
然后你创建一套 public key 和 private key
最多能每分钟 1000 次请求
这连 cloudflare workers 都免了
]]>但是…… datagrip 毕竟是收费的,如果没有公司支持,每年几百块的现金流也是一笔不小的压力。而且资源占用有点高,略显臃肿!
于是尝试寻找替代方案,如果有 ai 概念就更好了!
- 重回 navicat ,这么多年了,确实不错。但是用惯 ide 式的 client ,其实 sql 才是主角,感觉理念有点落伍了。只能说能用了!
- 尝试在 vs code/idea community 安装 db client 插件。比如 vscode 的 sql tools ,可以管理数据库连接,发起查询,但是可视化编辑几乎没有。勉强够用!
- beekeeper studio -- 又收费又不太好用!
你们呢?用什么数据库客户端/插件?
]]>


如上所示,指标单独查询是有数据,但是放在 dashbord 中就是显示为空,这种是什么原因,要怎么排查?
]]>之前我问了个问题: t/1173631 。就一个回复,而且还那么多点击,感觉应该是不太行了。所以打算自己测试了。
]]>为了防止出现 XY 问题,先说一下目标。要是有人感觉我的解决方案不对,可以指出来。
我并不是为了给内容添加标签,而是为了用标签这个技术实现用很多现象(就是一段描述性的没有主语的话,主语就是用户,比如喜欢猫,大五开放性为很高等)来尽量详尽地描述一个人,以更好地实现个性化推荐。现象一般都是用户自己给自己添加的。不过我设想的网站更有特色的地方是推荐方法,而不是一般的推荐内容,虽然也能推荐内容。我假设不同方法依赖的特征可能是有限的,所以至少在知道方法依赖的特征的时候不需要匹配非常多的标签。
类比标签系统中的内容,我设想的系统中有现象箱子的概念。将不同现象放到不同现象箱子中主要是为了方便管理和搜索。比如上一段提到的有助于推荐方法的现象主要放到“我的个人成长现象箱子”中。而有助于推荐 ACG 音乐的现象放到“我喜欢的 ACG 音乐有序列表”中。这二者都保存到一个数据库表中。表模式:(主键,现象箱子 ID ,现象 ID ),然后在(现象 ID ,现象箱子 ID )上建立复合索引。
如果现象箱子的现象最大数量比较小的话,那么相关的现象就必须放到不同的现象箱子中。这样的话搜索的时候会相当麻烦,不光我写代码麻烦,用户理解起来可能也会更麻烦。如果不同的现象箱子有相同的现象的话,维护一致性也是个问题。
我估计一般不会所有人都会在现象箱子中添加三万的现象,至少初期应该不会。
基本可以确定是用 PostgreSQL 实现。
具体搜索方式
我计划一次只搜索五个现象以下可以立即返回结果。至于更多的,则需要排队,在半夜没人的时候集中批量搜索。大概最多不可以超过一百个现象。
还有搜索的时候我会对标签进行或组合,我记得 DeepSeek 好像说过或比与更耗时。就是搜索设置了现象 1 或现象 2 或现象 3 的用户。与组合也会用,还有与和或组合。
为什么不自己去测试性能
我自己试过,好像一万个标签性能也没差到哪去,对我来说可以接受。但是我不知道这里还会有什么其他的问题。要是没人理我我只能自己去测试了。还有自己测试太费劲了。
通过推理来证明我也基本能接受
比如既然 ElasticSearch 能做到,规模大了之后应该也不会是问题吧?不过我问了一下 DeepSeek ,它说 ElasticSearch 对文章长度很长的数据集索引和搜索效率都会降低,最好是拆分成小文档。当然最好还是有谁实际搞过,没遇到什么大问题。
我知道的实现我的目标的据说更好的实现方法
向量数据库。这个应该是需要选出一个子集,因为动态添加维度好像不容易。
位图索引数据库。好像也要选出一个子集,也是因为好像动态添加列不方便。
ElasticSearch 。吃内存。据说至少要 4 GB 到 8 GB 的内存。我初期估计也就能用个 2 GB 到 4 GB 的服务器。
为什么是三万
这节很玄乎,没坚实的根据,没兴趣别看。
我搜过基因最多的生物,其基因大概是三万左右。另外 DeepSeek 说一个复杂系统的子系统的类型的数量一般是存在最优值的,更多更少可能都会降低适应性。然后我感觉三万没准是子系统类型的上限。很二的逻辑是吧?我也感觉很二。我其实也想过怎么才能把现象盒子分层,不过没什么比较好的点子。目前感觉还凑合的方法是将现象箱子相互关联起来。搜索的时候会自动探索相关的现象箱子。不过实现起来没什么头绪。还有就是按身份、目标、难以改变的现象、容易改变的现象给现象箱子分类,并通过这个优化搜索。但是实现还是很麻烦。如果三万没什么特别大的问题我还是想以后再优化。初期先凑合着,反正我设想的这个网站也不一定真有用。
]]>理由无非是覆盖索引、占用网络带宽、性能问题……
随着时代的发展,我感觉这个没有绝对,其实很多情况使用 select * 完全没问题,很多时候 select * 和 select 字段带来的性能差距还不如做其他优化来的实在
除非是少数情况,比如 blob 、text 等大字段或者一张表有 100 多个字段……
我见过有人吐槽新入职的同事把 select * 当圣经,一张配置表,总共就 100 多条数据,所以就用了 select * ,然后这个新同事指出不应该这么用,理由是会影响性能……
]]>我觉得阿里有这样的规范应该是考虑到服务多,分库分表下外键基本上不可用了,但是当涉及体量不大,即使是多服务,但是也没有到分库分表的情况,那这种情况下我觉得使用外键还是不错的,当删除和更新是就不需要开发人员去考虑写逻辑,只要前期表设计的合理,这些容易让开发人员忽略的事情就可以交给数据库去做了。
我最近在做自己的一个小项目,我开始从头捡起了多年未使用的外键,因为我不需要考虑分表,这种情况下写代码真的省心好多,以前在写删除或者更新的时候还得自己考虑到位,保证不出现 “孤儿数据”,现在根本不需要。
不知道大家平时会给自己的项目使用外键吗?如果不使用是为什么?如果使用了你觉得带来的开发收益大不大?
