
之前用的乐橙( IMOU ) TS2F-4M 400 万,现在 200 多,也凑合用,在想有没有更高清一点的呢,夜间,白天,录像。
感谢各位热心网友的
回复。 ]]>

福利来啦~
透视宝业务监控,一眼定位业务故障。现在申请,还能得畅享书(限 12 本)。

活动时间: 2016 年 12 月 16 日- 2016 年 12 月 23 日
申请地址: http://cloudwise.mikecrm.com/M9FuX9

基于全局业务拓扑的问题发现
自动发现业务系统的全局应用拓扑,快速定位影响业务运行的应用性能问题和具有潜在风险的技术栈,支持钻取。

分布式业务系统的单次交易跟踪
追踪每笔交易的完整 IT 链路,根据调用时间序列采集全部交易环节的服务性能数据,实现按服务深入追踪交易性能问题

业务性能的主动感知与秒级告警
针对关键交易的性能指标,设定告警阈值,主动发现性能问题并进行告警消息的即时推送与协同事件处理

业务质量评估及业务 SLA 保障
以量化手段对服务质量进行评估,建立 SKPI 评价体系确保业务 SLA 高可用

立即体验,赢畅销书籍: http://cloudwise.mikecrm.com/M9FuX9 ]]>
透视宝业务拓扑分析
以业务系统的构建和问题分析为导向,能自动将原有离散的应用、前端、后台任务、数据库及基础设施,整合呈现为符合业务逻辑、清晰严谨的业务系统架构。通过业务系统拓扑图的性能分析,帮助您分析系统各个组件的性能问题。

申请体验地址: http://cloudwise.mikecrm.com/M9FuX9
全局掌控业务运行状态
透视宝业务拓扑分析,帮助您从整个业务流程的角度,来考虑系统架构、资源维护、性能监控与优化等。从全局掌握企业中所有业务的运行状态、业务间的调用关系及资源调用情况等。
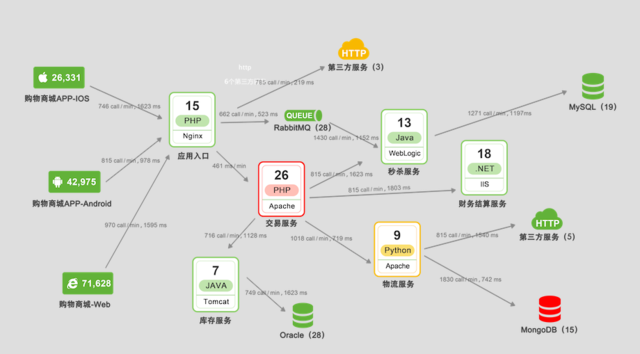
自动发现业务逻辑
透视宝业务拓扑分析创造性的实现业务逻辑关系的自动发现。既能智能的发现业务与业务、业务与资源依赖、业务与组件调用的关系,以及各业务互调的性能问题。为业务建立全过程快照,可详细查看各组件的当前性能状态,快速发现影响性能的业务和最慢的组件,挖掘性能消耗的热点。
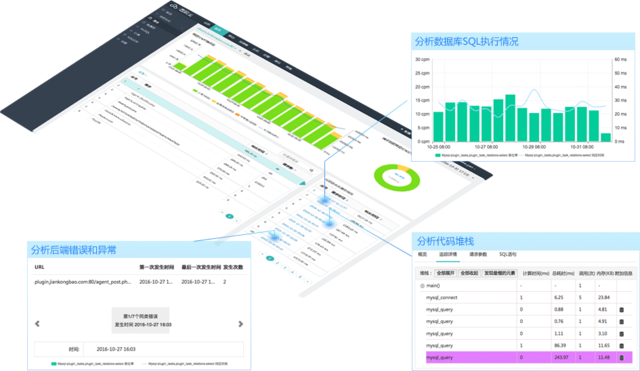
故障快速定位
通过查看所有业务和资源的全局拓扑结构,快速定位运行过慢和出错的应用,并通过资源调用了解资源使用情况。
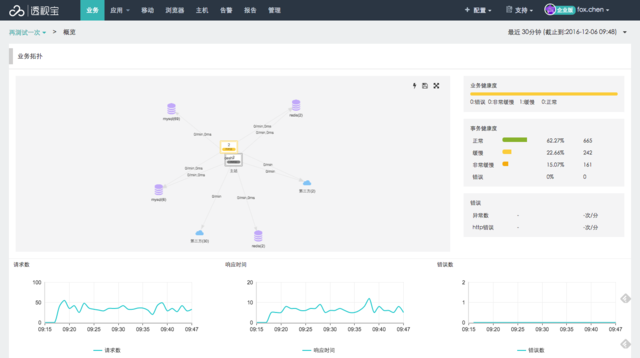
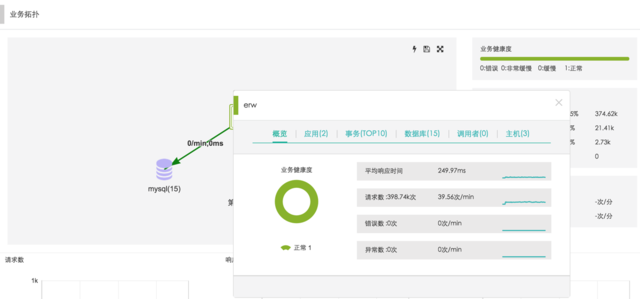
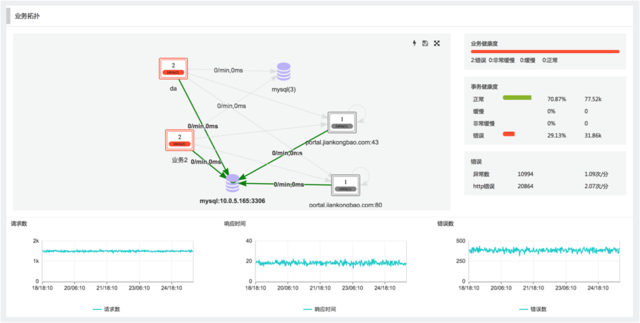
业务状态层层深入分析
点击业务可以查看当前时间段内的详细情况,包括:概览、应用、事务( TOP10 )、数据库、调用者和主机等情况。并且在每一栏信息展示中,都可以点击进入相应的性能情况的详情页面,便捷的对业务状态进行深度分析。 点击拓扑中的数据库或者第三方 API ,可以查看在该业务系统中数据库的性能情况和第三方 API 被调用的情况。
想快速看清你的业务? 快来体验吧: http://cloudwise.mikecrm.com/M9FuX9
]]>企业上新系统,跨应用系统之间的数据如何准确追踪?
人工画图永远无法快速、准确的获取 IT 系统拓扑结构,如何快速的了解其 IT 架构?
随着微服务架构的流行,基于业务领域的 IT 部署需求明显,传统企业架构如何转型?
透视宝业务拓扑分析
以业务系统的构建和问题分析为导向,能自动将原有离散的应用、前端、后台任务、数据库及基础设施,整合呈现为符合业务逻辑、清晰严谨的业务系统架构。通过业务系统拓扑图的性能分析,帮助您分析系统各个组件的性能问题。
申请体验地址: http://cloudwise.mikecrm.com/M9FuX9
全局掌控业务运行状态
透视宝业务拓扑分析,帮助您从整个业务流程的角度,来考虑系统架构、资源维护、性能监控与优化等。从全局掌握企业中所有业务的运行状态、业务间的调用关系及资源调用情况等。

自动发现业务逻辑
透视宝业务拓扑分析创造性的实现业务逻辑关系的自动发现。既能智能的发现业务与业务、业务与资源依赖、业务与组件调用的关系,以及各业务互调的性能问题。为业务建立全过程快照,可详细查看各组件的当前性能状态,快速发现影响性能的业务和最慢的组件,挖掘性能消耗的热点。

故障快速定位
通过查看所有业务和资源的全局拓扑结构,快速定位运行过慢和出错的应用,并通过资源调用了解资源使用情况。

业务状态层层深入分析
点击业务可以查看当前时间段内的详细情况,包括:概览、应用、事务( TOP10 )、数据库、调用者和主机等情况。并且在每一栏信息展示中,都可以点击进入相应的性能情况的详情页面,便捷的对业务状态进行深度分析。
点击拓扑中的数据库或者第三方 API ,可以查看在该业务系统中数据库的性能情况和第三方 API 被调用的情况。

