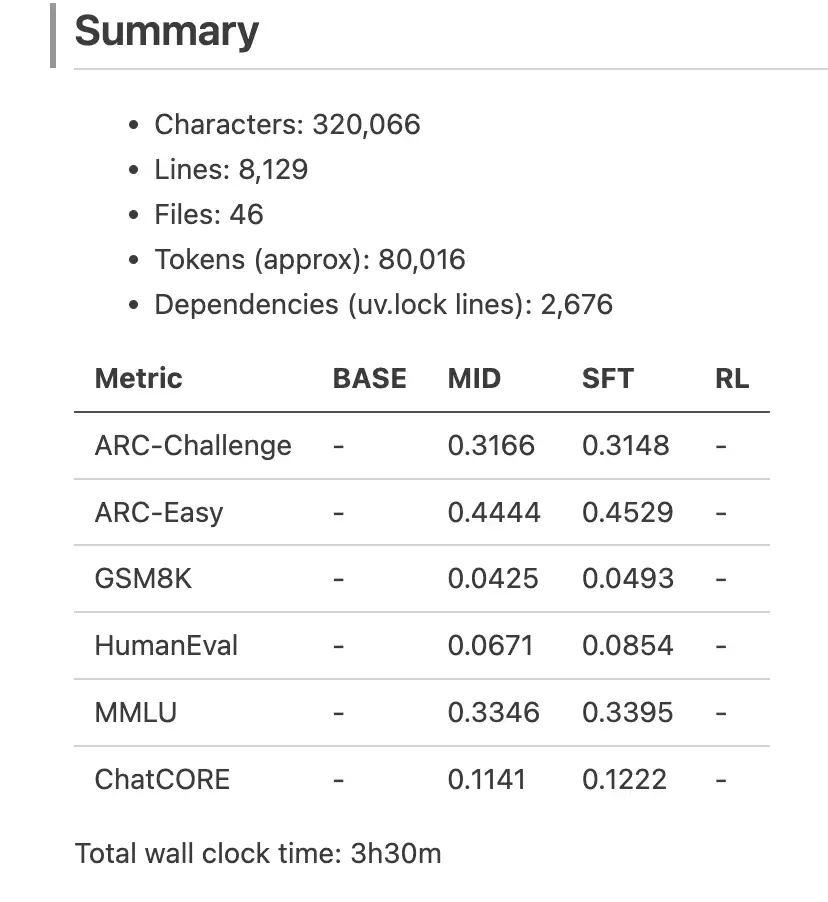
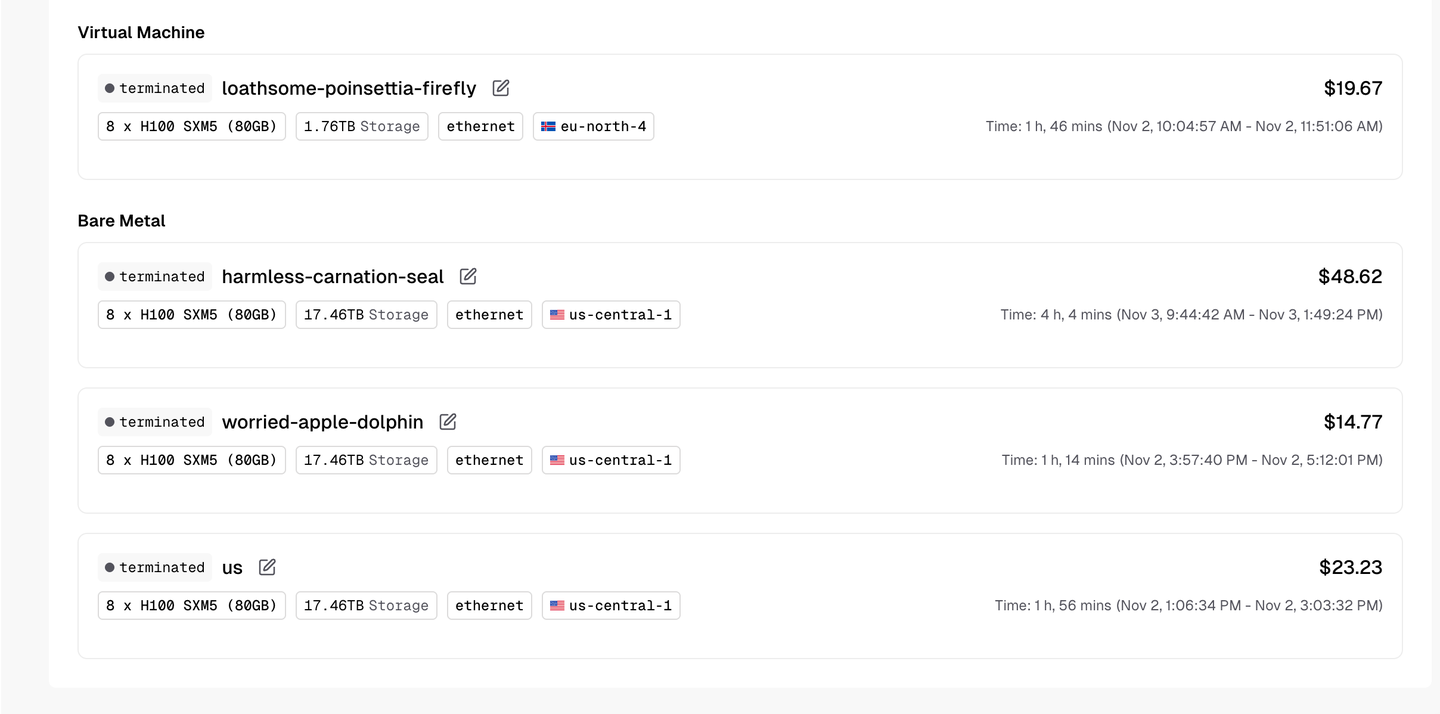
今天刷 Twitter 的时候,发现时间线被一个叫 ClawdBot 的东西刷屏了。
点进去一看,是个开源的 AI 助手框架。能干的事情挺多:通过 Telegram/WhatsApp 远程控制电脑、自动处理邮件、定时跑任务、甚至能帮你和 4S 店砍价(有个老外说靠它省了 4200 美元,虽然我觉得有点玄学)。
手上正好有台吃灰的 VPS ,干嘛不试试?
结果这一试,踩了一晚上的坑。官方文档写得比较散,很多细节要自己摸索。顺手把过程记下来,给想折腾的朋友省点时间。
ClawdBot 是什么
简单说,ClawdBot 是一个本地运行的 AI 助手网关。
它的核心是一个 Gateway 进程,负责:
- 连接各种聊天平台( Telegram 、WhatsApp 、Discord 、iMessage 等)
- 调用 AI 模型( Claude 、GPT 、本地模型都行)
- 执行系统命令、读写文件、控制浏览器
- 管理定时任务和自动化流程
你可以把它理解成一个7x24 小时在线的 AI 员工。它有记忆(知道你之前聊过什么),有手脚(能操作你的电脑),还会主动干活(定时任务、邮件监控)。
根据 Mashable 的报道,这东西火到 Mac mini 都卖断货了——很多人专门买一台小主机放家里,就为了跑这个。
不过我觉得没必要这么激进。一台便宜的云服务器就够了,一个月几十块钱,玩坏了也不心疼。
它能干什么
搭完之后我自己用了一下,体验确实不错:
- 随时随地发消息:手机上给 Bot 发消息,秒回。出门在外也能远程操作服务器
