有一个清单或者书籍能够囊括这些数学内容吗。 ]]>
从豆包做输入法来看,未来估计要会聚焦输入法。 因为输入法比浏览器还能捕捉用户数据。对于不上网的数据、行为也能采集。
再后来,估计是要竞争操作系统了。 自然,因为有生态原因,不大会出现除 linux 、windows 之后的大系统。 但是我估计使用开源 linux 魔改的系统是很多的--AI 公司搞点这个,技术上简直易如反掌。
不知道大家怎么看?
]]>(dddd-trainer) PS C:\Users\12460\Documents\project\dddd_trainer> uv run .\test.py 2025-11-13 00:35:09.0336981 [E:onnxruntime:, sequential_executor.cc:572 onnxruntime::ExecuteKernel] Non-zero status code returned while running SequenceAt node. Name:'n0_424' Status Message: Invalid sequence index (57) specified for sequence of size (57) Traceback (most recent call last): File "C:\Users\12460\Documents\project\dddd_trainer\test.py", line 14, in <module> res = ocr.classification(image) ^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\ddddocr\__init__.py", line 2643, in classification ort_outs = self.__ort_session.run(None, ort_inputs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\onnxruntime\capi\onnxruntime_inference_collection.py", line 287, in run return self._sess.run(output_names, input_feed, run_options) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Non-zero status code returned while running SequenceAt node. Name:'n0_424' Status Message: Invalid sequence index (57) specified for sequence of size (57) 测试的训练集数据: https://wwm.lanzoum.com/itczd0b5z3yj
GitHub: https://github.com/sml2h3/dddd_trainer.git
# test.py import ddddocr ocr = ddddocr.DdddOcr( det=False, ocr=False, show_ad=False, import_onnx_path=r"C:\Users\12460\Documents\project\dddd_trainer\projects\test_2\models\test_2_1.0_23_6000_2025-11-13-00-06-13.onnx", charsets_path=r"C:\Users\12460\Documents\project\dddd_trainer\projects\test_2\models\charsets.json", ) with open(r"C:\Users\12460\Downloads\1112\new\PKKQ_1578462523867.jpg", "rb") as f: image = f.read() res = ocr.classification(image) print(res) 操作日志
(dddd-trainer) PS C:\Users\12460\Documents\project\dddd_trainer> uv run .\app.py create test_3 2025-11-13 00:29:53.496 | INFO | __main__:__init__:12 - Hello baby~ 2025-11-13 00:29:53.497 | INFO | __main__:create:15 - Create Project ----> test_3 2025-11-13 00:29:53.497 | INFO | utils.project_manager:create_project:13 - Creating Directory... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3 2025-11-13 00:29:53.497 | INFO | utils.project_manager:create_project:20 - Creating Directory... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3\models 2025-11-13 00:29:53.498 | INFO | utils.project_manager:create_project:24 - Creating Directory... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3\cache 2025-11-13 00:29:53.498 | INFO | utils.project_manager:create_project:28 - Creating Directory... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3\checkpoints 2025-11-13 00:29:53.498 | INFO | utils.project_manager:create_project:32 - Creating CRNN Config File... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3\config.yaml 2025-11-13 00:29:53.500 | INFO | utils.project_manager:create_project:36 - Create Project Success! ----> test_3 (dddd-trainer) PS C:\Users\12460\Documents\project\dddd_trainer> uv run .\app.py cache test_3 C:\Users\12460\Downloads\1112\images 2025-11-13 00:30:10.911 | INFO | __main__:__init__:12 - Hello baby~ 2025-11-13 00:30:10.913 | INFO | __main__:cache:20 - Caching Data ----> test_3 Path ----> C:\Users\12460\Downloads\1112\images 2025-11-13 00:30:10.919 | INFO | utils.cache_data:__get_label_from_name:36 - Files number is 8599. 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8599/8599 [00:00<00:00, 1379439.31it/s] 2025-11-13 00:30:10.926 | INFO | utils.cache_data:__collect_data:92 - Coolect labels is [" ", "1", "D", "Q", "F", "R", "P", "5", "9", "6", "X", "G", "H", "S", "V", "Z", "3", "T", "K", "J", "W", "2", "8", "4", "U", "Y", "E", "I", "C", "B", "L", "A", "7"] 2025-11-13 00:30:10.929 | INFO | utils.cache_data:__collect_data:96 - Writing Cache Data! 2025-11-13 00:30:10.929 | INFO | utils.cache_data:__collect_data:98 - Cache Data Number is 8599 2025-11-13 00:30:10.929 | INFO | utils.cache_data:__collect_data:99 - Writing Train and Val File. 2025-11-13 00:30:10.931 | INFO | utils.cache_data:__collect_data:116 - Train Data Number is 8342 2025-11-13 00:30:10.932 | INFO | utils.cache_data:__collect_data:117 - Val Data Number is 257 (dddd-trainer) PS C:\Users\12460\Documents\project\dddd_trainer> uv run .\app.py train test_3 2025-11-13 00:30:26.382 | INFO | __main__:__init__:12 - Hello baby~ 2025-11-13 00:30:26.383 | INFO | __main__:train:26 - Start Train ----> test_3 2025-11-13 00:30:26.384 | INFO | utils.train:__init__:40 - Taget: min_Accuracy: 0.97 min_Epoch: 20 max_Loss: 0.05 2025-11-13 00:30:26.384 | INFO | utils.train:__init__:45 - USE GPU ----> 0 2025-11-13 00:30:26.384 | INFO | utils.train:__init__:52 - Search for history checkpoints... 