想快速看清你的业务?快来体验吧: http://cloudwise.mikecrm.com/M9FuX9 ]]>

网络游戏是对用户体验要求最严苛的 IT 行业之一,任何 IT 问题造成的业务不稳定,都可能导致玩家的流失,进而影响游戏商的营收。因此,自动化运维对于游戏平台的重要不言而喻,各种 DevOps 产品和自动化运维技术方案不断涌现,包含发布变更、容量伸缩、故障自愈等多种场景的游戏运维技术日趋成熟,这些改变都让运维工作流程越来越简化。
然而流程的简化并不意味着运维变得容易,恰恰相反随着云计算、移动互联网的广泛应用,游戏业务对运维的要求水涨船高!相比起对 IT 基础设施运维操作的需求,业务侧更需要运维提供高质量的业务保障服务,包括对业务架构及部署的持续优化,精细化的游戏健康度管理,以及快速的故障处理服务等。
以下就是由马辰龙先生为我们分享他在日常工作中总结的《游戏平台运维自动化扩展之故障自愈》:
大家好,我们用一个例子作为今天分享的开始,越来越复杂的网络问题常常会造成各种误报,导致各种误报信息的轰炸,出现报警我们一般先看报警内容,这种情况大家都遇到过吧?久而久之就造成了对告警信息的麻木。比如凌晨 2 点某机房切割网络抖动,一下过来几百条告警短信,相信大家不可能一条条的看。
首先我们要解决的是误报的问题。现在的监控软件无非就是 Zabbix 、 Nagios 或者 SmokePing 这类,还会有一些单点监控软件。如果想消除误报只有多 IDC 去部署监控服务器,搭建多节点去监控网络问题,但这就需要使用大量的服务器资源,有没有什么好的解决方案呢?而且即使我们搭建了大量的监控服务器,又怎么去集中处理告警消息呢? 经过对市面上流行的监控类产品进行广泛调研,发现云智慧的监控宝可以通过分布式监测节点,多区域同时监控服务器、网站的健康状况,同时还提供一些国外节点(我们的业务涉及海外)监测海外用户的业务访问体验,而且阈值和监控方式也可以根据业务的实际需求去自定义。
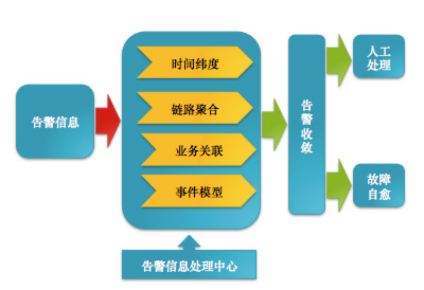
当然作为一个崇尚运维自动化的运维人员,我看中的不仅是这些,更重要的是能够 callback 告警消息。如果是因为服务器网络或者其他原因导致宕机,在收到告警消息之后,让后端系统能够根据消息去自动处理是不是会更好呢。给大家看一副图来理解下:
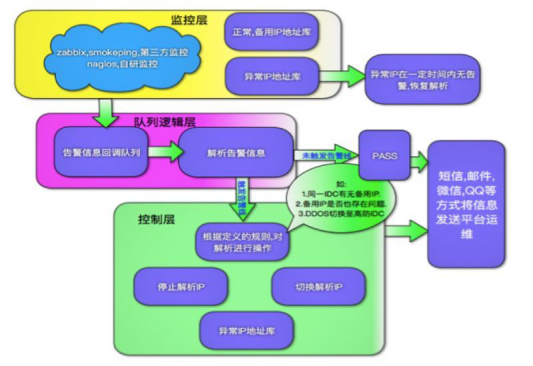
根据回调信息,事先将其定义成一些规则,当我们匹配到了告警信息中的特定信息可以自主切换。 监控宝的 URL 回调可以在这里设置:
运维监控的发展:
过去: Nagios 、 Cacti 、 Zabbix 监控单一,对告警后知后觉;
现在: API 监控数据聚合、告警信息收敛,自动化感知;
未来:挖掘故障信息,制定故障自愈规则,提前感知。
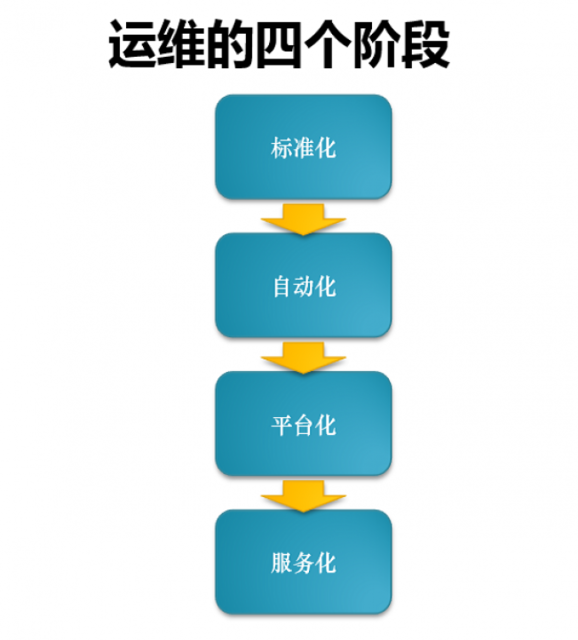
运维的建设有四个阶段,简称为四化建设:第一个阶段就是标准化。标准化的意思是把主机名、内网以及配置文件统一起来,如果不统一,后面的东西就无法继续。没有一个标准化的环境,脚本是无法写下去的。第二个阶段是自动化。中小型企业阶段都是自动化到平台化的过渡,平台化就是把自动化的东西分装,把功能整合,把数据做聚合,然后放在平台上来可视化。第三个阶段是平台化。以后的趋势是脚本和功能必须是外部化的,这样新来的一个人才能接手。不用在服务器上跑脚本,还要同下个人交代在哪儿装。最后一个阶段就是服务化。服务化是指现在云平台所承载的东西。举个例子,搭一个 redis 集群,用户不需要知道服务器有多少个,因为所提供的 NOSQL 服务打开后,用户就可以直接使用了。
所以我们未来要做的就是收集告警信息进行自动化处理,而不是通知运维上线处理。我们要脱离那种每天等着告警信息去处理故障,要主动出击,不要等到故障了再去处理,而且即使事后处理好了,那么时间成本也是很高的。 再举个栗子,一个网站在全国各地会解析为多个 IP ,而且还会有备用 IP 用来切换(被 DDOS 的时候, IP 被封,我们需要切换)。我们会有一个脚本去检测这些 IP 的状态,当这些 IP 正常的时候才会切换到这些 IP 上,如果 Ping 不通或者有其他故障就不会去切换,否则去切换一个故障 IP 不是没有用吗?
我们在做监控的时候需要考虑很多不可控的因素,因此在写代码的时候要首先考虑异常状态,否则会造成二次故障,这是我们不愿意看到的。当故障 IP 2 小时内不丢包,我们就把他去掉,下次切换的时候就可以用到,反之亦然。这里提示下,对于这种时间周期可以使用 redis , expire 指定 ttl 。 给大家一张图来理解下告警信息的分类:
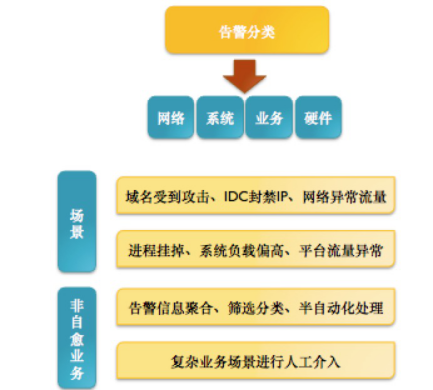
我们要做到能自动化的尽量自动化,不能自动化的我们要让它半自动,人工介入处理是最后的方案,因为是人就会犯错,尤其在业务出现异常,操作都是不可控的。 说这么多 ,核心就是需要建立自己的消息处理中心来分析问题,充分利用告警信息,大概的模型可以是这样:
最后,故障自愈能够给我们带来什么:
1 、非工作时间运维人员处理故障以及响应时间;
2 、减少直接的线上操作、避免出现人为原因的二次故障;
3 、提高运维人员对故障原因的分析、以及工作积极性;
4 、提升运维的自身价值。
Q&A
问:如何做告警收敛?
答:比如我们以一台服务器为单位,每分钟的告警信息分为系统和网络告警,统一处理。(当然也能以收件人,业务关联为单位。)
问:对于传染型的故障,不知道有没有什么好的方案呢,就是反复访问一个问题导致骨牌性的反应。
答:比如网站报了 500 错误,那么我们发现 500 错误的时候,在告警的时候可以让它去错误日志里收集关于相同 IP 的 error ,一起发送。
问:怎么自动化的?
答:减少我们去服务器查日志的时间,频繁的 grep xxx 。
问:百度爬虫并发大没抗住,怎么自动化处理?
答:首先你是想让它爬还是不爬,不爬就匹配 useragent 。
问:你们故障自愈是哪些情况?是通过日志?还是 api url 监控?通过特定故障返回特定值??因为 java 的日志各种情况都有。
答:面对 DDOS 流量型攻击,通过分析 url 使用防火墙封禁,首先是日志。
问: DDOS 怎么分析 url ??有什么特征吗??
答: DDOS 是没有日志的,可以通过网络告警去触发, CC 攻击分析你的 URL ,规则可以自己去定义,有些注入、刷 API 等通过正则去匹配。运维人员要利用好日志,所有的问题都是从日志中分析行为发现的。
问:我们上了 ELK , Java 除了假死自动重启,好像没什么自愈的。
答: ELK 可以使用 API 拉日志,去分析业务的运行状态, ELK 的面太大,这里细节就不多说了。
]]>监控宝
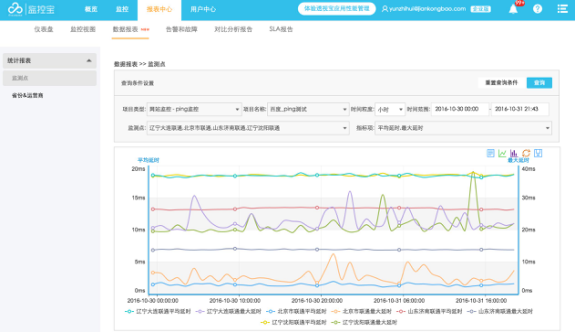
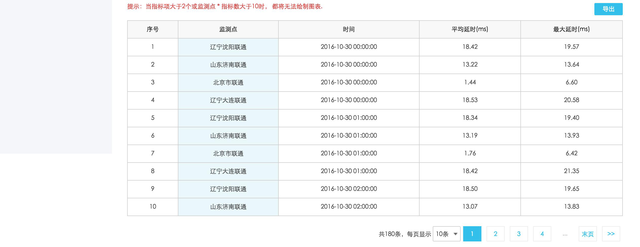
1 、企业版“报表中心”新增“数据报表”模块
数据报表可进行不同监测点的多个指标数据对比,支持折线图、柱状图、折柱混搭视图切换,数据报表可导出。目前支持 Ping 监控监测点和省份运营商两个维度的报表。
另外,企业用户的只读账户,也可设置并接收到语音告警了。网页性能管理支持国际化「繁体中文、英文」。 有海外的业务的小伙伴们不要错过哦。
透视宝
1 、新增业务系统拓扑展现
面向业务系统的构建和问题分析,能够定义面向业务系统的架构图,整合原有离散的应用、前端、后台任务、数据库及基础设施,给用户呈现业务系统的体系架构;基于业务系统拓扑图的性能分析帮助用户通过拓扑图分析系统各个组件的性能问题。
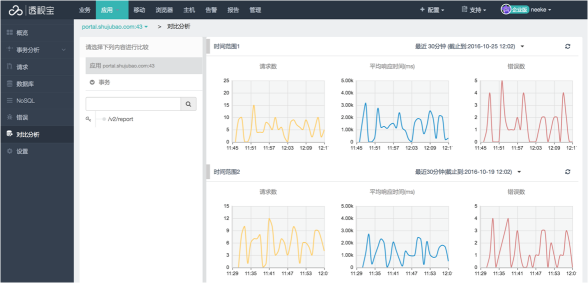
2 、应用栏目新增对比分析
应用栏目中新增对比分析:可以按应用和该应用下的事务进行不同时间维度的对比分析。统计指标为:每分钟请求数,平均响应时间,每分钟错误数,错误包含错误和异常。
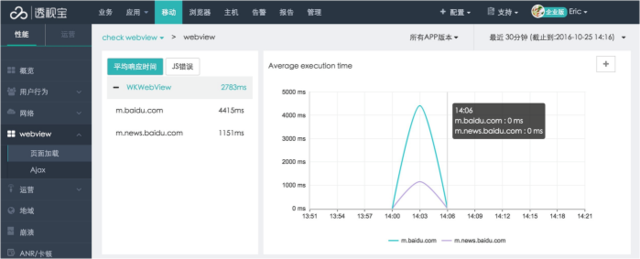
另外,透视宝 javacode 请求堆栈中添加 mongodb 的数据库信息。移动应用分析新增对 wkwebview 的性能监控,可监控 WKWebview 的时间响应分解、耗时、白屏、 ajax 请求数据、 JS 错误数据等。
压测宝
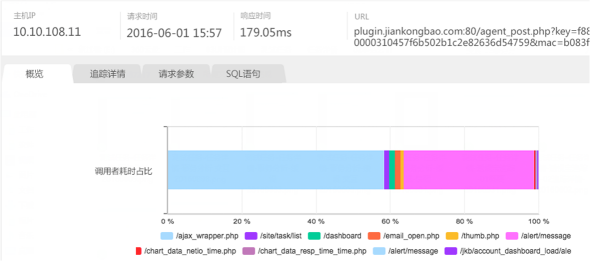
集成代码追踪,支持全平台全语言的后端追踪
压测任务数据分析中能够深度集成透视宝代码追踪,支持全平台、全语言的后端代码追踪,针对压测中的性能问题进行深度分析。例如对 [失败、缓慢] 的请求做深度分析,可详细查看该请求的堆栈耗时、 SQL 执行耗时、请求参数等。