- 查服务器状态:让它跑个
htop或者看 Docker 容器,截图发过来 - 定时任务:每天早上 7 点发一份服务器健康报告
- 写代码调试:把报错信息发给它,它能直接帮你改文件
网上还有人玩得更花:
邮件自动化:每 15 分钟检查一次收件箱,垃圾邮件自动归档,重要邮件立刻推送摘要到手机,还能用你的口吻起草回复。
笔记整理:连接 Obsidian ,自动更新每日笔记,从会议记录里提取待办事项,生成每周回顾。
睡觉时写代码:睡前把一个 Bug 丢给它,它会持续调试、提交、测试,早上起来 PR 就准备好了。
智能家居控制:有人在沙发上看电视,用手机让它帮忙调灯光、查天气、设闹钟。
当然,这些高级玩法需要配置额外的 Skills 和集成。本文先讲基础安装,能聊天、能执行命令就算成功。

准备工作
你需要:
| 项目 | 说明 |
|---|---|
| 一台服务器 | 云服务器(我用的 Ubuntu 24.04 )、Mac mini 、旧电脑、树莓派都行,最好是国外的,不然网络环境都有的折腾了! |
| Telegram 账号 | 用来创建 Bot |
| Claude/GPT API | 官方的或者中转站都行,后面会细说 |
关于设备选择
云服务器(推荐新手)
优点:便宜(最低几十块/月)、玩坏了不心疼、7x24 在线 缺点:需要一点 Linux 基础
Mac mini
优点:性能好、功耗低、能跑 macOS 专属功能( iMessage 等) 缺点:贵( 4000+ 起步)、权限太高有安全风险
我的建议:
新手先用 VPS 试水。等熟悉了再考虑要不要买专门的设备。如果真要用 Mac mini ,别用日常工作的那台——万一配置出问题,或者 Key 泄露了,后果可能很严重。