]]>我是个后端,线上经常遇到慢查询,但一直找不到特别满意的工具来排查。 自己用 pt-query-digest 吧,功能强是强,但总觉得不够方便直观,不能持续监控。 云厂商 RDS 自带的监控是好用,但咱自建的数据库用不了啊。 其他一些开源工具,要么安装配置太复杂,恨不得装一卡车依赖;要么就得在 DB 服务器上装 Agent ,心里不踏实。 被逼无奈,就断断续续抽了几个月的业余时间,自己撸了一个轻量级的监控工具 我主要想解决这么几个点:
无 Agent ,开箱即用:
不用在目标服务器装任何东西,下载解压,一条命令就能跑起来。 慢查询 AI 分析:
这是花心思最多的,把慢查询 SQL 扔给 AI ,让它直接生成优化建议,对我们这种非专业 DBA 的开发比较友好。 数据在自己手里:
所有数据都存在本地,不往外发。 现在基础功能算是做完了,比如仪表盘、慢查询列表和趋势图、飞书/钉钉告警啥的。 但现实挺打击人的,发布后基本没啥人用,现在陷入深度自我怀疑: 是不是这个需求其实很小众?大家都没这个痛点? 还是我做的这东西实在太垃圾了,根本没法用? 或者是解决问题的思路完全错了?
详细使用文档
这里是演示地址(就是个只读的 Demo ):
这是几张核心功能的截图,劳驾帮忙瞅瞅:
http://db-pulse.top/docs/images/slow-list.png
{kind=link}
http://db-pulse.top/docs/images/slow-chart.png
{kind=link}
http://db-pulse.top/docs/images/slow-analyze.png
{kind=link}
就想听听真实的反馈:
这工具到底有没有一丁点价值?如果是你,在什么场景下会考虑用?或者它到底垃圾在哪儿? 任何建议、吐槽都行,提前感谢!
]]>- MySQL
- PostgreSQL
- MongoDB
- Redis
之前我是一直在用 DBeaver 、RedisManager 、和 MongoDB Compass ,最近转用 JetBrains 旗下的 DataGrip ,因为它对非商业免费了,对于个人项目来说使用它感觉很不错。因为它可以满足我同时管理上面的这几类数据库。
大家平时喜欢用什么数据库管理工具?
]]>举个例子,描述一个长方体需要长宽高三个字段,表单里填了 长方体=>长:123 宽 234 高 345, 三角形=>第一个角 30 第二个角 40 第三个角 110 ,一次性提交表单后,表格会显示两条数据,但这两条数据属于一次填写
| 类型 | 值 | 时间 |
|---|---|---|
| 长方形 | 长 123 宽 234 高 345 | 2025-10-11 11:11:11 |
| 三角形 | 30° 40° 110° | 2025-10-11 11:11:11 |
我的想法是建一张宽表,包含所有维度的数据的字段(固定的),然后有一张字段映射表,配置宽表的哪些字段要组成独立的数据,新增完宽表记录后通过这张映射表,生成对应维度的一个数据,这种设计是否合理呢
]]>CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB; 这样的数据库表结构,查询城市是“杭州”的所有人名字,并且按照姓名排序返回前 1000 个人的姓名、年龄 的语句是 select city,name,age from t where city='杭州' order by name limit 1000 ;
后面讲到数据库会执行全字段排序或者rowid 排序来返回结果。
并且文章还讲了一个优化,使用联合索引来优化查询: alter table t add index city_user(city, name);,这样索引中 name 本身就是排序好的,数据库不需要再次执行排序工作,这对查询的性能来讲,可以增加不少。最后还讲到了覆盖索引继续优化一下这个场景: alter table t add index city_user_age(city, name, age);,这样数据库查询出来的结果包含所有的字段,也就是结果集就是我们要的最终结果,不需要往主键索引表中查询了。
我是个后端新手,比较好奇这种优化,小公司用到过吗?我不清楚这是后端的基本能力还是 DBA 专业数据库工作者才需要掌握的优化技能。
]]>谢谢 ]]>
暂时考虑使用分片,按{tenant_id, form_id}进行分片;
某个动态字段也可能是一个表单 json 应该把动态字段放到一个 json 中,像
{ "tenant_id": 1, "form_id": 1, "data": { "f1": "f1", "f2": "f2", "f3": { "f3-1": "f3-1" } } } 还是动态字段就和 tenant_id 并列在顶级,像
{ "tenant_id": 1, "form_id": 1, "f1": "f1", "f2": "f2", "f3": { "f3-1": "f3-1" } } 哪种设计方案比较好?