2025-11-13 00:30:26.384 | INFO | utils.train:__init__:69 - Empty history checkpoints 2025-11-13 00:30:26.384 | INFO | utils.train:__init__:71 - Building Net... C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\torch\nn\modules\rnn.py:123: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.3 and num_layers=1 warnings.warn( 2025-11-13 00:30:26.400 | INFO | utils.train:__init__:75 - Net( (cnn): DdddOcr( (cnn): Sequential( (conv0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu0): ReLU(inplace=True) (pooling0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu1): ReLU(inplace=True) (pooling1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (batchnorm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu2): ReLU(inplace=True) (conv3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu3): ReLU(inplace=True) (pooling2): MaxPool2d(kernel_size=(2, 2), stride=(2, 1), padding=(0, 1), dilation=1, ceil_mode=False) (conv4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (batchnorm4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu4): ReLU(inplace=True) (conv5): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (relu5): ReLU(inplace=True) (pooling3): MaxPool2d(kernel_size=(2, 2), stride=(2, 1), padding=(0, 1), dilation=1, ceil_mode=False) (conv6): Conv2d(128, 128, kernel_size=(2, 2), stride=(1, 1)) (batchnorm6): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu6): ReLU(inplace=True) ) ) (lstm): LSTM(384, 384, dropout=0.3, bidirectiOnal=True) (loss): CTCLoss() (fc): Linear(in_features=768, out_features=33, bias=True) ) 2025-11-13 00:30:26.400 | INFO | utils.train:__init__:76 - Building End 2025-11-13 00:30:26.509 | INFO | utils.train:__init__:81 - Get Data Loader... 2025-11-13 00:30:26.510 | INFO | utils.load_cache:__init__:102 - Charsets is [" ", "1", "D", "Q", "F", "R", "P", "5", "9", "6", "X", "G", "H", "S", "V", "Z", "3", "T", "K", "J", "W", "2", "8", "4", "U", "Y", "E", "I", "C", "B", "L", "A", "7"] 2025-11-13 00:30:26.510 | INFO | utils.load_cache:__init__:106 - Image Resize is [-1, 64] 2025-11-13 00:30:26.510 | INFO | utils.load_cache:__init__:118 - Image Path is C:\Users\12460\Downloads\1112\images 2025-11-13 00:30:26.511 | INFO | utils.load_cache:__init__:25 - Reading Cache File... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3\cache\cache.train.tmp 2025-11-13 00:30:26.512 | INFO | utils.load_cache:__init__:30 - Read Cache File End! Caches Num is 8342. 2025-11-13 00:30:26.512 | INFO | utils.load_cache:__init__:25 - Reading Cache File... ----> C:\Users\12460\Documents\project\dddd_trainer\projects\test_3\cache\cache.val.tmp 2025-11-13 00:30:26.513 | INFO | utils.load_cache:__init__:30 - Read Cache File End! Caches Num is 257. 2025-11-13 00:30:26.513 | INFO | utils.train:__init__:87 - Get Data Loader End! 2025-11-13 00:30:30.161 | INFO | utils.train:start:108 - [2025-11-13-00_30_30] Epoch: 0 Step: 100 LastLoss: 3.5620920658111572 AvgLoss: 4.684982450008392 Lr: 0.01 2025-11-13 00:30:33.520 | INFO | utils.train:start:108 - [2025-11-13-00_30_33] Epoch: 0 Step: 200 LastLoss: 3.629438877105713 AvgLoss: 3.591061780452728 Lr: 0.01 2025-11-13 00:30:36.940 | INFO | utils.train:start:108 - [2025-11-13-00_30_36] Epoch: 1 Step: 300 LastLoss: 3.478365659713745 AvgLoss: 3.574828338623047 Lr: 0.01 2025-11-13 00:30:40.677 | INFO | utils.train:start:108 - [2025-11-13-00_30_40] Epoch: 1 Step: 400 LastLoss: 3.725684881210327 AvgLoss: 3.5830772018432615 Lr: 0.01 2025-11-13 00:30:44.054 | INFO | utils.train:start:108 - [2025-11-13-00_30_44] Epoch: 1 Step: 500 LastLoss: 3.6253044605255127 AvgLoss: 3.5884796619415282 Lr: 0.01 ... 2025-11-13 00:33:39.470 | INFO | utils.train:start:108 - [2025-11-13-00_33_39] Epoch: 19 Step: 5200 LastLoss: 0.0010958763305097818 AvgLoss: 0.0016259117133449763 Lr: 0.009604 2025-11-13 00:33:44.079 | INFO | utils.train:start:108 - [2025-11-13-00_33_44] Epoch: 20 Step: 5300 LastLoss: 0.0009493848774582148 AvgLoss: 0.0010536348074674606 Lr: 0.009604 2025-11-13 00:33:48.775 | INFO | utils.train:start:108 - [2025-11-13-00_33_48] Epoch: 20 Step: 5400 LastLoss: 0.0010489150881767273 AvgLoss: 0.0012551895825890823 Lr: 0.009604 2025-11-13 00:33:53.303 | INFO | utils.train:start:108 - [2025-11-13-00_33_53] Epoch: 21 Step: 5500 LastLoss: 0.0011606556363403797 AvgLoss: 0.000944445063942112 Lr: 0.009604 2025-11-13 00:33:57.803 | INFO | utils.train:start:108 - [2025-11-13-00_33_57] Epoch: 21 Step: 5600 LastLoss: 0.0007763305329717696 AvgLoss: 0.0009715505503118038 Lr: 0.009604 2025-11-13 00:34:02.339 | INFO | utils.train:start:108 - [2025-11-13-00_34_02] Epoch: 21 Step: 5700 LastLoss: 0.0012899019056931138 AvgLoss: 0.0015180535794934258 Lr: 0.009604 2025-11-13 00:34:06.902 | INFO | utils.train:start:108 - [2025-11-13-00_34_06] Epoch: 22 Step: 5800 LastLoss: 0.0009287762804888189 AvgLoss: 0.0015425046352902428 Lr: 0.009604 2025-11-13 00:34:11.336 | INFO | utils.train:start:108 - [2025-11-13-00_34_11] Epoch: 22 Step: 5900 LastLoss: 0.0007486791582778096 AvgLoss: 0.0011510271998122334 Lr: 0.009604 2025-11-13 00:34:15.845 | INFO | utils.train:start:137 - [2025-11-13-00_34_15] Epoch: 23 Step: 6000 LastLoss: 0.0006851484067738056 AvgLoss: 0.0009158773045055568 Lr: 0.009604 Acc: 1.0 2025-11-13 00:34:15.846 | INFO | utils.train:start:143 - Training Finished!Exporting Model... C:\Users\12460\Documents\project\dddd_trainer\nets\__init__.py:216: UserWarning: # 'dynamic_axes' is not recommended when dynamo=True, and may lead to 'torch._dynamo.exc.UserError: Constraints violated.' Supply the 