安装方式
ClawdBot 支持多种安装方式,我按推荐程度排序:
方式一:一键安装脚本(推荐)
官方提供的快速安装命令,会自动处理依赖和权限问题:
# Linux / macOS curl -fsSL https://get.clawd.bot | bash # 安装完成后运行引导向导 clawdbot onboard --install-daemon 这个脚本会自动检测系统、安装 Node.js 22+、处理 npm 权限、全局安装 clawdbot 。
方式二:手动 npm 安装
如果你已经有 Node.js 22+:
npm install -g clawdbot@latest 详细安装步骤
下面用手动方式演示。虽然一键脚本更方便,但手动装能让你更清楚每一步在干嘛,出问题也好排查。
第一步:安装 Node.js 22+
ClawdBot 要求 Node.js 22 以上。Ubuntu 自带的版本太老,得手动装。
# 添加 NodeSource 仓库 curl -fsSL https://deb.nodesource.com/setup_22.x | bash - # 安装 apt-get install -y nodejs # 验证 node -v # 输出 v22.x.x 就对了 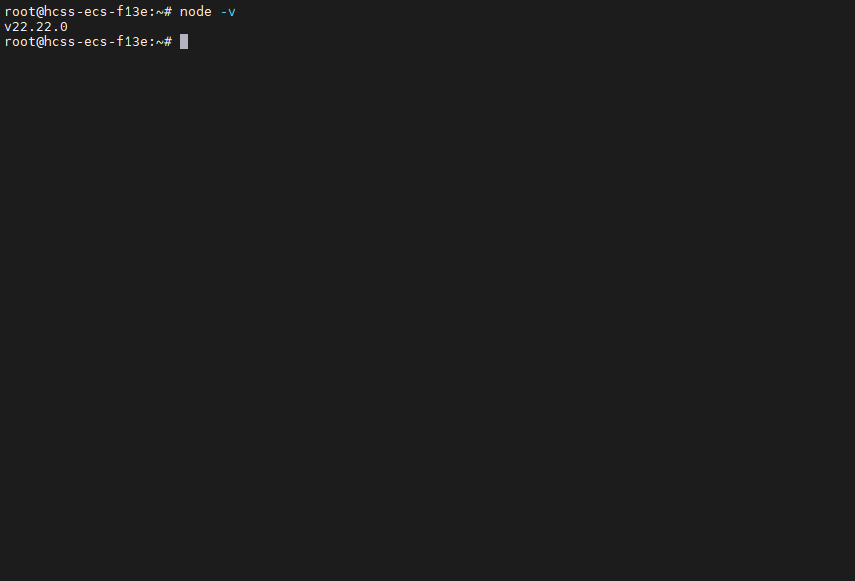
踩坑 1:别直接
apt install nodejs,那样装的是老版本(通常 v12 或 v18 ),后面会报各种兼容性错误。
第二步:安装 ClawdBot
npm install -g clawdbot@latest 装完验证:
