呢?
]]>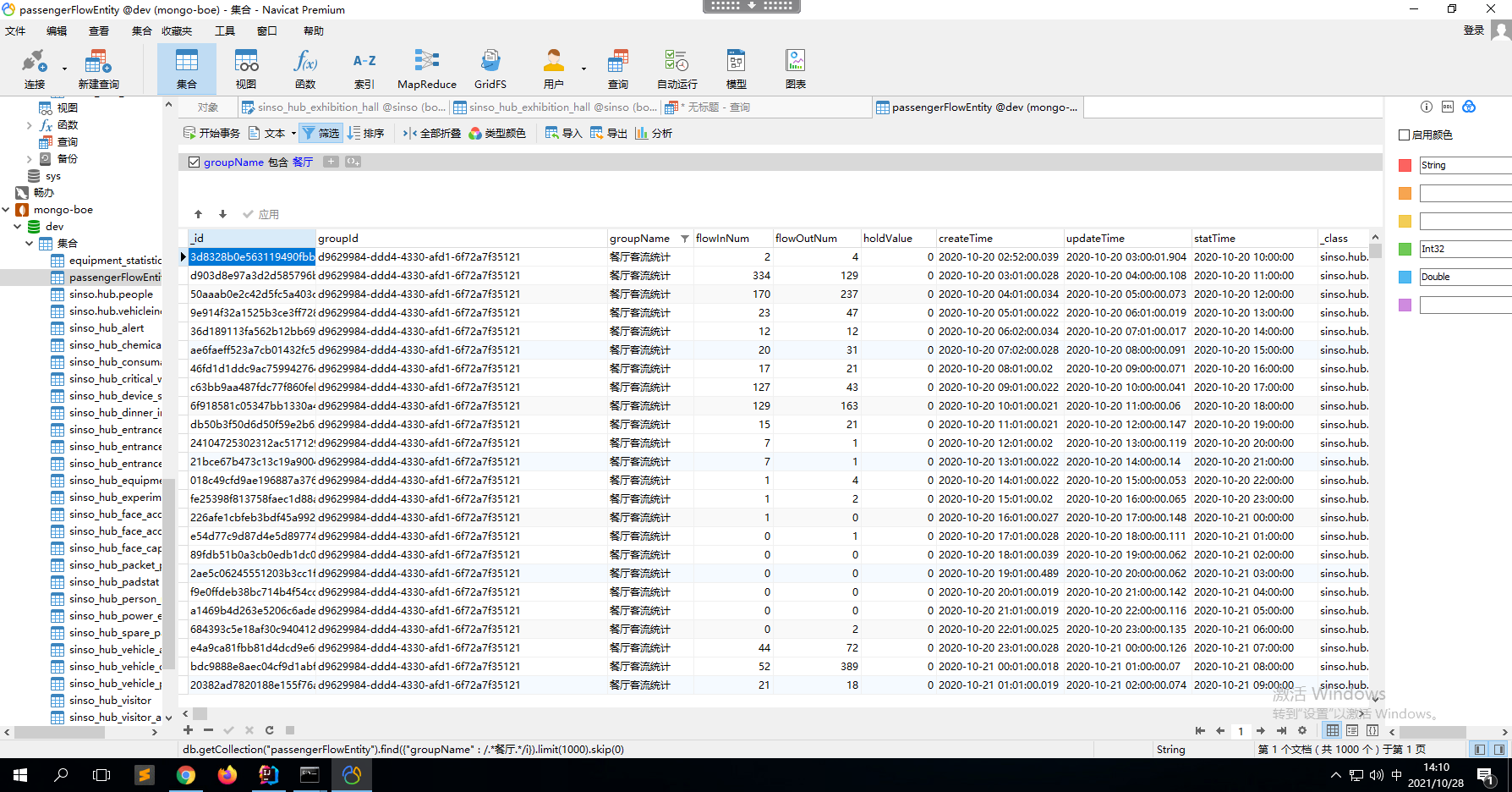
我想按照这个 startTime ,每天分组求和, 把 6 点到 9 点的 flowInNum 字段数据求和然后给个新字段 monring 默认是早上 把 11 点到 13 点的 flowInNum 字段数据求和然后给个新字段 afternoon 默认是中午 把 18 点到 20 点的 flowInNum 字段数据求和然后给个新字段 night 默认是晚上
]]> 我想按照这个 startTime ,每天分组求和, 把 6 点到 9 点的 flowInNum 字段数据求和然后给个新字段 monring 都默认是早上 把 11 点到 13 点的 flowInNum 字段数据求和然后给个新字段 afternoon 都默认是中午 把 18 点到 20 点的 flowInNum 字段数据求和然后给个新字段 night 都默认是晚上
]]>最近没动过配置,不敢贸然重启服务,求教下各位
]]>