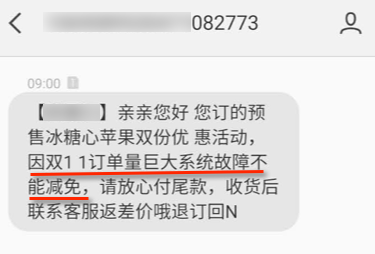
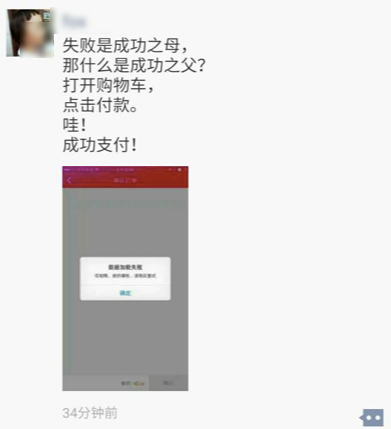
盼望着盼望着,终于可以支付了,我愉快地拿起手机打开应用支付订单,等支付确认之后,我才发现,貌似店家没有给我优惠哦!怎么两份苹果要了 79*2=158 元呢?真郁闷,这不简直是赤果果的消费欺诈不成?所以我选择退款!必须退!结果更让人崩溃,点击退款之后系统的提示是这样的!

不得不佩服这个店家的服务,一会短信就过来了,店家抱歉说是因为系统因为访问量太大出现了故障,所以可以支付完成之后找店家补差价。哦,原来是这样!本来还以为是店家欺诈呢。
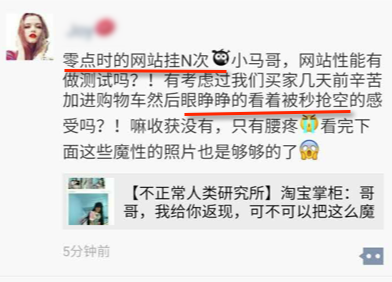
郁闷地打开朋友圈,想发发牢骚,结果看见朋友圈里中招的小伙伴相当多呢。
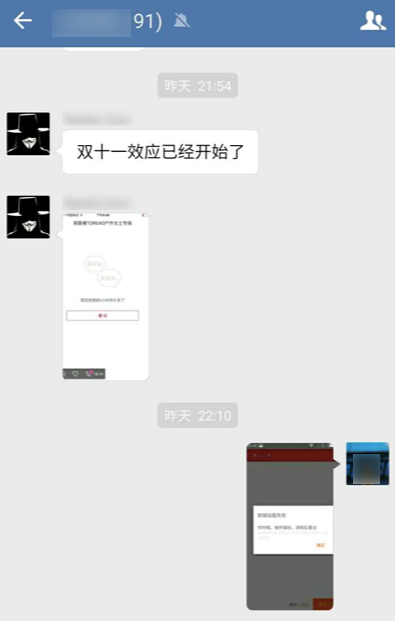
看了这些顿时精神一震,好歹我也是个高级运维工程师呀,还懂代码开发,就是传说中的 DevOps ,爬起来我开始分析:一般这种商品两件优惠大致有几种策略(可能还有,我买的比较少,没有看到): 1 )第 2 份 0 元,就是所谓的五折嘛! 2 )第 2 份 1 元,比五折那么一点点; 3 )第 2 份每斤 1 元; 那么在加入购物车选择结账的时候,系统发生了什么?我猜想是这样的:
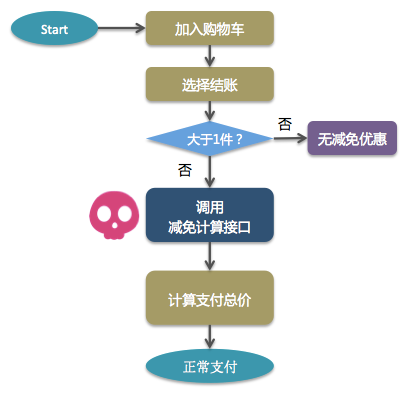
按照这个流程来讲的话,就是万恶的“减免计算接口”出现了问题!估计是对应的后端服务宕机了,或者我所在的北京地区的网络出现了问题,导致在调用这个接口的时候出现了异常,不过真心佩服电商平台技术,做了很多的异常判断,明显是当“减免计算接口”出现异常的时候,系统能够继续正常执行,当然此时就第 2 份就不会优惠了。 接口很重要!接口很重要!接口很重要! 所以在系统上线前有必要对接口进行大规模并发下的压力测试,首先要保障提供接口服务的程序不掉链子,能够抗住那么多流量,其实这样还不够,因为仅仅关注后端是不够的,现在的应用架构太复杂了,网络、 CDN 等都是影响接口正常质量的很重要的因素,所以必须能够在全链路的真实环境下对系统进行压测,这样就能判断哪些地区,哪些运营商可能导致的用户不爽。 正在这时,上海同学告诉我他在凌晨正常下单支付了!好吧,这说明上海并没有受到类似不良接口的影响。 仅仅是全链路压测够不够呢?其实还不够,因为在真实环境下,各种状况层出不穷,瞬息万变,测试做的再好也只能尽可能真实的模拟未来发生的情况,但是实际上还是会有不可预想的事情发生,所以我们还需要监控!比如我就用监控宝的 API 监控把公司应用里的那么多关键接口进行了 7X24 小时的实时监控,能够通过云智慧的全球监测点对接口调用的可用性、正确性和响应时间进行实时监测,当有问题的时候第一时间获得短信或者电话语音的告警通知,经过分析快照快速定位和解决问题——这一切只要在老板知道以前处理掉,今年的优秀员工就是我啦。 最后问一句,谁认识负责“减免计算接口”服务的运维同学?我想和他聊聊去。
]]>**监控宝**
1 、企业版“报表中心”新增“数据报表”模块
数据报表可进行不同监测点的多个指标数据对比,支持折线图、柱状图、折柱混搭视图切换,数据报表可导出。目前支持 Ping 监控监测点和省份运营商两个维度的报表。


另外,企业用户的只读账户,也可设置并接收到语音告警了。网页性能管理支持国际化「繁体中文、英文」。 有海外的业务的小伙伴们不要错过哦。

**透视宝**
1 、新增业务系统拓扑展现
面向业务系统的构建和问题分析,能够定义面向业务系统的架构图,整合原有离散的应用、前端、后台任务、数据库及基础设施,给用户呈现业务系统的体系架构;基于业务系统拓扑图的性能分析帮助用户通过拓扑图分析系统各个组件的性能问题。

2 、应用栏目新增对比分析
应用栏目中新增对比分析:可以按应用和该应用下的事务进行不同时间维度的对比分析。统计指标为:每分钟请求数,平均响应时间,每分钟错误数,错误包含错误和异常。

另外,透视宝 javacode 请求堆栈中添加 mongodb 的数据库信息。移动应用分析新增对 wkwebview 的性能监控,可监控 WKWebview 的时间响应分解、耗时、白屏、 ajax 请求数据、 JS 错误数据等。

**压测宝**
集成代码追踪,支持全平台全语言的后端追踪
压测任务数据分析中能够深度集成透视宝代码追踪,支持全平台、全语言的后端代码追踪,针对压测中的性能问题进行深度分析。例如对 [失败、缓慢] 的请求做深度分析,可详细查看该请求的堆栈耗时、 SQL 执行耗时、请求参数等。
 ]]>
]]>亚马逊 1 秒钟的访问延迟,将带来每年 16 亿美元的巨额损失;
沃尔玛、百思买等在黑色星期五当天,曾因流量暴增 7 倍不得不关闭网站服务。
大促之前 必先压测
云智慧压测宝助您决战双 11 ,立即进行压力测试,获取专属于你的压测报告
http://yacebao.com/landingPage0815.shtml?utm_source=v2ex.shuangshiyihuodong
云智慧压测宝,性能压力测试的必备工具,基于真实业务场景与用户行为的云端压力测试。可快速发起百万并发访问,实现对全链路和全业务的压力测试。保障企业在双 11 大促之前,及时验证系统稳定性并发现问题。
全球范围快速发起百万并发:
全球多达 200+城市持续并发
任意位置浏览器创建并控制测试
洞察生产环境高并发下的性能表现