clawdbot --version 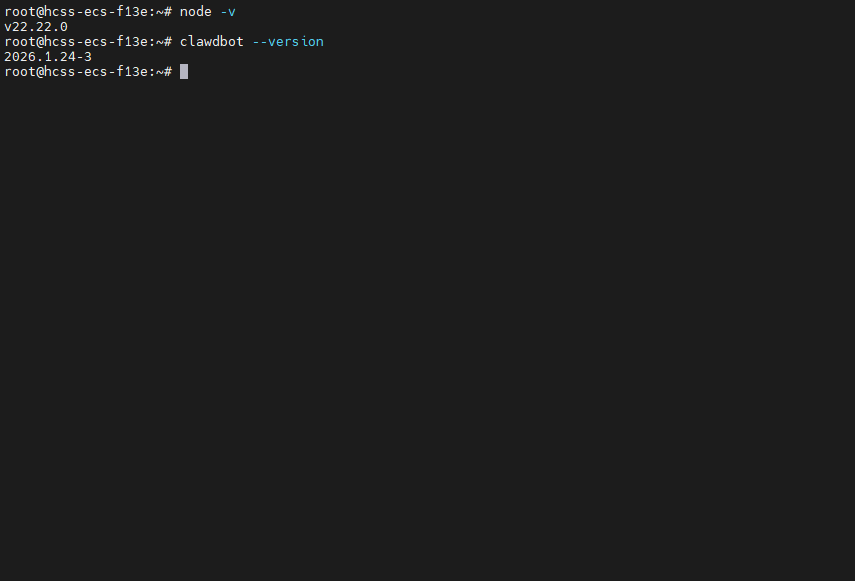
踩坑 2:如果报
EACCES权限错误,说明 npm 全局目录权限有问题。解决方法:mkdir -p ~/.npm-global npm config set prefix '~/.npm-global' echo 'export PATH=~/.npm-global/bin:$PATH' >> ~/.bashrc source ~/.bashrc
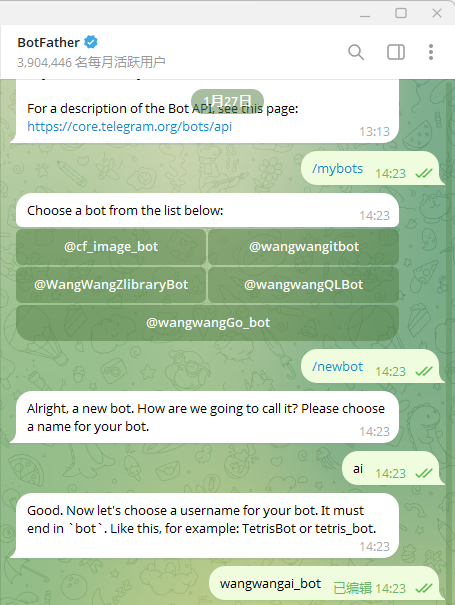
第三步:创建 Telegram Bot
打开 Telegram ,搜索 @BotFather,发送 /newbot。这里好像必须新建!
按提示设置:
- 给 Bot 起个名字(显示名称)
- 设置用户名(必须以
bot结尾,比如my_clawd_bot)
最后会给你一串 Token:
1234567890:ABCdefGHIjklMNOpqrSTUvwxYZ1234567890 存好这个 Token,后面要用。
第四步:准备 API
这一步最容易踩坑。
用官方 API
- 去 console.anthropic.com 注册
- 创建 API Key (以
sk-ant-开头) - 充值一点余额
用中转站 API
如果用中转站,注意三点:
- 必须支持 OpenAI 兼容格式
- 必须支持 工具调用( function calling )
- 确认 没有分组限制
踩坑 3:这里我是直接用的 CLI Proxy API 这个开源项目中转的 API,选的 gemini-3-flash 模型,感觉非常舒畅!