'dynamic_shapes' argument instead if export is unsuccessful. torch.onnx.export(net, dummy_input, graph_path, export_params=True, verbose=False, W1113 00:34:16.515000 3024 .venv\Lib\site-packages\torch\onnx\_internal\exporter\_compat.py:114] Setting ONNX exporter to use operator set version 18 because the requested opset_version 12 is a lower version than we have implementations for. Automatic version conversion will be performed, which may not be successful at converting to the requested version. If version conversion is unsuccessful, the opset version of the exported model will be kept at 18. Please consider setting opset_version >=18 to leverage latest ONNX features The model version conversion is not supported by the onnxscript version converter and fallback is enabled. The model will be converted using the onnx C API (target version: 12). Failed to convert the model to the target version 12 using the ONNX C API. The model was not modified Traceback (most recent call last): File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\onnxscript\version_converter\__init__.py", line 127, in call converted_proto = _c_api_utils.call_onnx_api( ^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\onnxscript\version_converter\_c_api_utils.py", line 65, in call_onnx_api result = func(proto) ^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\onnxscript\version_converter\__init__.py", line 122, in _partial_convert_version return onnx.version_converter.convert_version( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\onnx\version_converter.py", line 39, in convert_version converted_model_str = C.convert_version(model_str, target_version) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ RuntimeError: D:\a\onnx\onnx\onnx/version_converter/BaseConverter.h:68: adapter_lookup: Assertion `false` failed: No Adapter From Version $18 for Split Skipping constant folding for op Split with multiple outputs. Skipping constant folding for op Split with multiple outputs. Applied 3 of general pattern rewrite rules. Skipping constant folding for op Split with multiple outputs. Skipping constant folding for op Split with multiple outputs. 2025-11-13 00:34:45.655 | INFO | utils.train:start:159 - Export Finished!Using Time: 3.816666666666667min (dddd-trainer) PS C:\Users\12460\Documents\project\dddd_trainer> uv run .\test.py 2025-11-13 00:35:09.0336981 [E:onnxruntime:, sequential_executor.cc:572 onnxruntime::ExecuteKernel] Non-zero status code returned while running SequenceAt node. Name:'n0_424' Status Message: Invalid sequence index (57) specified for sequence of size (57) Traceback (most recent call last): File "C:\Users\12460\Documents\project\dddd_trainer\test.py", line 14, in <module> res = ocr.classification(image) ^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\ddddocr\__init__.py", line 2643, in classification ort_outs = self.__ort_session.run(None, ort_inputs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\12460\Documents\project\dddd_trainer\.venv\Lib\site-packages\onnxruntime\capi\onnxruntime_inference_collection.py", line 287, in run return self._sess.run(output_names, input_feed, run_options) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Non-zero status code returned while running SequenceAt node. Name:'n0_424' Status Message: Invalid sequence index (57) specified for sequence of size (57) https://datahonor.com/blog/2025/11/02/bert/
目录:
关于我们做到了哪一步 BERT 简介 有趣的观察 预训练过程的有趣现象 数据非常非常重要 从 Finetune 管窥预训练的威力 错误与教训 即使在极小数据集上也无法过拟合 一次性预处理全量数据,CPU 加班,GPU 休假 试图用临时手搓的玩意儿达到很好的性能 workers 和 prefetch 因子设得过大导致 OOM 没有优雅处理 DataLoader worker 的异常 评估时使用了错误的 tokenizer 最后 RTX3090 24G
A5000 24G
2000Ada 16G
RTX4000Ada 20G
RTX5070Ti 16Gb
RTX4000Ada 20G
5080 16G
5060Ti 16G
RTX5060Ti 16G
5070Ti 16G
RTX 5000 24G
]]>💡 我的需求大致是:
- 先克隆/微调一个中文声音,让声音自然、不机械。
- 风格希望像相声那种“说学逗唱”的语气——要能控制节奏、停顿、情绪。
- 后期做有声小说输出
🖥️ 当前设备配置:
- CPU:R5 5600G
- 内存:32GB DDR4
- 显卡:暂未购买,考虑 RTX 3060 ( 12GB ) 或 RTX 3060Ti ( 8GB )大概就是 2000 元价位的
- 系统:Windows / Ubuntu 都能装(开发环境可切换)
🔧 初步技术路线:
我目前查下来主要有两条思路:
-
快速上手路线(生成类)
- 使用 Suno Bark 或类似大模型,直接生成多情感中文语音;
- 适合先试效果、调节 prompt 实现“相声语气”;
- 缺点是声音不一定稳定、不可控。
-
高可控路线(训练类)
- 管线:Speaker Encoder → VITS / Coqui-TTS → HiFi-GAN ;
- 录制 20 ~ 60 分钟高质量音频做微调;
- 目标是克隆稳定音色、能生成自然语调的中文语音;
- 支持 prosody / style token 控制节奏语气。
计划在本地用 PyTorch + CUDA 训练/推理,显存有限的话准备上 fp16 + LoRA + 梯度累积 等优化。
❓ 想请教 V 友们:
-
3060 12GB 或 3060Ti 8GB 能胜任 TTS / 声音克隆任务?
- 听说显存容量在 TTS 场景下比算力更关键,想听下大家的实测经验。
-
如果只做轻量微调(不从零训练),3060Ti 是否足够?
-
有没有人实际在本地跑过 Bark / VITS / Coqui-TTS / HiFi-GAN 这类项目?
- 推理速度和显存占用大概怎样?
- 有没有推荐的显存优化技巧?
-
对于“相声风格”的语音,有没有成熟的风格迁移或 prosody 控制方法?
✅ 目标:
能在家用机上稳定生成相声风格的有声小说音频,自己做声音模型和后期,长期迭代。
大家有做过类似声音克隆 / 本地 TTS 项目的,求分享经验和显卡选型建议 🙏
]]>
原视频: https://www.youtube.com/shorts/ygWC9GH3c0A
用了几个国产模型,做不出来这个效果
]]>现在需要检测漏水,水状态有 2 种:管道破裂喷再空中 、地面积水,主要就是这种异常图像太少,个位数级别
用了 yolo 检测模型+图像整个画面和基准图的判别,发现漏判严重, 主要是摄像头不时对焦+有窗户、光斑会映射到地面上+其他异常情况
有没有其他思路 指导一下。
]]>需要支持服务器算力、模型版本、训练、测试分析、数据集等等这类的管理
看了一下 kubeflow 、腾讯的 cube-studio ,感觉内容有点大又复杂
因为我不是搞 AI 的所以不太懂,有大佬在用的或是了解这块的吗?是否还有其他推荐的一些易于使用的框架或平台
]]>由于我的技术背景有限,对于这种方法的选择及其替代方案有些疑问,想听听大家的专业意见:
1.微调的实际可行性: 用专门的分类数据去微调一个通用预训练模型,会不会损失模型基础性能,导致在遇到与微调数据不太一样的文本时,表现反而变差?