]]>我个人的观点一直是:postgres 的各种丰富功能,对于中小数据规模的业务非常好用,OLAP 非常便利,中小数据规模也没性能瓶颈,而数据量大的 OLAP 功能用传统关系型数据库都是无法满足的,都需要 streaming 、map/reduce 之类的大数据基础设施以及实施、离线计算分离才是正解。而一旦排除 OLAP 的便利性之后,postgres 相对于 mysql 并没有优势。
大陆之外的国家和地区的非 Top 数据量计的业务,人口基数和数据量没那么大,这是 postgres 在大陆之外越来越流行的非常重要的原因之一。
非引战,如果是我个人项目,数据量不大,我也乐于使用 postgres 。但是以往一些 postgres 教徒的观点太幼稚了。 恰好看到 uber 的这个 blog ,拿来背书,所以引来说几句公平话。
]]>- 日志最好能留够 1 年。
- 偶尔要查问题,用 SQL 能直接捞出来就行。
- 不想自己搭 ES/数仓,成本太高、维护也麻烦。
之前看过对象存储 + Presto(Trino) 这套,但有点懒得自己搭建和维护,感觉太折腾。 大家平时是怎么搞的?有没有省心点的办法?
]]>有什么更好的推荐么?好在哪里,对比怎么样?
]]>因此在这段时间内,这个 PoC 项目发生了如下的变化:
- VictoriaLogs 从 VictoriaMetrics 项目分离。而我们的 Traces 解决方案,作为 VictoriaLogs 的一个下游分支,也拥有了属于它的新名字和仓库:VictoriaTraces。
- 完善查询场景的性能测试和优化,发布了第一个版本 v0.1.0。
同时,我们还收到了很多用户关于查询性能的疑问,因为在上一篇博客中,查询性能只被简单地提及过 —— 是的,那是一轮不够严谨的测试。我们通过简单观察不同 Traces 后端的响应速度,得出 VictoriaLogs 的查询性能不逊色于竞争对手,这当然没有说服力。
所以,这篇博客中,让我们一起来探索一下 Traces 在不同的后端中是如何查询的。
Traces 的典型查询场景
回想一下,开发者们是如何使用 Traces 的:
- 有人向你报告了一个 Bug 以及对应的 TraceID ,然后你打开 Traces 平台,通过 TraceID 查询 Trace。
- 有人向你报告系统变慢了,但不知道原因。你打开 Traces 平台,搜索一段时间内所有耗时超过 3000ms ,或者包含错误的 Traces。
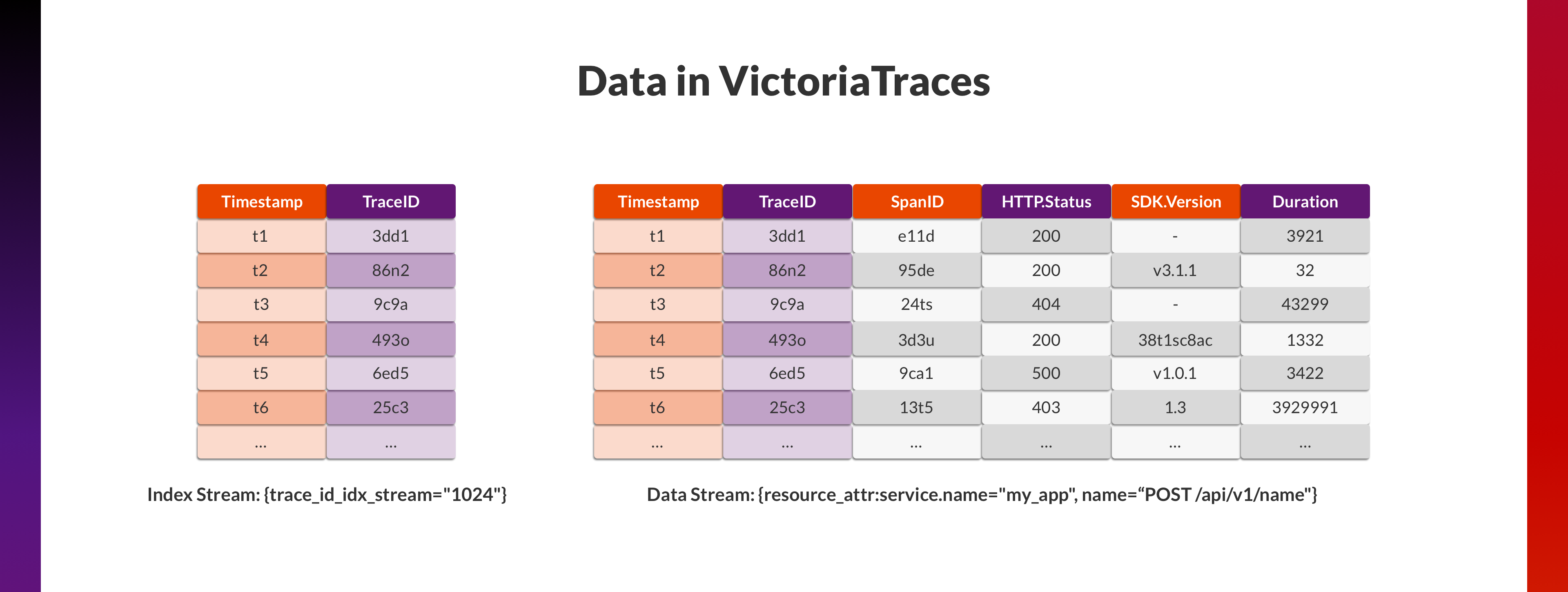
这是 Traces 中两个最常见的查询场景,那么数据 Schema 的设计就应该围绕着它们进行。
想要加速 TraceID 的查询,那数据就应该按照 TraceID 进行排列,而其余数据可以分多列存储,也可以编码成 Binary 或者 JSON 存入一列。另一方面,想要在时间范围内按照 Span 的 Attributes (如耗时、状态)进行查询,那这些数据应该按时间排序,并且相关 Attributes 就应该作为单独的列,提供检索的能力。
不同 Traces 后端的优化倾向
如果我们观察 VictoriaTraces 和其他 Traces 后端的 Schema ,可以看出来它们的优化倾向各不相同。
Jaeger
ClickHouse 是多个 Traces 后端都选用的存储方案。在 Jaeger 的设计中,ClickHouse 有两个关键的表:
<details>CREATE TABLE spans_table ( `timestamp` DateTime CODEC(Delta, ZSTD(1)), `traceID` String CODEC(ZSTD(1)), `model` String CODEC(ZSTD(3)) ) ENGINE = MergeTree PARTITION BY toDate(timestamp) ORDER BY traceID SETTINGS index_granularity = 1024; CREATE TABLE spans_index_table ( `timestamp` DateTime