第五步:写配置文件
创建配置目录:
mkdir -p ~/.clawdbot nano ~/.clawdbot/clawdbot.json 根据你的 API 类型选配置模板:
模板 A:Anthropic 官方 API
{ "gateway": { "mode": "local", "bind": "loopback", "port": 18789 }, "env": { "ANTHROPIC_API_KEY": "sk-ant-你的密钥" }, "agents": { "defaults": { "model": { "primary": "anthropic/claude-sonnet-4-5-20261022" } } }, "channels": { "telegram": { "enabled": true, "botToken": "你的 Bot Token", "dmPolicy": "pairing" } } } 模板 B:OpenAI 兼容的中转站
{ "gateway": { "mode": "local", "bind": "loopback", "port": 18789 }, "agents": { "defaults": { "model": { "primary": "gemini/gemini-3-flash" }, "elevatedDefault": "full" , "workspace": "/wangwang", "compaction": { "mode": "safeguard" }, "maxConcurrent": 4, "subagents": { "maxConcurrent": 8 } } }, "models": { "mode": "merge", "providers": { "gemini": { "baseUrl": "https://你的中转站 API/v1", "apiKey": "test", "api": "openai-completions", "models": [ { "id": "gemini-3-flash", "name": "gemini-3-flash" } ] } } }, "channels": { "telegram": { "botToken": "你的 TG Token" } }, "plugins": { "entries": { "telegram": { "enabled": true } } } } 踩坑 4:
api字段必须填openai-completions。我一开始填的openai-chat,死活启动不了。
踩坑 5:
models数组不能省,不然报错说缺少必填项。注意 agents 中也有配置模型名,别忘了改!
第六步:启动测试
clawdbot gateway --verbose 看到这两行就成功了:
[gateway] listening on ws://127.0.0.1:18789 [telegram] [default] starting provider (@你的 Bot 名字) 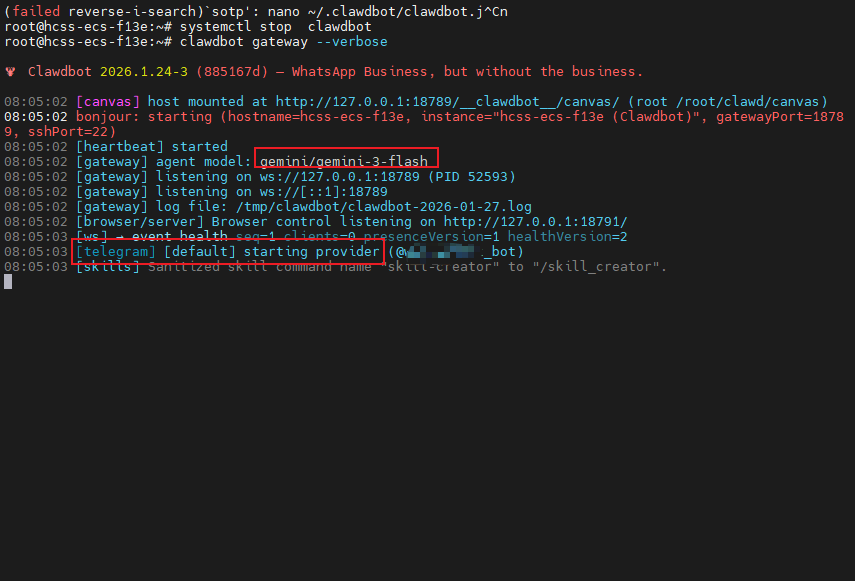
第七步:配对
第一次给 Bot 发消息,它会回复配对码:
Pairing code: X9MKTQ2P Your Telegram user id: 123456789 在服务器上执行:
clawdbot pairing approve telegram X9MKTQ2P 配对完成后,只有你的账号能和 Bot 对话,别人发消息它不会理。
记下你的 Telegram User ID,后面设置权限白名单要用。
后续有啥需求就直接 tg 对话,让 AI 自行配置就行了!比如我让它帮我集成了 exa 的搜索功能!