压测监控大屏 掌控全局状况:
自定义数据分析面板
全自动关联分析多项指标
实时数据分析,发现性能瓶颈

深度集成 APM 工具 实时分析应用性能:
深入分析后端应用整体性能
实时定位代码级性能瓶颈
分析硬件资源利用率指标

独特的企业私有加密压测方案:
可为高安全策略的电商网站定制压测方案,灵活配置的响应机制,可根据电商 内部的加密方式,快速为其搭建出一套符合要求的压测环境,超越传统压测方式。

快速获得压测报告:
准备测试脚本,确认压测目标
设置测试时间、并发量等任务
得到测试结果,实时查看数据

决战双 11 ,立即生成专属于你的压测报告吧~
http://yacebao.com/landingPage0815.shtml?utm_source=v2ex.shuangshiyihuodong ]]>
95 后二次元新人类的追捧,让以视频弹幕、 UP 主闻名于世的 bilibili (以下简称 B 站)愈发火爆,无数年轻人通过电脑、手机、电视等终端设备在 B 站上追番、看弹幕,特别是新番上线时的访问压力是非常大的,这就给 B 站的 IT 运维团队带来了巨大压力。胡凯在去年加入 B 站刚刚成立的运维部,人少事多,遇到了很多坑。
本文根据作者在“监控与性能分享群”中的分享内容整理。
B 站运维痛点主要有 3 个:人手不足、故障多、运维系统跟不上,针对这三个痛点, B 站采用了三种方式进行破冰。

1 、解放劳动力
目前 B 站的 CDN 主要是自建的, TB 级带宽,视频存储也已达到 N 个 PB ,运维压力非常大。招人确实可以解决问题,但在上海这座魔都招聘合适的运维人员非一朝一夕能够完成的,人手不足怎么办?那就想办法把劳动力从繁杂的日常运维工作中释放出来。
由于之前没有专门的运维部门, IT 系统的权限都在开发手上,出问题了以后运维总得跟在开发后面查原因,效率低不说,沟通往往容易出现问题。
所以我们第 1 步做的就是:用 Ansible + Jenkins 搞定自动发布。 Ansible 是相对简单的批量管理工具,支持模板管理等高级功能。搞定了自动发布,开发的服务器需求已经明显下降,只要把代码提交到 Git 主干,就会自动触发发布。

Git 使用的是 GitLab ,同时为了安全我们做了一层 LDAP 代理,效果相当于“将军令”,操作机、 Git 和 Jenkins 用 OpenLDAP 做统一认证,后续用到的 Redmine 、 Grafana 、 Zabbix 等都接入了 OpenLDAP 认证,每个人都有个动态口令,每次验证都需要用到。
2 、一棒子监控告警系统
由于原始的监控不满足快速增长的业务,我们部署了开源监控系统 Zabbix ,虽然运维同事能够很好的使用 Zabbix ,但其他部门同事总觉得易用性不高、而且很多定制化监控实现起来很麻烦。

然后,我们开始折腾监控系统——“一棒子监控”,为什么这么说呢,因为要把监控细化,不是一两天的事情。而 B 站的几乎所有请求都要经过 CDN ,入口在手上,出问题想知道还难吗?于是,我们在入口处做了监控,所有 5xx 的错误都打到 ELK ,那么无论是什么业务出问题了都会及时告警,让相关人员来处理,后续再细化。
另外,要把精力投入到最重要的事情上。我们可以花很长的时间去搞好 Zabbix 、 Open-Falcon ,但结果可能是 从 80 分 到 90 分这种并不显著的效果,而很多监控并不是 Zabbix 、 Open-Falcon 擅长的,不如打个差异战。
上图中有个 StatsD 推荐给大家, StatsD 可以非常灵活的嵌入到代码里进行监控( Shell 都可以),因为使用 UDP 协议,所以服务端性能和故障不会影响到调用的程序,可以实现业务级的 QPS 、响应时间等统计类监控。
其中一个报警最终的效果如下:


B 站是自建 CDN 的,在国内有覆盖全国的好几百个 CDN 节点, CDN 的监控一直是个难点,当某 1 个链路出现问题,用传统的 Zabbix 、 Open-Falcon 监控很难发现问题。虽然我们自研了 Http-monitor 监控,可用于网站的可用性监控告警,但考虑到独立资源和数据可靠性,还有用户端网络质量的检测,还是同时使用了第三方监控宝的服务。监控宝使用简单,功能实用,监控点多,分布式监控可以及时发现网络上出现的问题,提供的快照功能可以快速定位问题和查看详细信息。而且监控宝属于第三方独立的,还能出具网站的 SLA 证书,作为 B 站内部工作考核的依据。


3 、开源系统的爱与恨

B 站技术氛围浓厚,爱开源、爱新技术,所以使用了大量的开源组件,包括 SheepDog (丢过数据)和 GlusterFS (卡成翔),其中最大的坑是 SD 卡 + Ceph 存储。 Ceph 本身的设计非常好,但是姿势不对也会死很惨。比如 B 站的某套服务器集群用 SD 卡来跑系统,结果 SD 卡跪了导致系统也跪了,所有虚拟机的磁盘 io 都卡顿甚至死机,经过不断调优终于还是稳定了。 Ceph 给我最大的安慰是:它没有丢数据,没有丢!
此外, Redis3.0 、 Codis 、 Twemproxy 等开源系统都在 B 站得到了使用,最后我们自研了 BiliTW (已开源),主要原因是 Codis 现在没更新了, Twemproxy 的性能比较差,特别是后端 Redis 多的情况下(而且它和 Redis 一样、只吃单核)。 BiliTW 最大的改进是支持多核,增加了一些易于运维的功能。
最后总结一下 B 站运维团队的成长过程:
由于人手不足,所以事情得挑着做;由于故障多,得先抓入口、抓大的;由于运维系统跟不上,得先拿开源的顶着;由于用了大量开源系统,所以踩了很多坑。

问:请问动态口令是怎么做的,自己开发还是开源 auth ?
答:用的是谷歌动态口令,开源的 Google 身份验证器。
问: Ceph 部署到线上需要什么特别的处理吗?都遇到什么问题了?
答: Ceph 要注意版本,一定要用稳定版,要用大厂用过的版本。另外 Ceph 非常耗资源, B 站全部用的 SSD , Ceph 的内部交换是独立的万兆网络。 Ceph 遇到最大的问题就是感觉 Ceph 成了分布式单点存储,都是几个节点、几个副本,大的 kvm 块存储集群有 64 节点的集群,数据 3 副本,解决起来很复杂,需要有爱研究,能看懂代码的人。
问: B 站运维团队多少人?
答:去年是从 0 开始,目前 20 多人,包含应用、研发、安全、信息等。
问: GlusterFS 这个存储用起来卡吗?
答: GlusterFS 我认为只适合做大文件的冷存储。
问:为什么不用 Docker 而用 kvm
答:我们也用 Docker , Docker 一直有关注,但实际用的人不多,能用起来的都是投了很多资源进去的大公司。在 Docker 1.9.0 开始,我们把核心 SLB 跑在 Docker 上了,用 Host 方式。今年下半年,我们的一个大目标就是 Docker 接入其它线上业务。目前使用的 Mesos Macvlan 方式已经在踩水过程中。
问: Hadoop 相关的运维需要做吗
答:大数据也做,暂无专职人员。技术研究这块由于缺少专人,我都是给每个应用运维分任务。大数据就分给了一个应用运维在搞,和开发一起学习。
问:你们服务器网卡做绑定了吗?
答:我们全部做了双网卡的绑定,万兆 bond0 。
问:故障多,这种麻烦如何快速解决?
答:这个很难,一方面需要了解业务,二方面需要有数据和手段。刚开始我们查问题非常慢,后来逐步改进,比如完善监控,加故障锚点,故障总结。最近在做 Drapper 链接追踪,好多公司也都有做,实际上就是在请求的链接各个环节加标记,然后选择性做实时分析。 Drapper 最终实现的效果就像浏览器的审查元素一样,哪里慢一下就看到了。
问: mode0 模式的话总带宽还是一个网卡的吧?我在测试 mode=4 ,结合交换机的动态聚合,遇到的问题是服务器相互传输的话,带宽是一个网卡的速度。
答: Mode 0 最好在交换机上做下配置,带宽是跑 2 张网卡的,既能冗余,也能上量。我们自建 CDN 带宽很高,单台机器带宽就按 20G 准备。在猎豹用的是 Mode4 ,也挺好的, Mode6 不需要特殊配置,但有一个方向不均衡。之前测试 Mode4 效果最好,但公司最后用了 Mode6 ,因为易维护。
关于带宽的问题,必须 2 个客户端向一个服务端同时传输才能达到双网卡带宽,以前测试 mode0 的时候遇到过跑不满的现象,后来就用了 mode6 。不过是好多年前的事情了,当时应该是 CentOS5 或 6 ,现在 B 站用的是 Debian 8 , Mode 0 并没有发现问题。
问:你们的 Redis 集群 3.0 稳定吗?
答: Redis 3.0 挺稳定的,它的 Java 客户端会好些,其它语言可能得自己开发。这边语言很多,有些业务还是用 Proxy 的方式在跑。我们正在开发一个 Cache 管理系统,最终会兼容各种方式,未来会开源。
问: BiliTW 是 https://github.com/anewhuahua/bilitw 吗?
答:不是,这个是前同事做的,是基于 Twemproxy 改的多进程版本。未来会重构一个新的,放在 https://github.com/bilibili 下面。
问: B 站的云用的多吗?
答:内部相当于是私有云了,游戏业务用公有云多些。
欢迎大家投搞: lily.qi@cloudwise.com ]]>
2 、促销季到了,应用性能如何?到底能不能支持 500w 并发用户?
3 、怎么做压测才能更接近线上真实环境?
系统负载有多强,压测一下就知道。云智慧压测宝 3 步 6 分钟 开启真实用户的性能压测
8 月 16 至 9 月 2 日申请试用压测宝,感受真实压测的洪荒之力,还有机会获得优酷视频会员卡,速速来领~

参与活动赢优酷会员卡
1 、从这里申请试用压测宝: http://yacebao.com/landingPage0815.shtml?utm_source=v2ex&utm_medium=huodong&utm_campaign=v2ex.huodong.ycbshiyong
(请一定要在这个页面的表单中申请哦~)
2 、小编将在 8 月 16 日至 9 月 2 日,从申请试用压测宝的成员里随机抽取 50 名用户,赠送优酷视频 1 个月 vip 会员卡
3 、 9 月 3 日将获奖名单公布于本帖。
压测宝可以做什么
压测宝基于真实业务场景与用户行为,通过全球分布式网络发起真实压力,全面了解业务负载能力,让压测变得简单