CODEC(Delta, ZSTD(1)), `traceID` String CODEC(ZSTD(1)), `service` LowCardinality(String) CODEC(ZSTD(1)), `operation` LowCardinality(String) CODEC(ZSTD(1)), `durationUs` UInt64 CODEC(ZSTD(1)), `tags` Nested(key LowCardinality(String), value String) CODEC(ZSTD(1)), INDEX idx_tag_keys tags.key TYPE bloom_filter(0.01) GRANULARITY 64, INDEX idx_duration durationUs TYPE minmax GRANULARITY 1 ) ENGINE = MergeTree PARTITION BY toDate(timestamp) ORDER BY (service, -toUnixTimestamp(timestamp)) SETTINGS index_granularity = 1024; 很显然,这是针对 TraceID 查询优化的,在 spans_table 中,数据按日分区,按 TraceID 排序,因此通过 TraceID 可以快速取出数个连续的 Spans 。而通过 TraceID 外的条件查询数据时,先在 spans_index_table 中找到 TraceID ,再回到 spans_table 中取出完整数据。
ClickStack ( ClickHouse )
作为 ClickHouse 的亲儿子,ClickStack 的 Schema 完全按照 OpenTelemetry 定义,让每个属性都拥有对应的字段:
<details>CREATE TABLE otel_traces ( `Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)), `TraceId` String CODEC(ZSTD(1)), `SpanId` String CODEC(ZSTD(1)), `ParentSpanId` String CODEC(ZSTD(1)), `TraceState` String CODEC(ZSTD(1)), `SpanName` LowCardinality(String) CODEC(ZSTD(1)), `SpanKind` LowCardinality(String) CODEC(ZSTD(1)), `ServiceName` LowCardinality(String) CODEC(ZSTD(1)), `ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `ScopeName` String CODEC(ZSTD(1)), `ScopeVersion` String CODEC(ZSTD(1)), `SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `Duration` Int64 CODEC(ZSTD(1)), `StatusCode` LowCardinality(String) CODEC(ZSTD(1)), `StatusMessage` String CODEC(ZSTD(1)), `Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)), `Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)), `Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)), `Links.TraceId` Array(String) CODEC(ZSTD(1)), `Links.SpanId` Array(String) CODEC(ZSTD(1)), `Links.TraceState` Array(String) CODEC(ZSTD(1)), `Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)), INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1, INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1, INDEX