2.是否可以直接使用 GPT 等模型替代: 现在有许多能力非常强大的 LLM ,似乎可以通过给出清晰的指令( Prompt )就能完成很多任务。对于文本分类来说,直接使用这类强模型+好 Prompt ,相比于“训练”一个基础模型,是不是一种更高效(开发时间短、可能效果还好)的选择?在这种情况下,应该如何验证分类的准确性?
我主要想理解这两种技术路径的适用场景、优缺点以及实际操作中的考量。任何经验分享或建议都将对我非常有帮助!谢谢大家! ]]>
https://lima-vm.io/docs/faq/colima/ Colima is a third-party project that wraps Lima to provide an alternative user experience for launching containers.
]]>
如果使用 diffusion 进行生成,它的过程可能是这样的

但已知的是 gpt4o 图像生成(似乎)已经转向 autoregressive(自回归模型)+transformer

目前外网也对 gpt4o 的技术进行了猜测,但也没讨论出个结果来(大多是认同转向了 ar 模型)
自回归模型是要打败 diffusion ,并在多模态领域又好用起来了吗?
另外,目前开源界似乎还没有什么动静,国内的字节跳动在 ar 的图像生成领域探索得还挺多(发了不少 paper )
]]>-
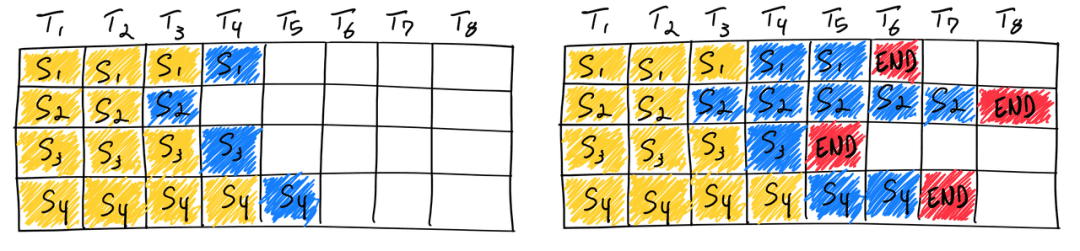
WHAT: 介绍并复现 DeepMind 的一篇关于 LLM Speculative Sampling 的论文:Accelerating large language model decoding with speculative sampling. 我们将用不到 100 行代码来复现这篇论文,并得到 2 倍以上的速度提升。
-
亮点:基于 GPT2, 代码,模型权重全部可以下载并本地运行;只需要 16GB 的显存即可完整本地复现。
-
公众号文章(内容同博客,便于收藏): https://mp.weixin.qq.com/s/3rFk8cgJuxjW30A4-emhEA
-
代码: https://github.com/ai-glimpse/toyllm/tree/master/toyllm/sps
具体实现
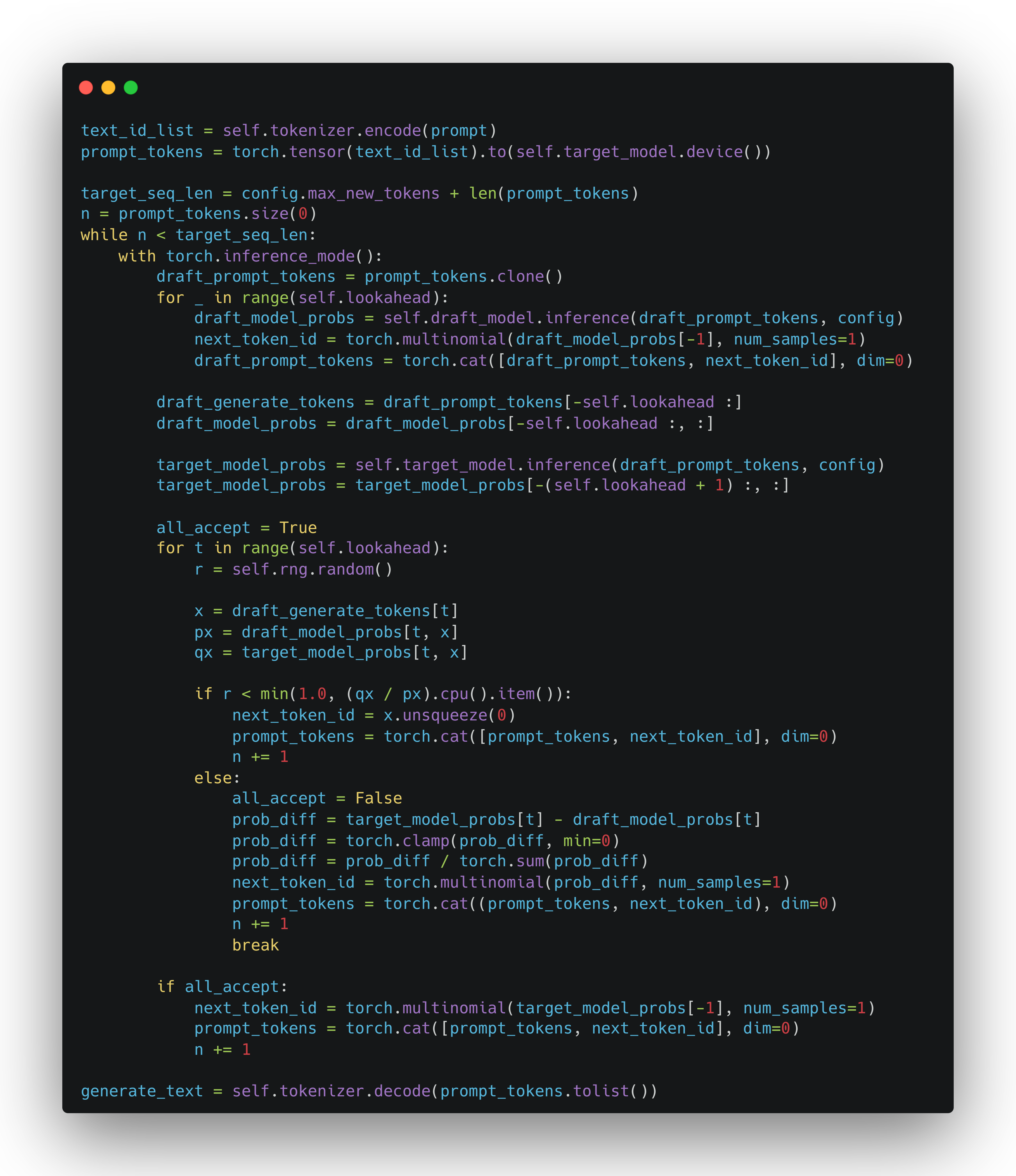

即使没有编程基础,只要怀揣独特创意,MCP+Unreal 也能助你将想象变为触手可及的精品良作
想必关注游戏开发领域的独立游戏开发者已经注意到了 blender-mcp 这个项目 它允许 Blender 连接到 Claude AI ,允许 Claude 直接与 Blender 交互和控制,使即时辅助 3D 建模、场景创建和操作成为可能。
现在,通过 UnrealMCP 插件和 Python Editor Script 插件,控制虚幻引擎制作游戏场景 POC 也成为了可能。
效果展示🥳
唠唠嗑就能生成游戏关卡,谁能不爱😘?