压测宝全链路压测原理图
1 、 3 步 6 分钟,快速实现压力测试
2 、基于云的弹性伸缩架构,通过全球分布式压测点发起真实压力测试。零硬件 ,零部署,低成本。

3 、基于压测,实时分析应用性能,定位性能瓶颈
4 、大屏展示实时数据,掌握全局状况,全面了解系统能力

申请压力测试:
http://yacebao.com/landingPage0815.shtml?utm_source=v2ex&utm_medium=huodong&utm_campaign=v2ex.huodong.ycbshiyong ]]>
应用压力测试面临巨大挑战
在互联网+时代,云计算、移动互联网、物联网的蓬勃发展让虚拟化、分布式计算&存储、 SDN 、 API 等技术得到广泛普及,应用模式变得透明和庞大,部署在不同环境、调用大量第三方服务的应用性能难以通过传统压力测试工具准确测量。同时企业高速增长的互联网业务要求产品开发、迭代和交付周期越来越短,作为后端支撑的压力测试方法和工具越来越难以满足应用功能可用和容量规划预估的需求:
• 风险缺乏有效的评估手段,不确定并发负载的极限;
• 信息系统复杂度上升,性能测试成本与实施代价高;
• 业务测试环境和实际用户网络环境差距大,性能问题定位困难;
• 容量规划缺少依据,只能依赖测试者的个人经验。
云智慧压测宝准确感知性能瓶颈
压测宝是云智慧基于真实业务场景与用户行为推出的云端压力测试产品,颠覆传统压测理念和流程,遵循新一代应用性能测试领域的云压测标准体系,专为云端互联网企业的开发测试节奏与复杂度而生,只需三个步骤即可发起高达亿级 PV 的用户访问量,实现对全链路性能测试和真实业务场景压力测试。

端到端全链路压测
• 真实业务场景压力测试是以真实的用户行为、时间和规模进行建模,精准测试生产环境在压力下的性能表现,详悉各地域或链路之间性能差异,支持高达亿级 PV 用户的访问量;
• 全链路性能测试可根据业务链路的实际环节,通过网络浏览器在任意位置创建并控制测试,从世界各地的一个或多个云环境生成负载,经由标准协议指向应用程序,全球实时发起压力。
压测宝通过云端服务器产生真实分布式用户访问压力,模拟来自各地域用户接入后台所带来的真实流量,从而跳出了“温室环境”的理想状态,达到无限接近生产环境所面临的各种复杂因素,准确测试真实用户体验。

压测宝综合报表
由于采用基于 SaaS 模式的分布式部署方式,用户无需任何的硬件及带宽等资源的投入,从而大大缩短测试周期及降低测试成本。压测宝的操作流程非常简单,只需要“准备测试脚本”、“定义测试任务”、“实时分析数据”这三个步骤,即可实现传统测试方法长达 6 周的测试过程,周期缩短到 6 个小时甚至 6 分钟。

可视化压测大屏
压测过程中,压测宝提供多维度数据指标,能够自由灵活地进行多指标关联分析,而与云智慧应用性能管理产品透视宝的深度集成,帮助用户通过压测深入分析全链路性能状况,快速进行后端问题快照及代码详情跟踪,定位代码级性能瓶颈,同时通过可视化数据大屏实时展示和分析性能数据,实现现场纠错。
压测宝提供丰富的扩展接口,能够与企业现有测试工具 Jenkins 等紧密集成,将压测任务以服务的方式进行驱动执行,实现面向产品全生命周期的持续交付和持续集成。此外,云智慧组建的性能测试领域专家团队,依托压测与性能管理平台为用户提供专业的咨询服务,并出具公立的第三方压测报告,确保应用的上线质量。
 ]]>
]]>而与此同时,互联网金融市场和用户规模在稳步增长, CNNIC 发布第 38 次《中国互联网络发展状况统计报告》数据显示,截至 2016 年 6 月,我国购买互联网理财产品的网民规模达到 1.01 亿,较 2015 年底增加用户 1113 万人,网民使用率为 14.3%,较 2015 年底增加 1.3 个百分点。互联网理财市场历经几年的快速发展,理财产品日益增多,用户体验持续提升,网民在线上理财的习惯初步养成,搜易贷等多家平台成交量突破百亿元,大平台的厮杀拉开帷幕,布局消费金融或转型为金融科技公司的消息不绝于耳。
对于广大投资者来说,网贷风控管理与资金存管等政策的出台和落地虽然为资金安全提供了有效保障,但毕竟是普通人很难清晰了解的。所以作为互金平台入口的网站和移动 APP 的稳定性和高可用,成为互联网金融机构服务可靠性的重要考量标准。试想一下,当投资者访问互金平台网站时,出现长达数十分钟甚至数小时无法打开、无法登录或数据报错等故障,会给公司业务和品牌造成多大的负面影响。尤其很多互金平台的投资者之间都是互相熟识的,而互联网的口碑传播速度和影响力远超过去,一次小小的疏漏很可能给互联网金融企业带来非常严重的损失。

数据来源:网贷之家 [详见: http://www.wdzj.com/pingji.html ]
云智慧作为业内最专业的业务性能监控、管理和测试服务提供商,根据网贷之家研究院发布的 2016 年 6 月网贷平台发展指数评级,遴选了 30 余家排名靠前的网贷平台,利用遍布全国的分布式监测网络,对各平台网站的网站可用率和平均响应时间等指标进行了为期一周的 7x24 连续监控,得到如下数据。

从数据中我们可以看出,差不多 90%的网贷平台的网站可用率都达到了 100%,首页的各地平均打开时间在 1000ms 以内,也就是说各地投资者在任何时间访问这些网贷平台都能顺利而快速的打开网站页面。网贷平台排名三甲的陆金所、宜人贷、点融网的网站可用率均为 100%,同时响应时间在 500ms 以内,用户体验的优秀程度与其行业排名相匹配。排名第四的人人贷网站的平均响应时间超过 1000ms ,主要是陕西地区监测点的访问速度在超过 2000ms ,对整体数据表现造成影响,该地访问速度在今天已经得到优化。


本次监控期间数据表现不佳的惠人贷,其网站可用率仅为 94.15%,首页平均打开时间为 1316.85 ms ,通过查看详细监控数据发现,在 7 月 28 日凌晨 3 点~9 点和上午 10 点~下午 1 点期间共 9 个小时,惠人贷的网站无法访问,可能是系统升级等原因造成的,这时候只要提前做好客户告知和安抚工作,就不会对业务有太大影响,而网站访问慢主要是辽宁、上海、湖北、陕西等地的响应时间过长造成的,建议惠人贷对上述地区进行 CDN 优化。当然,有些网贷机构如果是为特定地区投资者服务的,那么只要做好目标地区的网站优化工作即可。
云智慧作为国内领先的业务运维服务提供商,为互联网金融企业提供基于用户行为的端到端全栈性能问题定位、基于全球分布式网络的用户体验主动感知、基于云端压力测试平台的业务容量规划,能够帮助企业建立以用户体验为核心,以业务价值为导向的业务运维大数据分析平台。通过对企业业务系统、支撑系统和管理系统的业务流程的梳理,把业务数据和反映前端用户体验的 IT 性能数据利用大数据技术进行采集、整理和关联分析,实时映射到全局业务拓扑图上,借助数据可视化工具呈现出来,从而帮助管理者在纷繁复杂的业务数据和 IT 性能数据中找到业务规划和企业发展的方向,实现应用性能的持续提升和业务的高速增长。
]]>移动应用压力测试如何模拟那么大的并发量?
如果您有以上疑问,
那就来一场说聊就聊的压测分享吧~
云智慧压测宝诚邀您参与线上交流“实战解析|如何发起真实用户行为的压力测试 ”。
基于真实业务场景与用户行为,通过全球分布式网络发起真实压力,全面了解业务负载能力,让压测变得简单~
时间
8 月 16 日、 17 日 晚 8:00
讲师一:
陆兴海( Yak )

西北工业大学信息化技术专业硕士。多年软件产品开发、设计经验,致力于面向大数据的 IT 系统监控软件以及应用性能管理( APM )平台的设计与开发。关注互联网、云计算、大数据,并专注于产品设计。
讲师二:
刘建坡( Jeff )

吉林大学计算机科学与技术专业,多年软件设计,开发,实施经验。一直基于 java 架构和开发,目前致力于云压测,大数据产品的架构和开发。
讨论话题
1.真实用户的压测实践
2.如何基于压测做应用性能分析
3.基于真实用户的压测是如何实现的
4.压测宝基础架构分享
*主持人说,现场还有小礼品哦!
报名地址: http://www.yacebao.com/landingPage.shtml?utm_source=v2ex&utm_medium=huodong&utm_campaign=v2ex.ycb.huodong ]]>
欢迎大家投稿: lily.qi@cloudwise.com
联系 QQ : 614117760
跨境电商经历 2014~2015 年的爆发式增长已经进入成熟发展阶段,据统计, 2015 年年底我国海淘市场规模达到 2400 亿元,同比增长 60%,海淘人数达到 2400 万人,预计在 2018 年,市场规模将达万亿级别。早期政策和人口红利带来的诸多利好因素逐渐成为过去,随着各大综合型电商纷纷布局海淘市场,以及大量个性化、差异化海淘网站的上线,如今的跨境电商已经成为竞争激烈的红海市场,电商企业要在激烈的竞争中确保业务稳定增长,必须对作为业务支撑的网站和 APP 性能进行准确的监控,选择合适的关键业务监控指标尤为重要。
跨境电商企业从资本积累到高速发展,再到业务扩张,网站(系统)对于 IT 技术架构的要求会根据业务变化不停地变化。在整个过程中,监控的内容和指标类型是基本不变的,变的只是数字。众所周知,对外网站的访问量是衡量网站的重要指标之一,它在系统后面的反映就是压力,是处理各个级别访问量的能力。一般细分出来有: 1. 磁盘 I/O ; 2. 内存使用量; 3. 内外网络的带宽; 4. CPU 使用率; 5. 数据库的 Select QPS 等。
根据我们的经验,当系统架构由三台或以上的独立服务器协助完成的时候,需要在内部对每台服务器以上几个指标进行监控,这样才能让我们及时发现瓶颈,优化性能时才会更有重点和高效。如何使用这些监控指标呢?
结合我们跨境电商企业的网站特点,网站一开始对数据库的依赖大的特征做一个简单分析:数据库(MySQL) 在从一个库到多个库的发展过程中,时常会变成整个系统最大的瓶颈,每当网站访问量提高 10%, MySQL 的 CPU 使用波动和输出网络带宽就会出现很大的增长,如果后台系统同时对数据库进行读写操作时,更容易导致前台网页出现 500 错误。在架构壮大之前,导致的原因往往是 MySQL 出现大量(查询时间长)的 Select 操作后,引起数据库进行表级别的 Lock(MyISAM 引擎的特征)所导致的。
这又引出一个疑问了,在这么多的系统和代码中,怎么样发现这类问题,并进行优化呢?通过对监控数据长时间的观察, CPU 的波动一般都是正常的,它成为瓶颈的机率很少,除非程序出现死循环。现代的磁盘性能已经很高了, I/O 性能在使用 HA 架构后,会根据 I/O 指标来决定增加磁盘(无缝完成),所以 I/O 也不会是瓶颈。如果项目管理到位,内存使用是严格控制的,需要大量内存消耗的功能,必须要向架构师申请,不允许私自写大数据到内存。最后,内外网络的带宽的变化是最大的,最容易反应各个系统运行情况的一个指标,当有一定历史监控数据之后,更容易发现整个系统架构的性能瓶颈。
例如某次,通过云智慧监控宝发现网页的响应时间比平常多出 5 倍,工程师迅速对数据库和各个独立系统的监控数据进行分析,发现如下情况:

图一

图二
经过两张图的对比,发现一台服务器的进来的网络流量(图一, Incoming network traffic)变化正是另外一台服务器出去的网络流量(图二, Outgoing network traffic)变化一致,范围缩小,我们的内部监控是针对每个功能节点的,而刚好这个 Outgoing network traffic 正是数据库出去的流量,可以肯定另外一台服务器(图一)提取了不应该的数据了(在访问量不变的情况下,对比了历史监控数据,没有发现以前有这么多数据流动)。范围进一步缩小,很快定位问题在这个功能点,接下来就是针对性地进行程序或系统的优化了。这是监控宝通过监控响应时间的变化,从而发现问题的实例。
监控宝对跨境电商还有另外一个重要作用,就是准确感知海外服务器的网络状况,通过监控宝部署在不同国家的监控点对网站运行状态进行观察,很容易区分是外部网络故障还是内部系统故障。

图三
如上图,我们的网站服务器是星状部署模型, 有一个中心数据(系统)源,而监控宝在各国国家都有落地的监控点,所以我们利用这个特性,在监控宝创建了一个直接指向我们中央服务器的监控项目,让它收集从不同的地方的到我们中央服务器的监控数据,汇总到如下图:

图四
这里每一条线代表中央服务器对不同国家的响应时间,蓝色箭头这里(5 月 15 日),加拿大响应时间超过 2000ms ,而其它国家回来的数据是正常(1000ms 左右)。这说明加拿大到我们的中央服务器链路有问题。红色箭头( 7 月 3 日) 情况看到是所有国家的响应时间都很高(接近 3000ms ),说明我们的数据源服务器内部出现问题了,我们的工程师翻查内部系统日志,也印证了这一个结论。
以上是根据我们的架构特性积累的经验,并不一定适合每家跨境电商,正如本文开头提到的,每家公司的发展阶段不同,可投入的 IT 资源不同,遇到的问题和解决方案当然也有差异。这就要求 IT 部门熟悉掌握技术架构的同时,对企业的具体业务模式有深入的了解,通过细致的数据观察和分析,才能找到业务增长的主要监控指标和辅助指标,让网站技术和公司业务一起稳步增长。
]]>什么是大数据
什么是大数据,多大算大, 100G 算大么?如果是用来存储 1080P 的高清电影,也就是几部影片的容量。但是如果 100G 都是文本数据,比如云智慧透视宝后端 kafka 里的数据,抽取一条 mobileTopic 的数据如下: [ 107 , 5505323054626937 ,局域网,局域网, unknown , 0 , 0 , 09f26f4fd5c9d757b9a3095607f8e1a27fe421c9 , 1468900733003 ] ,这种数据 100G 能有多少条,我们可想而知。

数据之所以为大,不但是因为数据量的巨大,同时各种渠道产生的数据既有 IT 系统生成的标准数据,还有大量多媒体类的非标准数据,数据类型多种多样,而且大量无用数据充斥其间,给数据的真实性带来很大影响,此外很多数据必须实时处理才最有价值。
一般数据量大(多)或者业务复杂的时候,常规技术无法及时、高效处理如此大量的数据,这时候可以使用 Hadoop ,它是由 Apache 基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,编写和运行分布式应用充分利用集群处理大规模数据。 Hadoop 可以构建在廉价的机器上,比如我们淘汰的 PC Server 或者租用的云主机都可以拿来用。
今天,云智慧的李林同学就为大家介绍一下 Hadoop 生态圈一些常用的组件。
Gartner 的一项研究表明, 2015 年, 65%的分析应用程序和先进分析工具都将基于 Hadoop 平台,作为主流大数据处理技术, Hadoop 具有以下特性:
方便: Hadoop 运行在由一般商用机器构成的大型集群上,或者云计算服务上
健壮: Hadoop 致力于在一般商用硬件上运行,其架构假设硬件会频繁失效, Hadoop 可以从容地处理大多数此类故障。
可扩展: Hadoop 通过增加集群节点,可以线性地扩展以处理更大的数据集。
目前应用 Hadoop 最多的领域有:
1) 搜索引擎, Doug Cutting 设计 Hadoop 的初衷,就是为了针对大规模的网页快速建立索引。
2) 大数据存储,利用 Hadoop 的分布式存储能力,例如数据备份、数据仓库等。
3) 大数据处理,利用 Hadoop 的分布式处理能力,例如数据挖掘、数据分析等。
Hadoop 生态系统与基础组件
Hadoop2.0 的时候引入了 HA(高可用)与 YARN(资源调度),这是与 1.0 的最大差别。 Hadoop 主要由 3 部分组成: Mapreduce 编程模型, HDFS 分布式文件存储,与 YARN 。

上图是 Hadoop 的生态系统,最下面一层是作为数据存储的 HDFS ,其他组件都是在 HDFS 的基础上组合或者使用的。 HDFS 具有高容错性、适合批处理、适合大数据处理、可构建在廉价机器上等优点,缺点是低延迟数据访问、小文件存取、并发写入、文件随机修改。
Hadoop MapReduce 是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上 TB 级别的海量数据集。这个定义里面有几个关键词:软件框架、并行处理、可靠且容错、大规模集群、海量数据集就是 MapReduce 的特色。

MapReduce 经典代码(wordCount)
上面这段代码就是接收一堆文本数据,统计这些文本数据中每个单词出现的次数。 MapReduce 也是一个计算模型,当数据量很大时,比如 10 个 G ,它可以把这 10G 的数据分成 10 块,分发到 10 个节点去执行,然后再汇总,这就是并行计算,计算速度比你一台机器计算要快的多。
HBase
Hadoop 的主要组件介绍完毕,现在看下 HBase ,它是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用 Hbase 技术可在廉价 PC Server 上搭建大规模结构化存储集群。 HBase 是 Google Bigtable 的开源实现,与 Google Bigtable 利用 GFS 作为其文件存储系统类似, HBase 利用 Hadoop HDFS 作为其文件存储系统; Google 运行 MapReduce 来处理 Bigtable 中的海量数据, HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据; Google Bigtable 利用 Chubby 作为协同服务, HBase 利用 Zookeeper 作为对应。
有人问 HBase 和 HDFS 是啥关系, HBase 是利用 HDFS 的存储的,就像 MySQL 和磁盘, MySQL 是应用,磁盘是具体存储介质。 HDFS 因为自身的特性,不适合随机查找,对更新操作不太友好,比如百度网盘就是拿 HDFS 构建的,它支持上传和删除,但不会让用户直接在网盘上修改某个文件的内容。
HBase 的表有以下特点:
1 ) 大:一个表可以有上亿行,上百万列。
2 ) 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3 ) 稀疏:对于为空( NULL )的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase 提供的访问方式有命令行 shell 方式, java API(最高效和常用的), Thrift Gateway 支持 C++, PHP , Python 等多种语言。
HBase 的使用场景:
需对数据进行随机读操作或者随机写操作;
大数据上高并发操作,比如每秒对 PB 级数据进行上千次操作;
读写访问均是非常简单的操作,比如历史记录,历史订单查询,三大运营商的流量通话清单的查询。

HBase 在淘宝的应用场景
Hive
之前我们说了 MapReduce 计算模型,但是只有懂 Java 的才能撸代码干这个事,不懂 Java 的想用 Hadoop 的计算模型是不是就没法搞了呢?比如 HDFS 里的海量数据,数据分析师想弄点数据出来,咋办?所以就要用到 Hive ,它提供了 SQL 式的访问方式供人使用。
Hive 是由 Facebook 开源, 最初用于解决海量结构化的日志数据统计问题的 ETL(Extraction-Transformation-Loading) 工具, Hive 是构建在 Hadoop 上的数据仓库平台,设计目标是可以用传统 SQL 操作 Hadoop 上的数据,让熟悉 SQL 编程的人员也能拥抱 Hadoop (注意。是数据仓库。不是数据库啊。)
使用 HQL 作为查询接口
使用 HDFS 作为底层存储
使用 MapReduce 作为执行层
所以说 Hive 就是基于 Hadoop 的一个数据仓库工具,是为简化 MapReduce 编程而生的,非常适合数据仓库的统计分析,通过解析 SQL 转化成 MapReduce ,组成一个 DAG(有向无环图)来执行。
Flume
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、 聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时, Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前 Flume 有两个版本 Flume 0.9X 版本的统称 Flume-og , Flume1.X 版本的统称 Flume-ng ,由于 Flume-ng 经过重大重构,与 Flume-og 有很大不同,使用时请注意区分。

Flume 就是一个数据管道,支持很多源(source), sink(目标),和透视宝的 suro 很像,比如拉取 nginx 日志可以拿这个工具简单一配就可用。当然每台 nginx 服务器上都要配置并启动一个 flume.
下面给大家看看配置文件(把 kafka 的数据写入 hdfs 的配置),配置很简单.完全免去了自己写一个 kafka 的 consumer 再调用 hdfs 的 API 写数据的工作量.