idx_duration Duration TYPE minmax GRANULARITY 1 ) ENGINE = MergeTree PARTITION BY toDate(Timestamp) ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId); 如果需要按照 TraceID 查询怎么办呢?是不是要在所有 Partition 中都找一遍?显然太低效了。因此,ClickStack 还会将每个 Span 的时间记录到 otel_traces_trace_id_ts 表,并且创建物化视图,这样,每个 TraceID 的起始和结束时间就很容易确定了,有效加速了以 TraceID 在 otel_traces 表的查询速度。
CREATE TABLE otel_traces_trace_id_ts ( `TraceId` String CODEC(ZSTD(1)), `Start` DateTime64(9) CODEC(Delta(8), ZSTD(1)), `End` DateTime64(9) CODEC(Delta(8), ZSTD(1)), INDEX idx_trace_id TraceId TYPE bloom_filter(0.01) GRANULARITY 1 ) ENGINE = MergeTree ORDER BY (TraceId, toUnixTimestamp(Start)); CREATE MATERIALIZED VIEW otel_traces_trace_id_ts_mv TO otel_traces_trace_id_ts ( `TraceId` String, `Start` DateTime64(9), `End` DateTime64(9) ) AS SELECT TraceId, min(Timestamp) AS Start, max(Timestamp) AS End FROM otel_traces WHERE TraceId != '' GROUP BY TraceId; VictoriaTraces
VictoriaTraces 目前的设计近似于 ClickStack ,在上一篇博客中提到过,尽可能将所有 Attributes 平铺为 Fields ,而 Fields 正接近于 Column-oriented 数据库中“列”的概念。
同样,单纯这样的设计并不能应对 TraceID 查询的场景,因此,我们又增加了一个单独的 Index Stream ,VictoriaTraces 在遇见每个新的 TraceID 的时,都会在这个 Stream 中增加一条记录 (Timestamp, TraceID)。这个 Stream 非常小,行数为 Trace 的总量,因此在这个 Stream 中按照 TraceID 查询会很快。在找到 TraceID 对应的 Timestamp 后,以此为中心,在各个 Stream 中查询 ±45 秒内的数据,获取 TraceID 对应的所有 Spans 。
这个设计只是作为加速 TraceID 查询的概念验证,它有很多显而易见的缺点:
- Index Stream 数据按照时间排序,因此按 TraceID 的查询是遍历而二分查找,效率不高。
- TraceID 的起始结束时间是不确定的,查询 90 秒的数据既可能浪费(如 Trace 耗时仅为 1 秒),也可能不足(如 Trace 跨越数分钟)。
不过,聪明的读者一定也知道所有的设计都有其长处和短板,问题在于是否值得:
- 用更多的空间换更快的时间。
- 用更昂贵的写入换更快的查询。
我们一定会在后续版本保持探索,调整这些设计,将它变得更加适合不同的使用场景。不过在那之前,不如先回到今天的主题——它们到底查询性能如何?