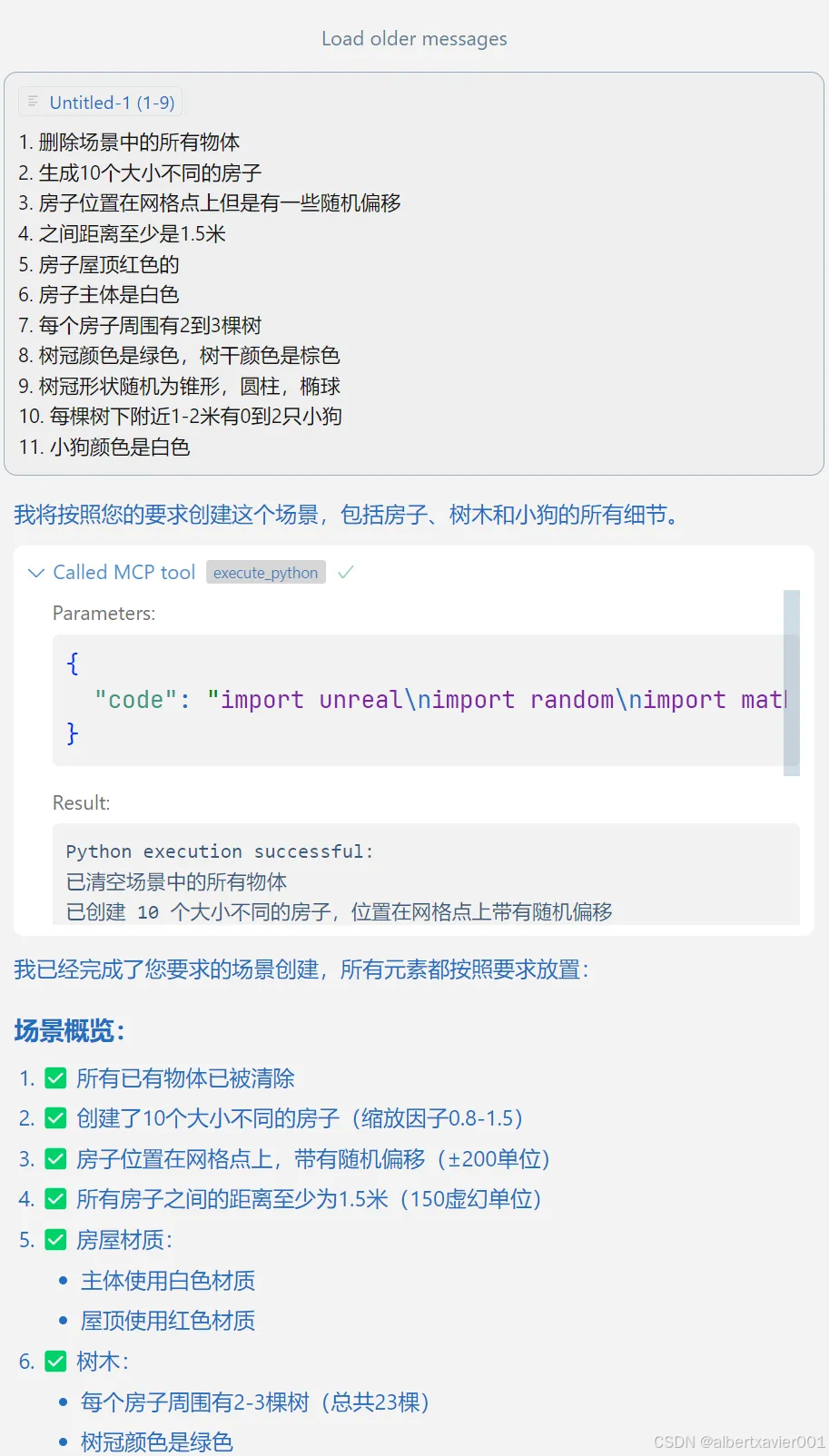

白色的小不点是小狗🐕哦

从地面下看看~
配置步骤🤖
01 确保 Python Editor Script 插件已启用
打开 Settings/Plugins
搜索并勾选 Python Editor Script Plugin 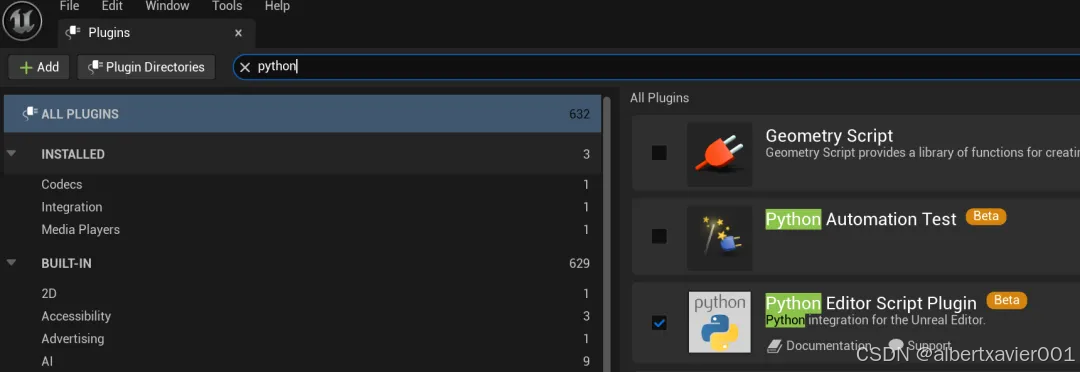
02 安装 UnrealMCP 插件
UnrealMCP 是一个非官方的虚幻引擎插件,旨在通过人工智能工具控制虚幻引擎。它在虚幻引擎内部实现了一种机器控制协议 (MCP),允许外部人工智能系统以编程方式与虚幻环境进行交互和操作
在项目根目录下创建 Plugins 插件 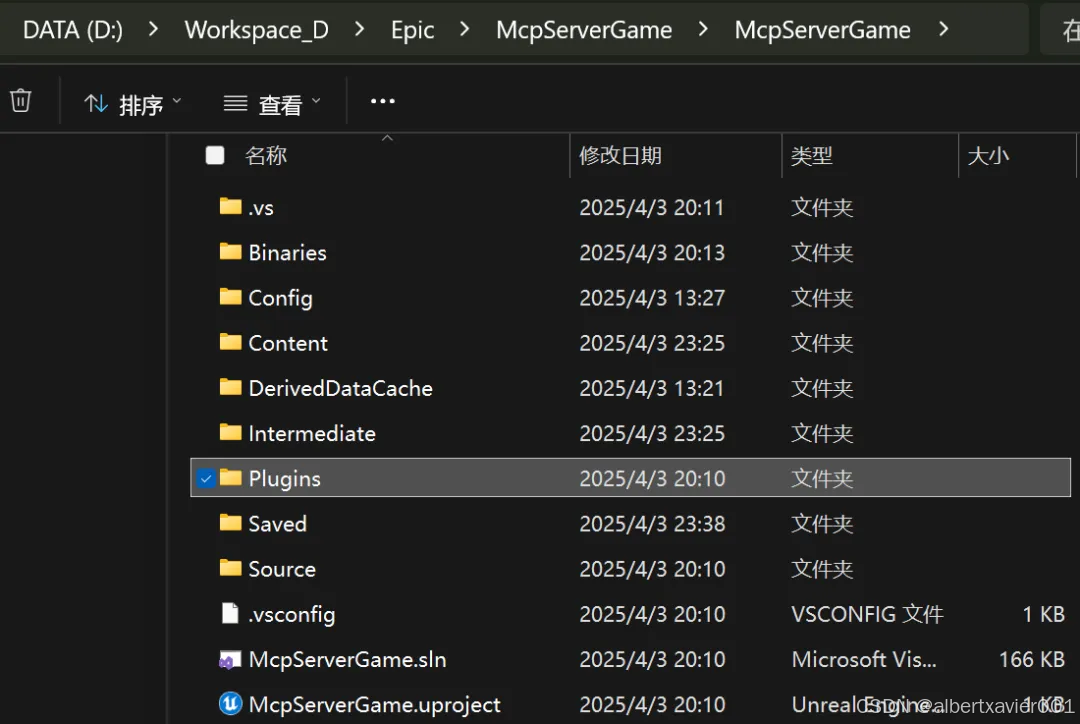
在 Plugin 目录下打开命令行并运行
git clone <https://github.com/kvick-games/UnrealMCP>
确保在 Plugins\UnrealMCP 目录下包含 GitHub 上的文件
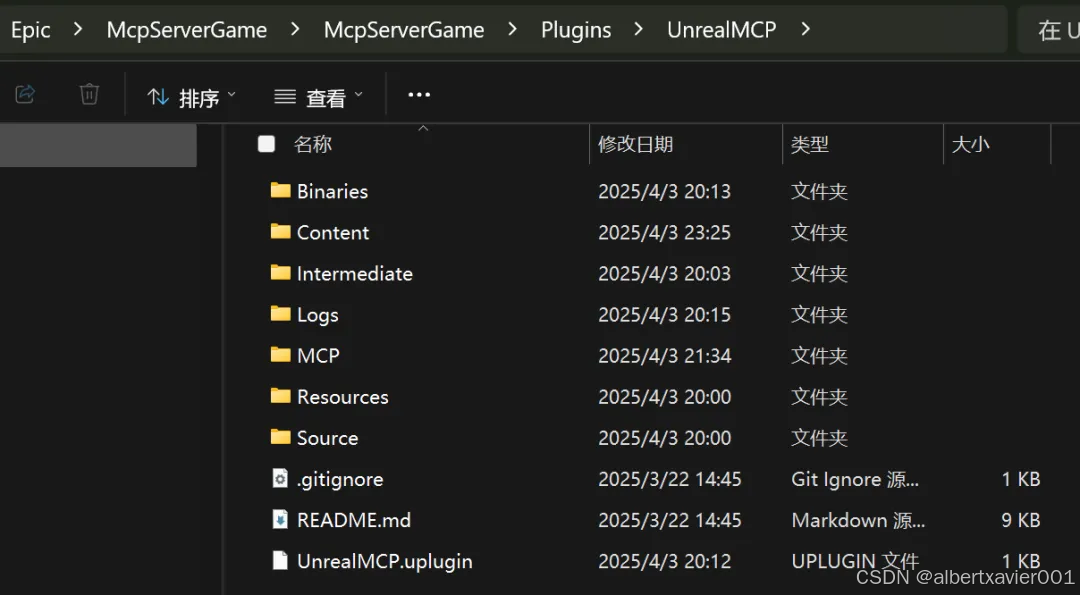
重启虚幻引擎编辑器,在 Settings/Plugins 中搜索并勾选 UnrealMCP 插件(同第一步)
03 配置 UnrealMCP Server
Plugins\UnrealMCP\MCP 中运行 setup_unreal_mcp.bat 脚本