YARN
YARN 是 Hadoop 2.0 中的资源管理系统,它的基本设计思想是将 MRv1 中的 JobTracker 拆分成了两个独立的服务:一个全局的资源调度器 ResourceManager 和每个应用程序特有的应用程序管理器 ApplicationMaster ,该调度器是一个 "纯调度器",不再参与任何与具体应用程序逻辑相关的工作,而仅根据各个应用程序的资源需求进行分配,资源分配的单位用一个资源抽象概念 "Container" 来表示, Container 封装了内存和 CPU 。此外,调度器是一个可插拔的组件,用户可根据自己的需求设计新的调度器, YARN 自身提供了 Fair Scheduler 和 Capacity Scheduler 。
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序的提交、与调度器协商资源以启动 ApplicationMaster 、监控 ApplicationMaster 运行状态并在失败时重新启动等。
Ambari
Ambari 是一个集群的安装和管理工具,云智慧之前用的是 Apache 的 Hadoop ,运维同学用源码包安装,一个个配置文件去改,再分发到各个节点,中间哪一步搞错了,整个集群就启动不起来。所以有几个厂商提供 Hadoop 的这种安装和管理平台,主要是 CDH 和 HDP ,国内的很多人都用 CDH 的,它是 Cloudera 公司的,如果用它的管理界面安装,集群节点超过一定数量就要收费了。
Ambari 是 Apache 的顶级开源项目,可以免费使用,现在用的人也很多。 Ambari 使用 Ganglia 收集度量指标,用 Nagios 支持系统报警,当需要引起管理员的关注时(比如,节点停机或磁盘剩余空间不足等问题),系统将向其发送邮件。
ZooKeeper
随着计算节点的增多,集群成员需要彼此同步并了解去哪里访问服务和如何配置, ZooKeeper 正是为此而生的。 ZooKeeper 顾名思义就是动物园管理员,它是用来管大象(Hadoop) 、蜜蜂(Hive) 和 小猪(Pig) 的管理员, Apache Hbase 和 Apache Solr 以及 LinkedIn sensei 等项目中都采用到了 Zookeeper 。 ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,以 Fast Paxos 算法为基础实现同步服务,配置维护和命名服务等分布式应用。
其他组件
以上介绍的都是 Hadoop 用来计算和查询的比较常用和主流的组件,上面那副生态图中的其他几个组件简单了解一下就好:
Pig 是一种编程语言,它简化了 Hadoop 常见的工作任务, Pig 为大型数据集处理提供了更高层次的抽象,与 MapReduce 相比, Pig 提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。
Mahout 是 Hadoop 提供做机器学习用的,支持的算法也比较少,但是一些常用的 k-means 聚类、分类还是有的,他是用 MapReduce 做的,但是 MapReduce 不太擅长这个东西,所以 Mahout 的作者也转投 spark ML 阵营了。
Sqoop 是数据库 ETL 工具,用于将关系型数据库的数据导入到 Hadoop 及其相关的系统中,如 Hive 和 HBase 。 Sqoop 的核心设计思想是利用 MapReduce 加快数据传输速度,也就是说 Sqoop 的导入和导出功能是通过 MapReduce 作业实现的,所以它是一种批处理方式进行数据传输,难以实现实时数据的导入和导出。比如云智慧监控宝以前的业务数据都存在 MySQL ,随着数据量越来越大,要把数据导到 Hbase ,就可以拿 Sqoop 直接操作。
本文所介绍的东西都是用于离线计算的,而之前发布的《面临大数据挑战 透视宝如何使用 Druid 实现数据聚合》则是关于实时计算的框架 Druid 的。大数据常用的流计算框架主要有 Storm , Spark Streaming , Flink , Flink 虽然是 2014 年加入 Hadoop 的,但至今在生产环境上用的人还不多,似乎大家都持观望态度。
说一下流计算(Druid , Spark Streaming)和批处理(MapReduce , Hive)有啥区别,比如电商网站的个性化广告投放,当我们访问了亚马逊搜索笔记本电脑之后,他就会给你推荐很多笔记本电脑链接,你的请求和兴趣爱好被亚马逊服务器实时接收,流计算分析之后当时就会推荐给你可能会购买的东西。如果这个东西拿批处理去做,服务端收集完了,过半个小时才算出你可能要买电脑,这时候再给你推荐电脑明显就不合适了,因为这时候你可能在搜索电炒锅……

最后再说一下大数据的工作流,比如有两个 MapReduce 的任务是有依赖的,必须第一个完成了才能执行第二个,这就需要一个调度工具来调度。 MapReduce 也提供调度的 API ,但是代码要写很多,上面的代码截图只是一部分,这个依赖我写了大概 150 行。所以这时候出现了工作流,用工作流来管理我们的各个 job ,我目前知道的有 oozie 和 azkaban , oozie 的配置比较灵活,推荐大家使用。
]]>JSON 的应用场景和缺陷
为什么要用 Jsonnet 取代 JSON 呢,就要从 JSON 的功能说起了。 JSON (Javascript Object Notation)是一种轻量级的数据交换格式,是基于 ECMAScript 的一个子集,采用完全独立于语言的文本格式,同时也使用了类似于 C 语言家族的习惯(包括 C 、 C++、 C#、 Java 、 Javascript 、 Perl 、 Python 等),由于 JSON 在各语言间支持友好、可读性强、数据性能上相比 xml 有很大优势,所以使 JSON 成为理想的数据交换语言。
JSON 的使用场景主要有三类:
Web 工程师最为熟悉的服务端和 Javascript 的数据交换,常见 ajax ;
各语言之间的数据交换,通常以 Webservice 的形式出现,常见的范式如 jsonrpc, 和 restful ;
应用的配置文件,很多应用采用 json 作为配置文件,比如前端 bower.-> bower.json. node.js 的包管理器 package.json , PHP 的包管理器 composer.json 。
但是在用 JSON 做数据交换和配置文件时, 也会遇到很多问题:
不能加注释;
对象或数组最后一项后面不能有逗号;
不支持变量、函数;
不能用算术和逻辑运算;
不能划分,不能复用,各个 json 文件之间彼此孤立;
语法有些时候不太友好;
key 必须要加双引号;
value 是字符串时,不能用单引号。
JSONNET 的优势和应用
JSONNET 的一些特性间接弥补了 JSON 的先天不足:
key 的双引号不是必须的;
对象和数组最后一个属性后面可以有逗号;
支持单行或多行注释;

引用
self: 当前对象
$:根对象

操作数据,支持常用的算术与逻辑运算符
+: 数组(拼接)、字符串(连结)、对象(溶化)

数组和对象深入

模块化
项目配置文件过大或数据文件过大,需要拆分,通过 import 引入

函数与变量

面向对象--继承
{supper2} + {supper1} + {self}

通过上面特性,我们可以发现 JSONNET 使 JSON 拥有了语言的特性:
优点
有注释,和后端开发协商接口很方便,模拟数据的文件可以直接作为接口文档
制造模拟数据更加高效自然
数据文件的可以切分和复用
缺点
Web 场景下不能作为直接的数据交换格式
学术型代码, 比较小众
使用场景不多
标准库不够完善,存留的 issue 较多
比如排序问题
不支持 IO 操作,不具备替代脚本语言的可能性
使 JSON 变得更为复杂
JSONNET 提供内置的标准库(官网地址: http://jsonnet.org/docs/stdlib.html ),包括了一系列对象,字符串, BASE64 的标准库,大家有兴趣可以自行下载。
目前 JSONNET 的主要应用场景还是用来组织和生成 JSON 数据:
有生成大批量 JSON 文件的需求
作为 JSON 的模板引擎
接口测试中模拟数据接口,通过 JSONNET 文件生成动态的 JSON 数据
JSONNET 在透视宝的应用场景
最后介绍一下 JSONNET 在透视宝中的应用场景,透视宝在做数据呈现时主要依赖于后端的 ElasticSearch 构建的检索服务, ElasticSearch 对外提供一组 Webservice 作为数据 API 接口,数据交换格式是 JSON 。
ElasticSearch 官方的 QUERY DSL 代码,相比透视宝实际需求的查询语法并不复杂,但是我们前端在构建这个请求时却不太方便,往往要通过拼接数组的方式将 JSON 序列化来构建这个 QUERY 。针对这种情况可以将语法抽象,用 oo 去构建这样的语法,借助 elastica ( elastic search 的一个客户端)实现。但是在代码调试中发现,为了构建一个 json 的查询,我们的程序员在这上面浪费了大量时间,因为要进行大量的语法对照翻译,既不直观,也影响效率。最后我们借助 JSONNET 生成 JSON 文件,将每个查询制作为模板固化下来,复用性大大增加,这种方法在实际工作中效率很高,更加直观:
JSON 模板引擎
透视宝前端 es query 查询
模拟数据接口,通过 JSONET 动态生成 JSON 数据
大数据场景
数据自行解释
数据压缩
注: PHP 的 JSONNET 实现是由云智慧的 Neeke 完成: http://pecl.php.net/package/jsonnet ,
大家可以参考源码学习一下。
 ]]>
]]>因此,应用开发者和企业的 IT 运维部门不应该仅仅关注服务器、存储、网络的 IT 基础设施的运行状况,而应该花更多时间去了解终端用户的应用使用体验,并让相关业务部门及时获得相应信息,建立正确的工作流程,从而保证应用服务的高可用。下面给出 10 个应用性能监控小技巧,教你如何提升你的应用体验。