设置开机自启
用 nohup 跑的话,SSH 一断就挂了。上 systemd:
cat > /etc/systemd/system/clawdbot.service << 'EOF' [Unit] Description=ClawdBot Gateway After=network.target [Service] Type=simple User=root ExecStart=/usr/bin/clawdbot gateway --verbose Restart=always RestartSec=5 EnvirOnment=HOME=/root [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable clawdbot systemctl start clawdbot 这样就完事了。开机自动启动,挂了 5 秒后自动重启。
日常维护
几个常用命令:
# 看运行状态 systemctl status clawdbot # 看实时日志 journalctl -u clawdbot -f # 重启 systemctl restart clawdbot # 健康检查 clawdbot doctor # 全面状态 clawdbot status --all 进阶:命令白名单
如果想让某些命令自动执行,不用每次批准:
# 允许 docker 命令 clawdbot approvals allowlist add --agent "*" "docker *" # 允许 systemctl clawdbot approvals allowlist add --agent "*" "systemctl *" # 允许 /usr/bin 下的程序 clawdbot approvals allowlist add --agent "*" "/usr/bin/*" # 查看当前白名单 clawdbot approvals allowlist list 进阶:定时任务
ClawdBot 内置 Cron 功能。比如每天早上 7 点发送服务器状态:
clawdbot cron add --schedule "0 7 * * *" \ --timezone "Asia/Shanghai" \ --message "检查服务器状态,给我发个简报" \ --deliver telegram \ --to "你的 TG 用户 ID" 或者写进配置文件:
{ "cron": { "jobs": [ { "id": "daily-report", "schedule": { "cron": "0 7 * * *", "timezone": "Asia/Shanghai" }, "sessionTarget": "isolated", "payload": { "agentTurn": { "message": "检查服务器状态,生成简报" } }, "deliver": { "channel": "telegram", "to": "你的 TG 用户 ID" } } ] } } 常见问题
clawdbot: command not found
npm PATH 问题。确认全局目录在 PATH 里:
npm config get prefix echo 'export PATH=$(npm config get prefix)/bin:$PATH' >> ~/.bashrc source ~/.bashrc 端口被占用
默认端口 18789 冲突了:
lsof -i :18789 # 看谁在用 clawdbot gateway --port 18790 --verbose # 换个端口 Bot 收到消息但不回复
按顺序检查:
- Gateway 在不在跑:
clawdbot status - 配对了没:
clawdbot pairing list telegram - API 还有没有额度
- 看日志:
journalctl -u clawdbot -f
all models failed
API 配置问题:
- Key 对不对
- baseUrl 格式对不对(结尾有没有
/v1) - model id 写对没
- 跑一下
clawdbot doctor
工具调用失败
你的 API 不支持 function calling 。这种情况 Bot 能聊天,但执行命令用不了。换一个支持工具调用的 API 。
完整配置示例
一个功能完整的配置,开箱即用:
{ "gateway": { "mode": "local", "bind": "loopback", "port": 18789 }, "agents": { "defaults": { "model": { "primary": "openai-compat/claude-sonnet-4-5-20261022", "fallback": ["openai-compat/claude-haiku-3-5-20241022"] }, "elevatedDefault": "full", "thinking": "medium" } }, "models": { "mode": "merge", "providers": { "openai-compat": { "baseUrl": "https://你的 API 地址/v1", "apiKey": "你的密钥", "api": "openai-completions", "models": [ { "id": "claude-sonnet-4-5-20261022", "name": "Claude Sonnet 4.5" }, { "id": "claude-haiku-3-5-20241022", "name": "Claude Haiku 3.5" } ] } } }, "tools": { "exec": { "backgroundMs": 10000, "timeoutSec": 1800, "cleanupMs": 1800000, "notifyOnExit": true }, "elevated": { "enabled": true, "allowFrom": { "telegram": ["你的 TG 用户 ID"] } }, "allow": ["exec", "process", "read", "write", "edit", "web_search", "web_fetch", "cron"] }, "channels": { "telegram": { "enabled": true, "botToken": "你的 Bot Token", "dmPolicy": "pairing", "allowFrom": ["你的 TG 用户 ID"], "groupPolicy": "disabled" } }, "cron": { "jobs": [] } } 配置亮点:
fallback:主模型挂了自动切备用thinking: medium:启用中等深度思考groupPolicy: disabled:只响应私聊,不进群- 双重白名单:elevated 和 channels 都设了 allowFrom
总结
整个过程折腾了大半天,大部分时间花在排查配置格式上。
几个关键点:
- Node.js 版本:必须 22 以上
- API 要通用:别用有分组限制的 Key
- 配置格式严格:
api字段、models数组这些容易出错 - 用 systemd 管理:别用 nohup
- 安全第一:白名单必须设,日志定期看
搭完之后确实方便。出门在外随时能跟服务器交互,定时任务也不用自己写脚本了。
但说实话,这东西更适合有一定技术基础的人。如果只是想聊天,直接用 Claude 官网就够了。折腾 ClawdBot ,图的是「可控」和「自动化」。
]]>