查询性能对比
改良 Traces 数据生成
为了生成大量更贴合生产环境的测试数据,我们一开始打算部署多个 OpenTelemetry Demo。该 Demo 是基于 14 个微服务的分布式系统,覆盖了不同的编程语言、不同的插桩方式,产生的数据比过往使用的 Jaeger tracegen 更具有代表性。
但是在运行一段时间后,我们发现 OpenTelemetry Demo 需要消耗较多的资源,并且产生的压力有限。因此,我们又基于流量录制回放的思路编写了 vtgen,它可以:
- 反复发送预先录制好的 OpenTelemetry Demo 的 Trace 请求到多个 OTLP HTTP Endpoints ,这些 Trace 请求中 TraceID 和部分字段会被按需修改。
- 记录 HTTP 请求耗时指标。
vtgen 既可以用于 Traces 后端的写入性能 Benchmark ,也可以为不同 Traces 后端写入完全一致的数据,并随机记录一定量的 TraceID ,用于查询性能 Benchmark 。
Benchmark 设计
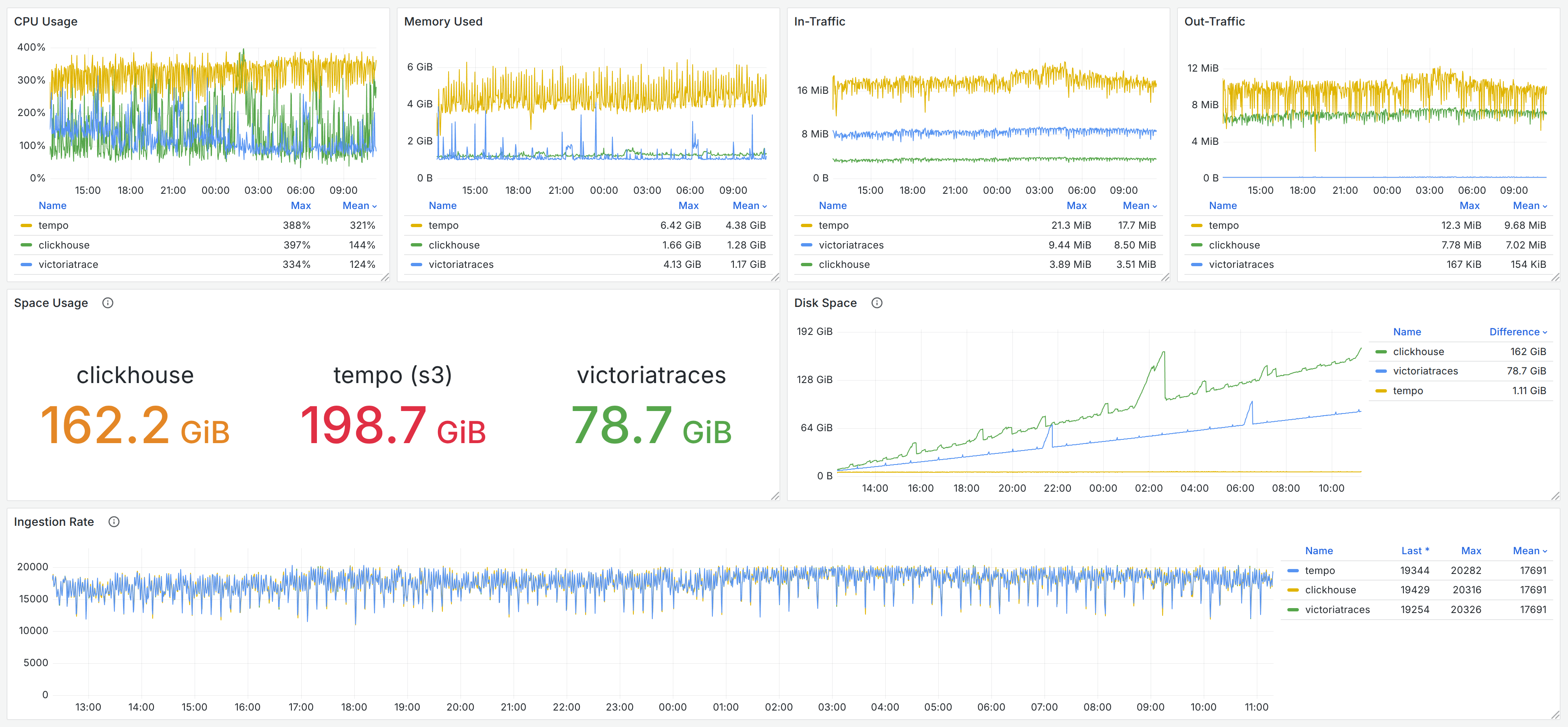
我们在对 VictoriaTraces 的 Benchmark 中仍然选用了 Grafana Tempo 及 Jaeger & ClickHouse 作为对比,写入相同的的数据,其中数据写入过程的监控监控记录如下图,读者也可以在 Grafana Dashboard 快照中查阅。
我们在第一节中介绍过,最常见的 Traces 查询场景包括:
- 根据 TraceID 查询。
- 根据属性在特定时间段内搜索出多个 Traces 。
因此对应地:
- 通过 vtgen 在 Ingestion 过程中记录下 63000 个 TraceID ,逐一向 3 个 Traces 后端进行请求。
- 手动构造 15 组 Traces 属性查询的参数模板,以及 50 个时长为 10-60 分钟的时间段,逐一向 VictoriaTraces 和 Jaeger 进行共计 750 次请求。
{{<admonition type=note title="为什么属性搜索对比中没有 Tempo ?">}}
VictoriaTraces 、ClickHouse 均可以支持 Jaeger 的 Search API ,而 Tempo 同样提供 Search API ,但是两个 Search APIs 的返回数据格式并不一致:
- Jaeger 的 Search API 需要提供完整的 Traces 数据,包含所有 Spans 。换句话说,Jaeger 的 Search API 就是 List 版本的 Trace API 。
- Tempo 的 Search API 只需返回 Traces 的部分数据,因而无需额外查找每个 Trace 的其余 Spans 。
因此,它们无法直接对比查询性能。
不过,Tempo 的 Search API 设计实际上更简洁高效,所以,我们会在 VictoriaTraces 实现 Tempo API 后将其进行补充对比。
{{< /admonition >}}
结果
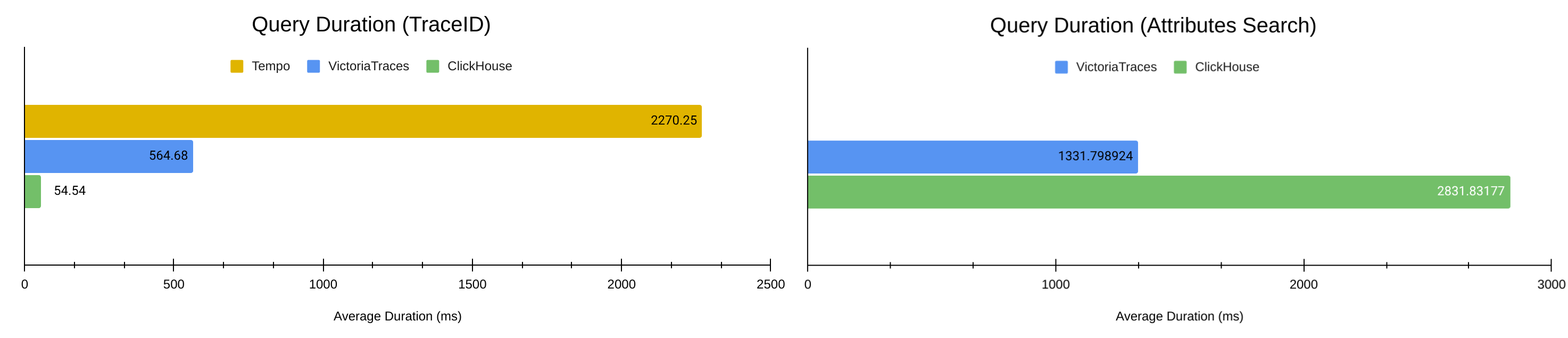