技巧 1: 确定哪些应用需要优先监控
云计算和移动办公在提升企业效率的同时,也导致企业无法对员工设备进行有效监管,应用出现无序状态。再加上各种历史遗留应用、虚拟机应用、客户关系管理系统( CRM )、人力资源系统( EHR )、定制的应用、会计软件、开发票软件、人力资源软件、邮件和协同工具等等,你的员工、合作伙伴和客户所依赖的(而且你支持的)应用越来越多。
应用就像业务的引擎,要一直保持良好、顺畅运行,那么第一步就先找出那些对业务和用户至关重要应用(例如迁移到云端的 CRM 、 ERP 、 HER 等),并进行全方位监控。
技巧 2: 确定哪些重要事务需要监控
从用户需求出发,找出重度用户(例如使用软件最频繁的人、产生最多收入的人、高层管理人员等等)的常用功能。或者从商业伙伴、管理人员和股东的角度,来确定哪些应用功能比较重要。
如果是刚刚启用的一个应用,应该有现成工作流程图,为用户记录重要的事务路径和工作流程,然后不断优化流程,将常用功能的操作步骤减到最少,这是我们第二项监控的目的。
技巧 3: 主动从终端用户的视角去监控应用
移动互联网越普及,终端用户就越没有耐心,所以我们要从用户的视角出发,连续监控每一个重要事务(或工作流程),测量每个步骤的响应时间,保证达到用户服务水平协议( SLA )的要求。
据 Forrester Research 统计, 35%的用户投诉都是因为应用缓慢,我们要改变这一现状,就必须先于用户感知应用体验,利用主动监控及时发现问题,找出解决性能瓶颈、错误的方法。

技巧 4: 谨慎对待监控频率和告警策略
理论上说,重要事务的监控频率越高(例如,商品价格的展示比销售渠道的显示更重要;在线支付环节比产品评论加载更重要),越能够及早察觉性能下降的趋势,然而频繁的告警很可能就像“狼来了”的故事里那样,反而导致真有问题发生时却被忽视。
因此,对于重要事务的监控频率和告警阈值设置必须更加慎重,最好能根据场景和人员级别进行分级告警,常规的访问缓慢用邮件通知普通运维,内存、磁盘空间不足的信息要及时告知 IT 主管,而在促销活动中发生性能急剧下降的情况,不但 IT 部门要第一时间获得告警,还要及时通知业务运营部门,以提前准备应对措施。
此外,监控不是一成不变的,在系统维护期间或者某个运维人员休假期间,一定记得修改告警策略,这样才能随时掌握监控状态。
技巧 5: 针对不同区域的响应时间差异制订告警策略
随着企业规模越来越大,分支机构也会越来越多,尤其是海外办事处的建立已经成为中国企业全球化发展的必然。然而比起总部和国内的员工,那些在海外办事处工作的员工在操作应用的时候,必然会发现应用响应缓慢慢,甚至由于网络问题无法连接应用。
所以 IT 部门要针对这些分支机构进行有效的应用监控(例如在波士顿、纽约、巴黎、孟买等地设置监控点),根据地区差异制订不同于国内的响应时间告警策略,在影响员工正常工作之前发现问题,并解决问题。
技巧 6: 定制化分析报告
不同部门和工作职责对 IT 业务系统状态的报告需求不同,所以需要花时间根据不同角色定制差异化报告是非常值得的,为每个用户群组(例如每个应用、每个事务处理、每个功能等)提供含有定制信息的分析报告,并定期(例如每天、每周或每月)发送报告,保证每个人(特别是老板)都能准确了解相关信息。
技巧 7: 集中式告警平台和工作流程
从传统应用到服务端应用、 Web 应用、自定义的本地应用,再到越来越多的云端应用,很多大企业都有一个超级复杂的应用集(包含 250-500 个应用)需要维护,如果每个应用都购买、配置和维护几套监控产品,不但成本高,而且工作量也太大了。
另外,如果监控告警平台集成程度不高,导致信息孤岛的出现,造成错误报警,阻碍故障排除,就会增加系统的平均修复时间( MTTR )。所以你需要找到一个能够监控所有应用的方法,这样才能快速找到问题的根源,而云智慧监控宝能够能够通过 API 对接各种 IT 系统平台,就是一个不错的集中告警选择。
技巧 8 :让每个人都能及时了解系统状况
在这个用户满意度至上的时代,你需要不断证明、展示自己的服务质量( SLA ),所以要主动定期向用户报告 IT 系统的 SLA 。你可以提供一个只展示重点信息的概要报告,这样他们无需花大量时间去研究冗长繁杂的报告。另外,因为用户满意度是衡量 IT 成功(也是你的成功)与否的标准,所以它也可以用来衡量 IT 为公司带来了多少价值。
技巧 9 :定期进行系统状态的对比
我们总希望 IT 系统的性能越来越好,那么在不断的系统调优过程中,不但要进行调优前后的性能对比,还要和一段时间内的整体业务状况进行对比,只有这样才能准确判断系统对业务的影响,为下一步行动提供指导。例如,快速确定是否需要将重点放在性能优化上,是否需要更改云服务供应商等等。
技巧 10: 保证质量
要尽早树立注重应用产品质量的理念,虽然现在的产品迭代速度越来越快,但在所有的程序研发 /程序执行过程测试是不容忽视的(包括功能测试、回归测试、性能测试、压力测试等),这样才能保证程序质量,如果能够将测试脚本复用到产品上线之后的监控过程,并把线上数据反馈给开发和测试,不但有助于简化运维的工作流程,同时能提升开发和测试的效率和数据准确性。
总之,终端用户体验决定了对应用速度、可用性和性能状况满意是否,所以需要从用户的视角去执行、测试和监控你的应用。同时更不要忘记移动用户,智能手机不仅逐步取代电脑在我们生活和工作中的地位,而且它们完全改变了应用的体验。事实上,用户在移动设备上所花的时间已经大大超过了电脑,同时移动用户对性能和用户体验的期望也更加苛刻。因此,你需要寻找同时适合移动用户和电脑用户的监控解决方案,云智慧监控宝、透视宝和压测宝三款产品可以满足用户对移动端、 Web 端、网络、服务端全部技术栈从测试到线上产品性能监控告警和深层性能瓶颈分析发现的全部需求,而且三者在从底层架构和数据流上是完全打通的,确保应用性能监控的及时性和准确性。
编译:云智慧
作者: Jay Labadini
原文链接: http://www.apmdigest.com/10-application-monitoring-tips
]]>这些地区有业务的小伙伴不要错过哦,可以用监控宝实时关注这些地区用户访问公司业务的性能情况。
监控宝监测网络遍布全球,监测频率高达1分钟,覆盖全国所有省份和运营商,实现高效能网站持续监测,帮助您了解世界各地真实用户访问网站的情况。
了解更多全球分布式监控节点,从这里进: http://www.jiankongbao.com/monitor
您还需要哪些地区的监控节点,也可以留言给我们哦~
]]>无压测,不狂欢。 云智慧压测宝助您决战 618 ,立即进行压力测试 http://yacebao.com/
云智慧压测宝,性能压力测试的必备工具,基于真实业务场景与用户行为的云端压力测试。只需 3 步 6 分钟,即可发起百万并发访问,实现对全链路和全业务的压力测试。
6 分钟 即可发起百万并发
全球多达 200+城市持续并发 任意位置浏览器创建并控制测试 洞察生产环境高并发下的性能表现 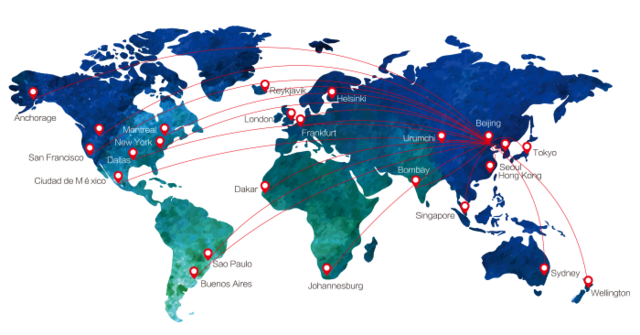
只需三步 从准备到获得数据
准备测试脚本,确认压测目标 设置测试时间、并发量等任务 得到测试结果,实时查看数据 
压测监控大屏掌控全局状况
自定义数据分析面板 全自动关联分析多项指标 实时数据分析,发现性能瓶颈 
颠覆传统压测理念

决战 618 立即进行压力测试 http://yacebao.com/
]]>http://233.dog/f_83289794.png
http://233.dog/f_82133483.png ]]>

透视宝 Webview 性能分析是对 H5 页面性能的分析,包括页面加载性能分析和 Ajax 性能分析。新鲜出炉,免费体验中。 前往免费体验: www.toushibao.com
 图 1:透视宝 webview 的慢页面加载列表
图 1:透视宝 webview 的慢页面加载列表
 图 2 : H5 页面响应时间分解图
图 2 : H5 页面响应时间分解图
 图 3:透视宝 webview 页面加载资源时序图
图 3:透视宝 webview 页面加载资源时序图
前往免费体验: www.toushibao.com
]]>感觉现在的支付宝就像方校长, 被迫做数据的收集, 以后街上监视器一拍就知道户口, 或者听个留言就知道户口, 交际关系网络轻松获取, api 都做好了, 想想好可怕.
我是从澳大利亚区 AppStore 下的支付宝
IPA https://mega.nz/#!OoljEQhJ!i-46F7gcw9G2Crxvv2XuQV8z0v_Q_tPWlUAU4Rnfpok 
所以,他亲自用监控宝的 URL 回调功能实现了服务器宕机后的自动重启。
有时候一个不起眼的小功能,也会有意想不到的作用。希望他的分享,对大家有启发。
文章链接:
https://mp.weixin.qq.com/s?__biz=MzAwNzA0NTMzMQ==&mid=404303662&idx=1&sn=a1d16fa9f48f8b5d64f4ad3964c5a089&scene=1&srcid=0316ellwtnotC7rnhRo0gfsV&pass_ticket=VkDDLoW8wviL7ic2r8MlHpxONJvbDrtROwxUZ%2FrcnPVx2SfttebqRagY%2FMYE7bs6#rd ]]>
了解更多全球分布式监控节点,从这里进: http://www.jiankongbao.com/monitor
您还需要哪些地区的监控节点,也可以留言给我们哦~
]]>文轩在线的 IT 经理于湖,近期分享了他的业务运维心得,让 IT 部门成为企业的价值中心,希望对各位监控宝用户有所启发。 ]]>

2 、进入告警通知设置,选择你需要设置告警方式和联系人,点击应用设置。

3 、点击“批量应用到其他站点”,可将设置的告警方式应用到其他的监控项目。
 ]]>
]]>






















































