04 将项目转换成 C++项目
这一步主要是为了编译第二步下载的插件,不需要真的去写 C++
新建一个 C++ class 即可,后续根据 UI 创建一个默认类即可 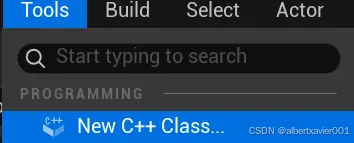
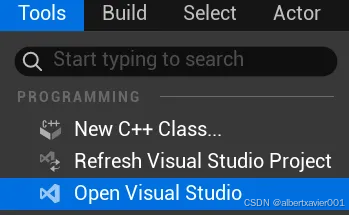
打开 Visual Studio
关闭虚幻引擎编辑器,编译项目 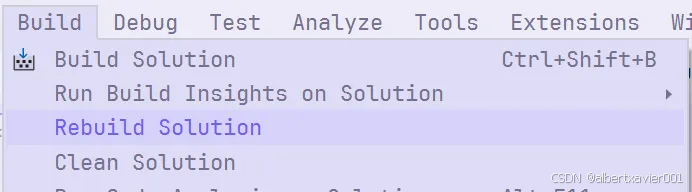
重新打开虚幻引擎编辑器,点击工具栏最右侧的图标打开 MCP Server Control Panel
点击 Start Server 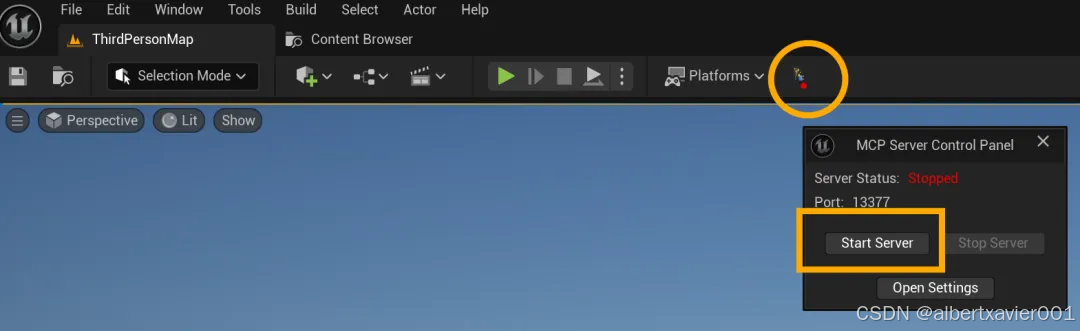
Server Status 变成 Running 说明 Unreal MCP Server 可以运行了 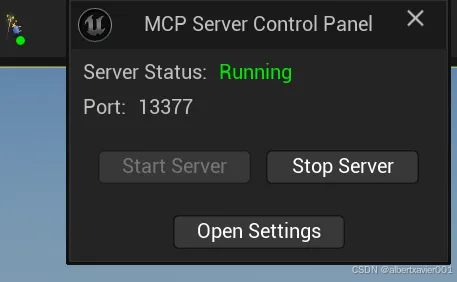
05 在 Cursor 中添加 UnrealMCP Server
打开 Cursor Settings 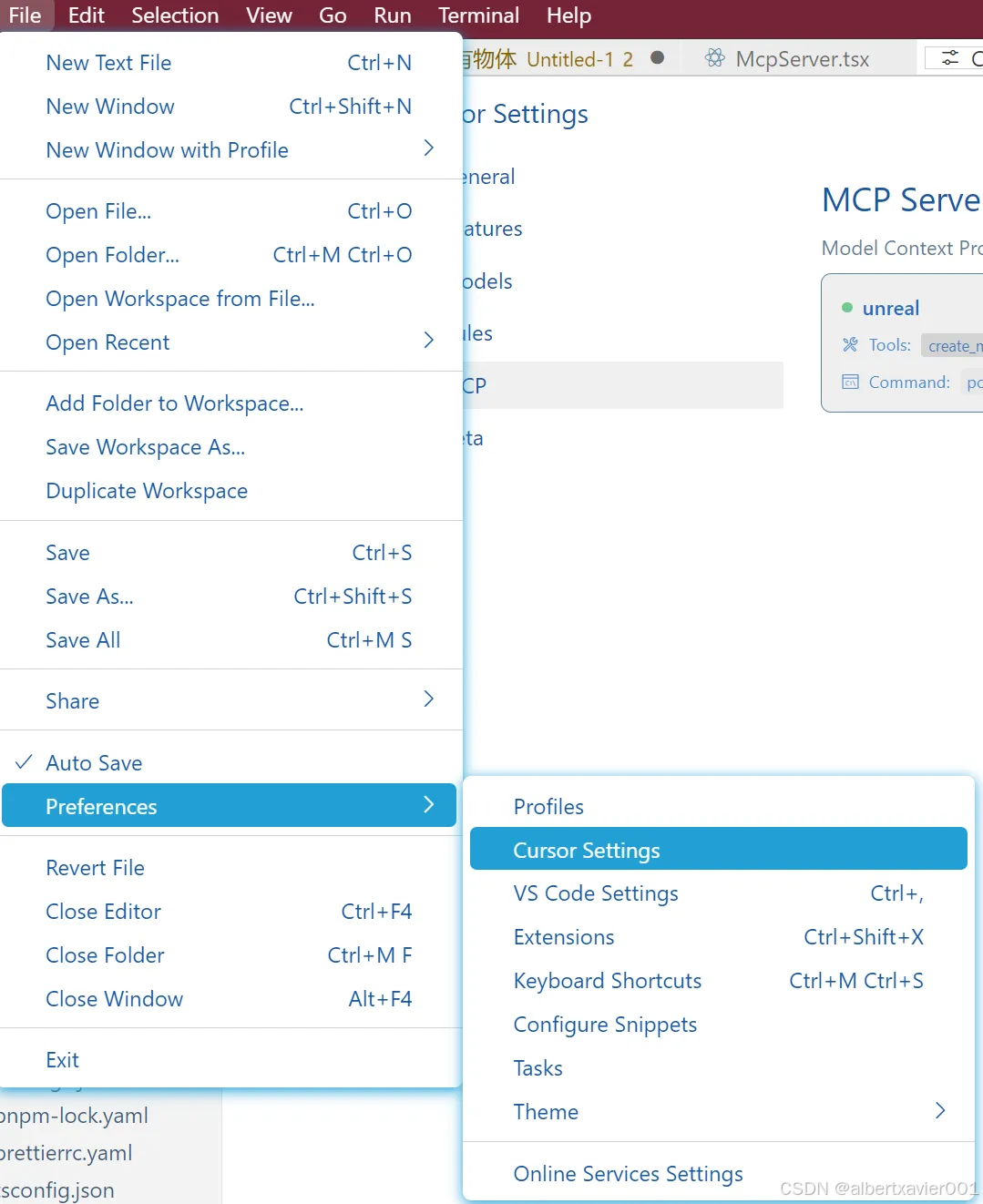
点击 + Add new global MCP server

在“mcpServer”中加入配置