通过上面的图表,我们可以看到 VictoriaTraces 相比一些主流 Traces 后端的性能如何。
与 Jaeger & ClickHouse 的组合相比,如第二节中所分析,因为它们的查询优化方向不同,所以在两种场景中的表现互有胜负。ClickHouse 使用了 2 倍于 VictoriaTraces 的存储空间( 162 GiB vs. 79 GiB )来换取根据 TraceID 查询的速度,舍弃了在 Traces Search 场景的性能。
VictoriaTraces 的未来
通过这些测试,我们已经知道 VictoriaTraces 与不同竞品的差异 —— 既有设计上的原因,也有优化上的不足。我们当然需要继续迭代 VictoriaTraces ,希望它能够更早抵达稳定版本。
所以,在性能上:
- VictoriaTraces 的底层数据结构将与 VictoriaLogs 进一步分叉,让 Traces 场景得到更多的关爱。引入更合适的 IndexDB 和 Cache 来优化数据写入和查询。
- Profiling 结果显示,VictoriaTraces 还有很多糟糕的代码,它还有很大的进步空间。
同时,在功能上,我们希望:
- 提供 Tempo HTTP APIs ,这允许用户更灵活地查询 Traces 数据。
- 完善 Kubernetes 支持,提供 Operator 和 Helm Chart 。
- 完善 Cluster 版本的设计。
期待能在博客评论区或 VictoriaTraces 的 Issues 中收到你的反馈,也期待与你在下一期开发者笔记中再会!
]]>2. 由于个人能力比较差,混着写,阅读都比较困难,有没有什么数据库可以直接用 python 语法使用?
3. 稳定性方面,暂时跑在 wsl 里面(我的错),无法写入,更新,卡死的次数经常出现
要用到数据库的原因在于现在跑通之后会进入多人协作的情况,有一个数据库在中间能减少很多麻烦跟文件传输方面的事情。不会涉及生成模型,短时间会保持结构化数据,但是将来可能会储存图片。
求大佬们指教,非常感谢 ]]>
想要完全本地操作 不想上传到云端再让别人转换
]]>规则编写想用 drools ,现在遇到了数据读取大的问题,需不需要上 hadoop 全家桶?还是简单一点,spark➕HDFS 、Hive➕drools 。对大数据了解不多,请大大们提提建议
]]>
基于 pebble kv 数据库,研发了针对于 IM 这种服务的特有分布式数据库,省了其他数据库为了通用性而带来的性能损耗, 因为存储快,所以消息快。
``` ]]>
111
222
333
然后我想去 b 库的表里查,那我 sql 应该是 select * from b where name in ('111','222','333')
就是把
111
222
333
转化成 '111','222','333'
写了个工具就是做了这个转换,大家有同样需求的可以拿来用,或者大家有没有别的办法来解决这个问题
https://www.joinlines.org/ ]]>
目前开发一个医院项目,必须要求信创名单的数据库;
目前我们用的是 MYSQL ,求推荐一个改造最小的平替;
看了达梦,但是没看出来是怎么收费的
有没有相同需求的老哥 最后是怎么做的?