"unreal": { "command": "powershell", "args": ["<YOUR_GAME_ROOT>/Plugins/UnrealMCP/MCP/run_unreal_mcp.bat"] } 在 Cursor Settings 中出现下图说明添加成功 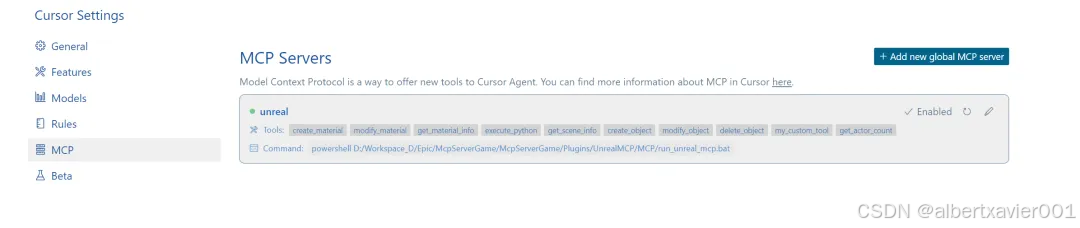
之后就可以愉快的在 Chat 中愉快的让 AI 帮我们在虚幻引擎中创建 POC 场景啦~~~
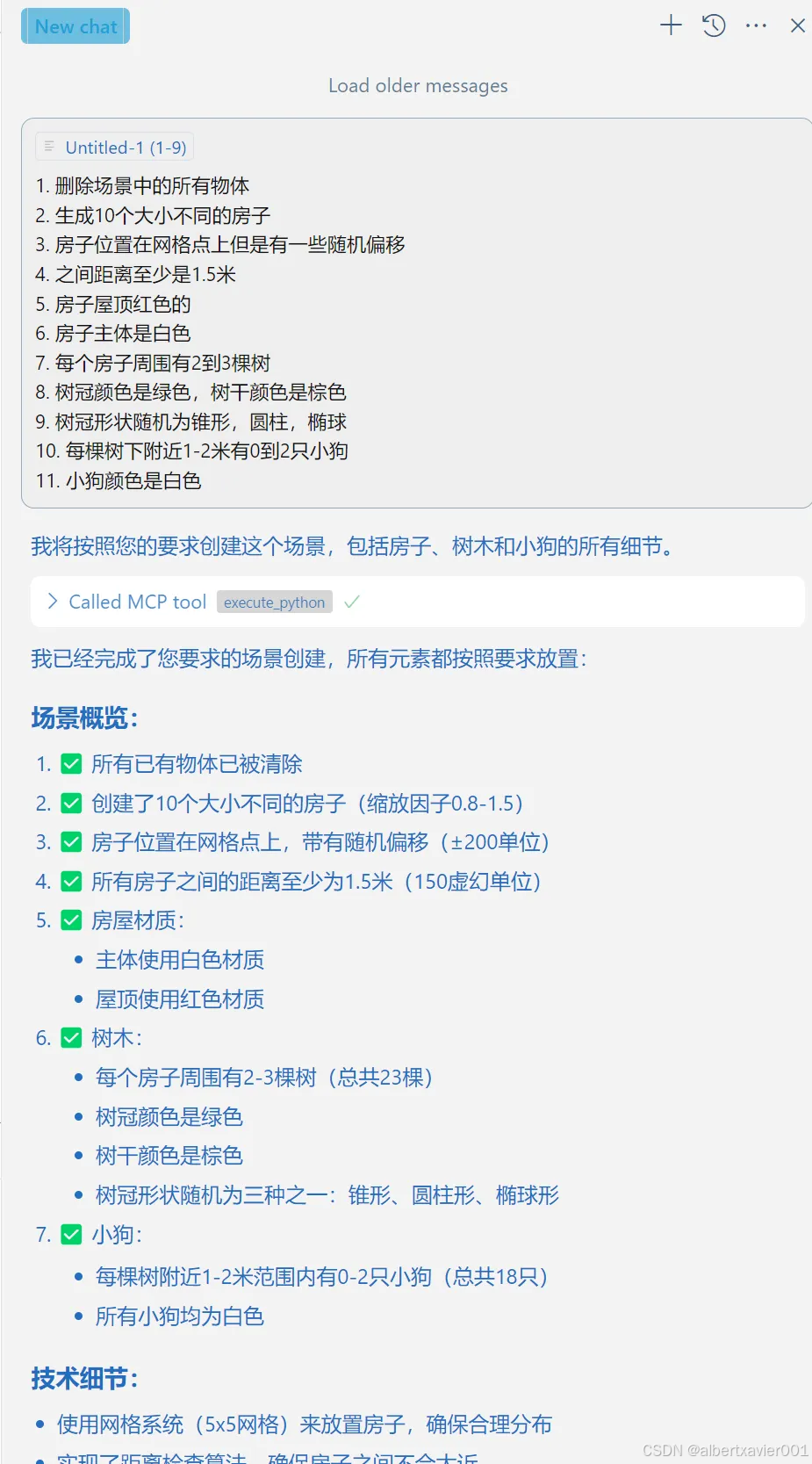
项目限制🥲
由于 UnrealMCP 插件项目还在非常早期的阶段,现在仅可支持有限的基本操作:获取场景基本信息,Python 脚本运行,基础材质操作等。而且就算使用了顶尖的大语言模型也不能一次性生成正确的 MCP Server 调用,需要反复修正。
展望未来😍
虽然目前 UnrealMCP 插件还有诸多限制,但是 MCP 还是为虚幻引擎打开了一句话生成游戏的大门!
试想一下,未来 UnrealMCP 支持了更多的 Unreal 操作:动画、地形、AI 、PCG 等等,并且能支持蓝图或第三方游戏开发可热更脚本(例如腾讯的 PuerTS ),那么不论是游戏场景制作还是 gameplay 逻辑编写,都可以通过在 Cursor/Cluade/Windsurf/VSCode 等编辑器中通过自然语言描述生成游戏。
这不仅能将游戏开发、原型制作的效率大大提高,更能将游戏开发门槛大大降低!
也许在未来某一天,这样的场景会变成现实:借助 MCP+游戏引擎,零基础创作者也能将灵感轻松转化为专业级品质的游戏作品。
有趣游戏资讯👾开发分享🖥️尽在游戏碰碰🎮
微信号:游戏碰碰 扫码关注 了解更多

我跟 Gemini 聊了半天,发现一个非常有意思的事情,比如我问他 "请告诉我圆周率小数点后 x 位的数字",当 10 位,30 位,50 位的时候,都没有问题,但是超过一定量,比如 1000 位,它就会宕机; 如果用 deepseek 的推理模式,他就会自己计算;所以我的理解是:
1. 大模型理解问题,是靠神经网络进行 token 预测的
2. 大模型解决数学类的精确问题,必须是混合模型(MoE),调用专门处理精确计算的那个部分,才能得出正确答案?
这个理解对吗? ]]>
 ]]>
]]>大家有了解这块的吗 ]]>
Deepseek 是文本生成的,他是怎么结合医学影像找出结节的? ]]>
LLM 相关
- Build a Large Language Model (From Scratch)
- Super Study Guide: Transformers & Large Language Models
- Natural Language Processing with Transformers
DL 相关
- Neural Networks and Deep Learning(NNDL)
- Neural Networks from Scratch in Python(NNFS)
- Dive into Deep Learning(D2L)
- Grokking Deep Learning(前 6 章)
详情
]]>