]]>最好满足下面的要求:
- B/S 架构
- 支持数据结构转换
- 支持对比逻辑,并生成对比结果报表
- 支持定时作业
SELECT FIELDS FROM A LEFT JOIN B ON A.a=B.b WHERE A.w="" AND A.time>? A 表在 time 上有索引,B 表在 b 上有索引
在我开发环境的 MySQL 中,explain 看上去一切正常
A range time B ref idx_b 但是到了线上的 TIDB 中,就变成了
IndexRangeScan_101(Build) table:A ,index:idx_time(time) TableFullScan_114 table:B keep order:false 主要的问题是,B 变成了全表扫描,完全无法接受。
如果像 MySQL 正常索引,A 表过滤后的数据量只有几千条。 改了 USE INDEX 以后,变成了索引全扫描?情况也没好到哪里去... Analyze Table 的命令也执行过了,还是没变化
IndexRangeScan_101(Build) table:A ,index:idx_time(time) IndexFullScan table:B, index:idx_b(b) keep order:false 最后就是一句话,就是这个东西碰不得,是邪教。
存储过程这个东西存在这么久,不可能一无是处吧
有没有可能,像 TypeScript 转译为 Javascript 一样,有一种高级语言可以:
-
编译成各类数据库支持的 SQL (比如 PostgreSQL 、SQL Server 等);
-
根据目标数据库的特性自动优化生成对应代码;
-
如果使用了目标数据库不支持的语法,比如在目标是 PostgreSQL 时用到了 SQL Server 的专有语法,那么编译器应能直接报错并给出明确提示;
最好还能在开发阶段提供类型检查、智能提示和跨平台兼容性检查。
求,求索,探求; 兮,通“析”。
这个名称如何?各位给点建议
]]>function processBatch(): tx = db.beginTransaction() // 1. 批量读取:取出最多 N 条“待处理”数据 items = tx.query("SELECT * FROM tasks WHERE status = 'PENDING' LIMIT N") for item in items: // 2. 业务处理 doBusinessLogic(item) // 3. 更新状态 tx.execute("UPDATE tasks SET status = 'DONE' WHERE id = ?", item.id) tx.commit() // 线程 A spawn threadA: processBatch() // 线程 B (几乎同时执行) spawn threadB: processBatch() 但由于 processBatch 在多个地方都会被调用,因此存在并发问题。线程 A 和线程 B 执行时可能查询到同一批数据,导致这批数据被处理两次。解决这个问题有两个方案:
- 方案 A:在 processBatch 的逻辑中增加锁,这样在任意时刻,该函数都不会并发执行
- 方案 B:调整数据库事务的隔离级别或锁表,即使 processBatch 并发执行了,底层的数据操作不会出现并发的情况
我的问题是:
- 哪个方案更符合最佳实践?原因是什么
- 在保持 processBatch 会被多个地方调用不变的前提下,有没有更好的方案?
- 如果想学习这类并发相关的问题和解决方案,应该搜索什么关键词
感谢各位赐教
]]>事件经过:昨天同事误操作右键删除了 SqlServer 中的开发数据库,无备份。mdf 文件超过 10G 。发现之后第一时间把这台虚拟机关机了。
恢复过程:
- 先使用
DiskGenius挂载 vhdx 尝试恢复,未找到被删除的 mdf 及 ldf 文件。 - 使用宿主机磁盘管理挂载 vhdx ,用
easyrecovery尝试恢复,选择分区,勾选深度扫描,在指定分区未找到被删除文件。 - 继续使用
easyrecovery扫描整个 vhdx 磁盘,目前正在跑。
请问大家有没有类似经历,求方案,先谢各位大佬了
]]>除了给电脑加内存条还有别的办法吗。。
需要把 raw data 直接给到业务部门,他们自己要各种维度的分析 ]]>
- array 数组类型建立倒排索引不支持分词器,只能精确匹配,要模糊匹配,只能新增一个 string 字段,拼接起来然后做倒排索引,配置分词器
- array 数组类型不支持修改字段长度,只能新增一个字段。
- variant 可变类型不能存 对象数组,会将同字段数据合并,失去原数据结构
- variant 可变类型存 json 数据如果层级超过两层,会用 jsonb 格式存储,查询性能非常差(一多维的 json 格式数据应该很常见吧)。
- variant 官方文档上的函数 explode_variant_array ,有可能会导致集群挂掉,需要重启。
- json 暂不支持 倒排索引 (这个文档倒是说了,但是我们也是刚需,没办法) 6 array<struct> 倒排索引不支持分词器
想问问你们项目使用 selectDB 的真实体验如何。
]]>